

بررسی جامع مدل هوش مصنوعی Gemma 4 گوگل؛ جهش بزرگ در پردازش چندوجهی و مدلهای متنباز
جدول محتواها
کلمات کلیدی سئو: مدل هوش مصنوعی Gemma 4، گوگل دیپمایند (Google DeepMind)، رسانه هوش مصنوعی سیمرغ، مدل متنباز (Open-Weights)، هوش مصنوعی چندوجهی، پردازش زبان طبیعی، معماری Mixture-of-Experts، استدلال هوش مصنوعی، راهنمای توسعهدهندگان هوش مصنوعی.
به گزارش رسانه تخصصی هوش مصنوعی سیمرغ، دنیای هوش مصنوعی متنباز (Open-Source/Open-Weights) با معرفی نسل چهارم مدلهای زاینده گوگل، یعنی خانواده Gemma 4، وارد عصر جدیدی شده است. مدلهای جمما (Gemma) که نام خود را از واژهای لاتین به معنای «سنگ قیمتی» وام گرفتهاند، بر پایه همان تحقیقات، فناوریها و زیرساختهای پیشرفتهای ساخته شدهاند که پیشتر برای توسعه مدلهای پرچمدار و قدرتمند جمنای (Gemini) به کار گرفته شده بود.
گوگل دیپمایند (Google DeepMind) با انتشار خانواده Gemma 4 در تاریخ ۳۱ مارس ۲۰۲۶، مرزهای پردازش ابری و محلی را جابهجا کرده است. این مدلها به گونهای طراحی شدهاند که ضمن ارائه عملکردی در سطح برترین مدلهای جهان (State-of-the-art)، امکان نوآوری، همکاری و استفاده مسئولانه از هوش مصنوعی را برای توسعهدهندگان، پژوهشگران و کسبوکارها فراهم کنند. در این مقاله جامع از سیمرغ، به کالبدشکافی کامل معماری، قابلیتها، بنچمارکها، نیازمندیهای سختافزاری و راهنمای پیادهسازی مدلهای Gemma 4 میپردازیم.
بخش اول: اکوسیستم Gemma و نگاهی به تاریخچه تکامل
مدلهای Gemma تنها یک محصول واحد نیستند، بلکه یک اکوسیستم رو به رشد از مدلهای بهینهشده برای وظایف مختلف را تشکیل میدهند. این خانواده شامل نسخههای متنوعی برای کاربردهای عمومی و تخصصی است:
- مدل اصلی Gemma 4: برای حل طیف گستردهای از وظایف هوش مصنوعی زاینده با ورودیهای متن، صدا، تصویر و ویدیو.
- مدل EmbeddingGemma: مدلی تخصصی برای تولید بازنماییهای عددی (Vector Embeddings) از متن که برای وظایفی مانند بازیابی اطلاعات (RAG)، جستجوی معنایی و خوشهبندی استفاده میشود.
- مدل ShieldGemma 2: یک سیستم امنیتی پیشرفته برای ارزیابی ایمنی ورودیها و خروجیهای مدلهای زاینده بر اساس سیاستهای تعریفشده.

سیر تکامل و تقویم انتشار خانواده Gemma:
مرور تقویم انتشار مدلهای گوگل نشاندهنده سرعت خیرهکننده نوآوری در این شرکت است. از زمان انتشار اولیه Gemma در فوریه ۲۰۲۴، گوگل بیوقفه در حال بهینهسازی این خانواده بوده است. برخی از نقاط عطف مهم عبارتند از:
- فوریه ۲۰۲۴: معرفی اولین نسل Gemma در اندازههای 2B و 7B.
- ژوئن و جولای ۲۰۲۴: معرفی نسل دوم (Gemma 2) به همراه ابزارهایی مانند ShieldGemma.
- دسامبر ۲۰۲۴: معرفی PaliGemma 2 برای وظایف بصری.
- مارس تا آگوست ۲۰۲۵: انتشار موفقیتآمیز نسل سوم (Gemma 3) در اندازههای متنوع تا 27B و همچنین نسخههای پزشکی (MedGemma).
- ژانویه ۲۰۲۶: توسعه نسخههای تخصصی برای ترجمه (TranslateGemma).
- ۳۱ مارس ۲۰۲۶: رونمایی تاریخی از Gemma 4 در اندازههای E2B، E4B، 31B و مدل انقلابی 26B A4B.
بخش دوم: معماریهای اختصاصی؛ از لبه تا سرور ابری
خانواده مدلهای Gemma 4 شامل سه معماری متمایز است که هر کدام برای رفع محدودیتهای سختافزاری خاصی بهینهسازی شدهاند:
۱. مدلهای فوقسبک و کارآمد (E2B و E4B)
این مدلها که به ترتیب دارای ۲.۳ و ۴.۵ میلیارد پارامتر «موثر» هستند، به صورت اختصاصی برای استقرار در دستگاههای موبایل، پردازش لبه (Edge) و مرورگرها (مانند مرورگر کروم و گوشیهای پیکسل) طراحی شدهاند.
حرف “E” در نام این مدلها مخفف Effective (موثر) است. گوگل برای بهینهسازی این مدلها از تکنولوژی تعبیه در هر لایه (Per-Layer Embeddings – PLE) استفاده کرده است. در این روش، به جای اضافه کردن لایههای سنگین به مدل، یک جدول تعبیه (Embedding) کوچک به هر لایه دیکدر اختصاص مییابد. اگرچه با احتساب این جداول، حجم کل پارامترها به ۵.۱ و ۸ میلیارد میرسد، اما این جداول تنها برای جستجوی سریع استفاده میشوند و در نتیجه، پردازش روی گوشیهای موبایل بسیار سریع و کممصرف خواهد بود.
۲. معماری متراکم قدرتمند (31B Dense)
مدل ۳۱ میلیاردی جمما ۴، یک مدل متراکم (Dense) کلاسیک است که دارای ۶۰ لایه شبکه عصبی میباشد. این مدل شکاف بین مدلهای عظیم سرورمحور و مدلهای قابل اجرای محلی را پر میکند. با توانمندی بالا در استدلال، این نسخه برای پردازشهای سنگین تحقیقاتی و سازمانی مناسب است.
۳. شاهکار معماری: ترکیبی از خبرگان (26B A4B MoE)
مدل ۲۶ میلیاردی ترکیبی از خبرگان (Mixture-of-Experts) بدون شک ستاره این خانواده است. حرف “A” در این مدل به معنای Active (فعال) است. این مدل در مجموع ۲۵.۲ میلیارد پارامتر و ۱۲۸ کارشناس (Expert) مجزا دارد؛ اما نبوغ این معماری در این است که برای پردازش و تولید هر توکن، تنها حدود ۳.۸ میلیارد پارامتر (۸ کارشناس) را فعال میکند! این یعنی شما دقت و هوش یک مدل غولپیکر ۲۶ میلیاردی را با سرعت استنتاج (Inference) یک مدل ۴ میلیاردی در اختیار خواهید داشت.
مکانیسم توجه هیبریدی (Hybrid Attention):
یکی دیگر از نوآوریهای Gemma 4، استفاده از مکانیسم توجه ترکیبی است. این مدلها توجه محلی مبتنی بر پنجره لغزان (Sliding Window Attention) را با توجه سراسری (Global Attention) ترکیب میکنند. به این ترتیب، مدل میتواند بدون مصرف بیرویه حافظه رم، درک عمیقی از متنهای بسیار طولانی داشته باشد. همچنین از سیستمهای پیشرفتهای مانند p-RoPE برای مدیریت بهتر حافظه در متنهای بلند استفاده شده است.

بخش سوم: قابلیتهای جدید مدلهای Gemma 4
نسل چهارم جمما صرفاً یک ارتقای عددی نیست، بلکه مجموعهای از توانمندیهای جدید را به دنیای مدلهای متنباز معرفی کرده است:
۱. استدلال و تفکر عمیق (Reasoning):
تمامی مدلهای این خانواده به عنوان استدلالگرانی بسیار توانمند طراحی شدهاند. این مدلها دارای حالت «تفکر» (Thinking Mode) قابل تنظیم هستند. با فعال کردن این حالت، مدل پیش از تولید پاسخ نهایی، صورتمسئله را در لایههای پنهان خود حلاجی کرده و گامبهگام به راهحل میرسد (مشابه تفکر انسانی پیش از سخن گفتن).
۲. پشتیبانی چندوجهی گسترده (Extended Multimodalities):
Gemma 4 به معنای واقعی کلمه یک مدل Multimodal است. این مدلها از درک تصاویر با نسبتهای ابعاد و رزولوشنهای متغیر پشتیبانی میکنند. همچنین قادر به پردازش ویدیو (به صورت فریم به فریم) هستند. نقطه قوت مدلهای کوچکتر (E2B و E4B)، پشتیبانی بومی از درک صدا (Audio) است. این مدلها میتوانند تا ۳۰ ثانیه فایل صوتی را دریافت کرده، آن را به متن تبدیل کنند (ASR) یا مستقیماً ترجمه گفتار به متن (AST) انجام دهند. همچنین برای ویدیوها امکان پردازش تا ۶۰ ثانیه (با نرخ یک فریم بر ثانیه) وجود دارد.
۳. پنجره زمینه (Context Window) عظیم:
هرچه پنجره زمینه بزرگتر باشد، مدل میتواند تاریخچه بیشتری از مکالمه را به یاد بیاورد یا اسناد طولانیتری را یکجا بخواند. مدلهای E2B و E4B دارای پنجره زمینه ۱۲۸ هزار توکنی هستند، در حالی که مدلهای 31B و 26B از یک پنجره عظیم ۲۵۶ هزار توکنی پشتیبانی میکنند که معادل خواندن دهها کتاب یا هزاران خط کد برنامهنویسی در یک درخواست است.
۴. قابلیتهای پیشرفته برنامهنویسی و ساخت Agent:
جمما ۴ در بنچمارکهای کدنویسی پیشرفت خیرهکنندهای داشته است. این مدلها با پشتیبانی داخلی از قابلیت فراخوانی تابع (Function-calling)، میتوانند به عنوان مغز متفکر در ساخت عوامل هوشمند خودمختار (Autonomous Agents) استفاده شوند؛ عواملی که قادرند ابزارهای خارجی (مانند ماشینحساب، جستجوگر وب یا APIها) را به صورت خودکار فراخوانی کنند.
۵. پشتیبانی بومی از System Prompt:
برای اولین بار، خانواده جمما از نقش “System” در قالب مکالمات پشتیبانی میکند. این ویژگی به توسعهدهندگان اجازه میدهد تا شخصیت، لحن و قوانین سفتوسختی را پیش از شروع مکالمه برای مدل تعریف کنند.
بخش چهارم: بررسی بنچمارکها و عملکرد رقابتی
برای درک بهتر قدرت این مدلها، گوگل آنها را در طیف وسیعی از آزمونهای استاندارد (بنچمارکها) مورد ارزیابی قرار داده است. در جدول زیر، مقایسه عملکرد نسخههای مختلف را مشاهده میکنیم:
| نام آزمون (موضوع) | Gemma 4 31B | Gemma 4 26B A4B | Gemma 4 E4B | Gemma 4 E2B |
| MMLU Pro (دانش عمومی و تخصصی) | ۸۵.۲٪ | ۸۲.۶٪ | ۶۹.۴٪ | ۶۰.۰٪ |
| AIME 2026 (ریاضیات پیشرفته – بدون ابزار) | ۸۹.۲٪ | ۸۸.۳٪ | ۴۲.۵٪ | ۳۷.۵٪ |
| LiveCodeBench v6 (کدنویسی) | ۸۰.۰٪ | ۷۷.۱٪ | ۵۲.۰٪ | ۴۴.۰٪ |
| Codeforces ELO (مسابقات برنامهنویسی) | ۲۱۵۰ | ۱۷۱۸ | ۹۴۰ | ۶۳۳ |
| MMMLU (درک چندوجهی) | ۸۸.۴٪ | ۸۶.۳٪ | ۷۶.۶٪ | ۶۷.۴٪ |
| MATH-Vision (ریاضیات بصری) | ۸۵.۶٪ | ۸۲.۴٪ | ۵۹.۵٪ | ۵۲.۴٪ |
| MRCR v2 (تست درک طولانیمدت – ۱۲۸k) | ۶۶.۴٪ | ۴۴.۱٪ | ۲۵.۴٪ | ۱۹.۱٪ |
تحلیل دادههای بنچمارک:
همانطور که مشاهده میکنید، مدل متراکم ۳۱ میلیاردی در رقابتهای برنامهنویسی (با امتیاز ELO برابر ۲۱۵۰) در سطح برنامهنویسان حرفهای عمل میکند. مدل ۲۶ میلیاردی MoE با وجود استفاده از پارامترهای فعال بسیار کمتر، عملکردی بسیار نزدیک به مدل ۳۱ میلیاردی دارد که نشاندهنده بهینگی شدید این معماری است. در بخش ریاضیات نیز امتیاز نزدیک به ۹۰ درصد در مسابقات دشوار AIME بینظیر است.
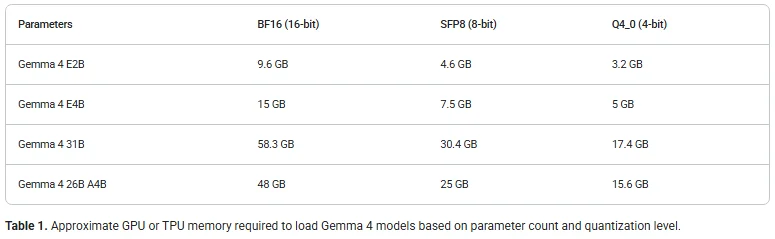
بخش پنجم: راهنمای سختافزار و نیازمندیهای حافظه (VRAM)
یکی از بزرگترین دغدغههای توسعهدهندگان سایت سیمرغ و متخصصین ماشین لرنینگ، میزان حافظه مورد نیاز برای اجرای مدلهای متنباز است. جدول زیر میزان تقریبی حافظه ویدیویی (VRAM) مورد نیاز برای اجرای مدلهای Gemma 4 در سطوح مختلف کمیسازی (Quantization) را نشان میدهد:
| مدل هدف | دقت استاندارد (BF16 – 16 bit) | کوانتایز ۸ بیتی (SFP8) | کوانتایز ۴ بیتی (Q4_0) |
| Gemma 4 E2B | ۹.۶ گیگابایت | ۴.۶ گیگابایت | ۳.۲ گیگابایت |
| Gemma 4 E4B | ۱۵.۰ گیگابایت | ۷.۵ گیگابایت | ۵.۰ گیگابایت |
| Gemma 4 31B Dense | ۵۸.۳ گیگابایت | ۳۰.۴ گیگابایت | ۱۷.۴ گیگابایت |
| Gemma 4 26B A4B MoE | ۴۸.۰ گیگابایت | ۲۵.۰ گیگابایت | ۱۵.۶ گیگابایت |
نکات حیاتی در مدیریت حافظه:
- چالش مدلهای MoE: در معماری Mixture-of-Experts، اگرچه در لحظه تنها بخش کوچکی از شبکه (مثلاً ۴ میلیارد پارامتر) فعال است، اما برای حفظ سرعت پردازش، تمام ۲۶ میلیارد پارامتر باید در حافظه RAM یا VRAM سیستم شما بارگذاری شوند. به همین دلیل نیاز حافظه مدل 26B بسیار بیشتر از یک مدل معمولی ۴ میلیاردی است.
- حافظه پنهان زمینه (KV Cache): اعداد جدول بالا تنها برای بارگذاری «وزنهای استاتیک» مدل است. به محض اینکه شما یک متن ۲۰۰ هزار توکنی را به مدل وارد کنید، سیستم برای پردازش این توکنها (KV Cache) به گیگابایتها حافظه اضافی نیاز خواهد داشت.
- فرآیند تنظیم دقیق (Fine-Tuning): حافظه مورد نیاز برای آموزش و تیونینگ مدل به مراتب بیشتر از استنتاج (Inference) است. برای کاهش این بار، استفاده از روشهای تنظیم دقیق مبتنی بر کارایی پارامتر (PEFT) مانند LoRA یا QLoRA شدیداً توصیه میشود.
بخش ششم: پیادهسازی و بهترین روشها برای توسعهدهندگان
برای شروع کار با Gemma 4، میتوانید از کتابخانه محبوب transformers در پایتون استفاده کنید. ابتدا باید ابزارهای لازم را نصب کنید:
pip install -U transformers torch accelerate
سپس میتوانید با استفاده از کلاسهای AutoProcessor و AutoModelForCausalLM مدل را بارگذاری کنید.
بهترین روشها (Best Practices) برای بهینهسازی خروجی:
- پارامترهای نمونهبرداری: شرکت گوگل توصیه میکند برای دستیابی به پایدارترین و باکیفیتترین خروجی، تنظیمات Temperature روی ۱.۰، Top_P روی ۰.۹۵ و Top_K روی ۶۴ تنظیم شود.
- مدیریت حالت تفکر (Thinking Mode): برای فعال کردن سیستم تفکر، باید توکن
<|think|>در ابتدای System Prompt قرار گیرد. در خروجی مدل، فرایند استدلال در بلوک<|channel>thought\n[Internal reasoning]<channel|>قرار میگیرد و پس از آن پاسخ نهایی به کاربر ارائه میشود. - مدیریت حافظه تاریخچه: در چتهای طولانی (Multi-Turn)، بسیار مهم است که محتوای بلوکهای تفکر مدل را از تاریخچه چت حذف کنید و تنها «پاسخهای نهایی» را برای چرخه بعدی به مدل ارسال کنید. در غیر این صورت، پنجره زمینه به سرعت پر شده و مدل دچار توهم یا سردرگمی میشود.
- رزولوشن متغیر تصاویر: توسعهدهندگان میتوانند بودجه توکنی (Token Budget) اختصاصیافته به هر تصویر را بین ۷۰ تا ۱۱۲۰ توکن تنظیم کنند. برای کارهای ساده مثل تشخیص اشیا، بودجه پایینتر سرعت را افزایش میدهد؛ اما برای پردازش اسناد متنی (OCR)، بودجه ۱۱۲۰ توکنی بالاترین دقت را تضمین میکند.
- ترتیب ورودی چندوجهی: همواره سعی کنید فایلهای صوتی یا تصویری را در Prompt پیش از متن قرار دهید تا درک مدل افزایش یابد.
بخش هفتم: دادههای آموزشی و پیشپردازشها
قابلیتهای شگفتانگیز Gemma 4 ریشه در دادههایی دارد که روی آنها آموزش دیده است. مجموعه داده پیشآموزش (Pre-training) این مدل تا ژانویه ۲۰۲۵ بهروزرسانی شده و شامل حجم عظیمی از دادههای وب، کدها، متون ریاضیات، تصاویر و فایلهای صوتی است.
- برای مثال، مدل 27B نسل قبل (Gemma 3) با ۱۴ تریلیون توکن آموزش دیده بود و این روند یادگیری گسترده در نسل چهارم نیز برای درک بیش از ۱۴۰ زبان زنده دنیا ادامه یافته است.
- فیلترینگ و پاکسازی: گوگل به شدت روی حذف محتوای حساس و مضر تمرکز کرده است. دادههای آموزشی از چندین فیلتر بررسی محتوای سوءاستفاده از کودکان (CSAM)، حذف اطلاعات شخصی (PII) و دادههای حساس دیگر عبور کردهاند تا خروجی نهایی، یک هوش مصنوعی امن و قابل اتکا برای استفادههای سازمانی باشد.
بخش هشتم: محدودیتها و ملاحظات اخلاقی
با وجود تمام پیشرفتها، رسانه هوش مصنوعی سیمرغ بر این باور است که توسعهدهندگان باید از محدودیتهای مدلهای زاینده آگاه باشند:
- دقت فکتها و اطلاعات: مدلهای زبانی دیتابیس یا پایگاه دانش قطعی نیستند. آنها الگوهای آماری کلمات را یاد گرفتهاند؛ بنابراین احتمال تولید اطلاعات نادرست (Hallucination) یا قدیمی در آنها وجود دارد.
- ابهامات زبانی: کنایه، طنز پیچیده یا مفاهیم به شدت انتزاعی ممکن است همچنان برای مدل گیجکننده باشند.
- سوگیری (Bias): از آنجایی که مدلها بر روی دادههای موجود در اینترنت آموزش دیدهاند، ممکن است سوگیریهای فرهنگی یا اجتماعی را بازتاب دهند. توسعهدهندگان باید با استفاده از ابزارهایی مانند ShieldGemma روی خروجیها نظارت داشته باشند.
نتیجهگیری تیم رسانه هوش مصنوعی سیمرغ
خانواده Gemma 4 از شرکت دیپمایند گوگل، صرفاً یک بهروزرسانی ساده نیست. معرفی مدل ۲۶ میلیاردی بر پایه معماری MoE، در کنار پشتیبانی از درک عمیق تصاویر، فایلهای صوتی و استدلال گامبهگام، نشان میدهد که آینده نرمافزارها و عوامل هوشمند تا چه حد میتواند دگرگون شود. پنجره زمینه ۲۵۶ هزار توکنی و عملکردی که بسیاری از رقبا را در بنچمارکهای استاندارد به چالش میکشد، Gemma 4 را به یکی از جذابترین ابزارهای متنباز حال حاضر دنیا برای محققین و استارتاپهای هوش مصنوعی تبدیل کرده است.