

هوش مصنوعی GPT-5.5 معرفی شد؛ هوشمندترین مدل OpenAI
OpenAI با معرفی GPT-5.5 یک قدم مهم دیگر در مسیر مدلهایی برداشته که فقط پاسخ نمیدهند، بلکه کار را پیش میبرند. این مدل که در ۲۴ آوریل ۲۰۲۶ معرفی شد، به گفته OpenAI «باهوشترین و شهودیترین مدل برای استفاده» تا امروز است و قرار است شیوه تعامل کاربران با کامپیوتر را از یک فرایند مرحلهبهمرحله و دستی، به یک همکاری طبیعیتر و سریعتر با هوش مصنوعی تبدیل کند.
GPT-5.5 فقط یک نسخه کمی بهتر از نسل قبل نیست. پیام اصلی معرفی این مدل روشن است: OpenAI میخواهد هوش مصنوعی را از سطح «پاسخگو» به سطح «عامل اجرایی» برساند. مدلی که بتواند یک کار مبهم، چندبخشی و طولانی را بگیرد، آن را برنامهریزی کند، ابزارها را بهکار بگیرد، نتیجه را بررسی کند و تا پایان مسیر ادامه دهد. بدون اینکه کاربر مجبور باشد هر قدم را مثل مدیر پروژهای خسته و بیحوصله، خودش کنترل کند.
GPT-5.5 چیست و چه تفاوتی با نسل قبل دارد؟
GPT-5.5 برای کارهای واقعی طراحی شده است. OpenAI میگوید این مدل در زمینههایی مثل کدنویسی، اشکالزدایی، جستوجوی آنلاین، تحلیل داده، ساخت سند و صفحهگسترده، کار با نرمافزارها و جابهجایی بین ابزارها عملکرد بسیار قویتری دارد. نکته مهم این است که مدل فقط پاسخ دقیقتری نمیدهد، بلکه بهتر میفهمد کاربر چه میخواهد و بخش بیشتری از کار را خودش انجام میدهد.
در واقع GPT-5.5 برای شرایطی ساخته شده که مسئله از جنس «یک سؤال ساده» نیست، بلکه شبیه این است:
«این فایل، این دادهها، این خطای مبهم، این محیط نرمافزاری و این هدف نهایی را داری، حالا خودت بفهم چه باید کرد.»
همین توانایی باعث شده OpenAI از اصطلاح agentic AI یا هوش مصنوعی عاملمحور برای توصیف این نسل استفاده کند. یعنی مدلی که فقط محاسبه نمیکند، بلکه تصمیم میگیرد، عمل میکند و در طول مسیر مسیرش را اصلاح میکند.
سرعت بیشتر، بدون قربانی کردن توانایی!
یکی از نکات برجسته GPT-5.5 این است که با وجود افزایش قدرت، از نظر سرعت هم عقب نمانده است. OpenAI اعلام کرده که GPT-5.5 در تاخیر به ازای هر توکن در عمل با GPT-5.4 همسطح است، اما در سطح هوشمندی عملکرد بسیار بالاتری دارد. این موضوع اهمیت زیادی دارد، چون معمولاً مدلهای بزرگتر و قدرتمندتر کندتر هم میشوند. اینجا اما OpenAI تلاش کرده این هزینه را پایین نگه دارد.
از طرف دیگر، GPT-5.5 در انجام وظایف Codex توکنهای کمتری مصرف میکند. یعنی هم کارآمدتر است و هم کمهزینهتر از نسل قبلی در بسیاری از سناریوها. به زبان ساده، مدل فقط بیشتر نمیفهمد، بلکه کمحرفتر و دقیقتر هم شده است. چیزی که در دنیای هوش مصنوعی یک فضیلت کمیاب محسوب میشود.

مقایسه GPT-5.5 با رقبا
| مدل | Terminal-Bench 2.0 | Expert-SWE | GDPval | OSWorld-Verified | Toolathlon | BrowseComp | FrontierMath Tier 1–۳ | FrontierMath Tier 4 |
|---|---|---|---|---|---|---|---|---|
| GPT-5.5 | ۸۲.۷% | ۷۳.۱% | ۸۴.۹% | ۷۸.۷% | ۵۵.۶% | ۸۴.۴% | ۵۱.۷% | ۳۵.۴% |
| GPT-5.4 | ۷۵.۱% | ۶۸.۵% | ۸۳.۰% | ۷۵.۰% | ۵۴.۶% | ۸۲.۷% | ۴۷.۶% | ۲۷.۱% |
| Claude Opus 4.7 | ۶۹.۴% | – | ۸۰.۳% | ۷۸.۰% | – | ۷۹.۳% | ۴۳.۸% | ۲۲.۹% |
| Gemini 3.1 Pro | ۶۸.۵% | – | ۶۷.۳% | – | ۴۸.۸% | ۸۵.۹% | ۳۶.۹% | ۱۶.۷% |
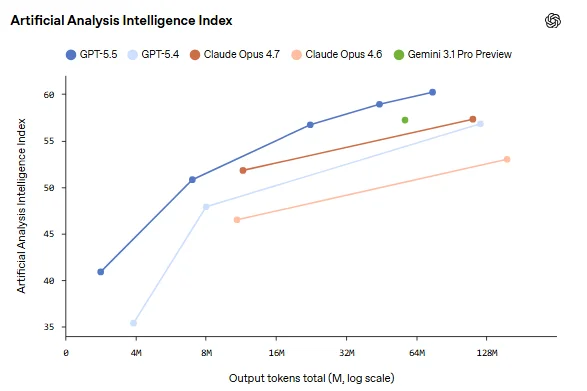
عملکرد GPT-5.5 در بنچمارکها
OpenAI برای نشان دادن پیشرفت مدل جدید جیپیتی ۵.۵ از مجموعهای از ارزیابیها استفاده کرده که حوزههای مختلف را پوشش میدهند: کدنویسی، کار حرفهای، استفاده از کامپیوتر، استفاده از ابزار، پژوهش علمی، امنیت سایبری، استدلال انتزاعی و کار با کانتکست طولانی.
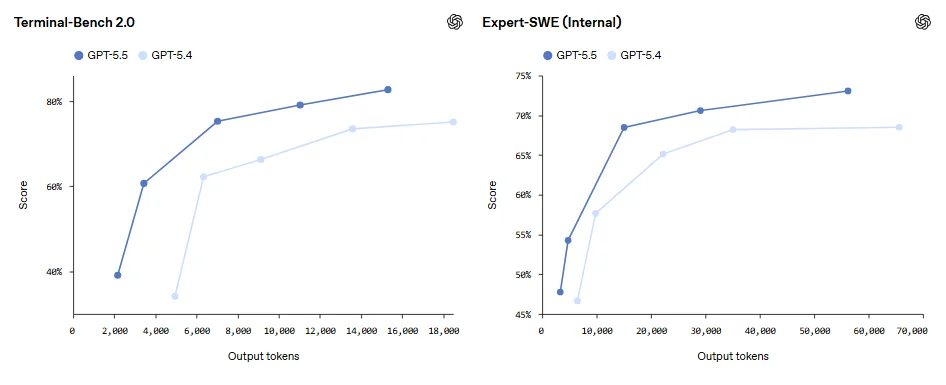
کدنویسی
در بخش کدنویسی، GPT-5.5 در Terminal-Bench 2.0 به امتیاز ۸۲.۷٪ رسیده، در حالی که GPT-5.4 امتیاز ۷۵.۱٪ داشته است.
در SWE-Bench Pro نیز GPT-5.5 با ۵۸.۶٪ بهتر از GPT-5.4 با ۵۷.۷٪ ظاهر شده و در Expert-SWE نیز از ۶۸.۵٪ به ۷۳.۱٪ رسیده است.
این اعداد فقط یک پیشرفت عددی خشک نیستند. معناشان این است که GPT-5.5 بهتر میتواند در پروژههای واقعی نرمافزاری، از مرحله فهم مسئله تا نوشتن، تست و اصلاح کد، همراه کاربر بماند.
| مدل | SWE-Bench Pro | Terminal-Bench 2.0 | Expert-SWE |
|---|---|---|---|
| GPT-5.5 | ۵۸.۶% | ۸۲.۷% | ۷۳.۱% |
| GPT-5.4 | ۵۷.۷% | ۷۵.۱% | ۶۸.۵% |
| Claude Opus 4.7 | ۶۴.۳% | ۶۹.۴% | – |
| Gemini 3.1 Pro | ۵۴.۲% | ۶۸.۵% | – |
GPT-5.5 در انجام تسکهای پیچیده و اداری
در GDPval، که توانایی مدل در انجام کارهای حرفهای در ۴۴ شغل را میسنجد، GPT-5.5 امتیاز ۸۴.۹٪ گرفته است.
در OSWorld-Verified نیز به ۷۸.۷٪ رسیده و در Tau2-bench Telecom به ۹۸.۰٪ بدون prompt tuning دست یافته است.
این بخش برای کسبوکارها مهمتر از آن چیزی است که در نگاه اول به نظر میرسد. چون نشان میدهد مدل میتواند از پس کارهای اداری، تحلیلی و عملیاتی واقعی برآید. نه فقط تولید متن قشنگ برای نمایشهای تبلیغاتی که بعداً کسی هم سراغشان نمیرود.
| مدل | GDPval | FinanceAgent | OfficeQA Pro | Investment Banking Tasks |
|---|---|---|---|---|
| GPT-5.5 | ۸۴.۹% | ۶۰.۰% | ۵۴.۱% | ۸۸.۵% |
| GPT-5.4 | ۸۳.۰% | ۵۶.۰% | ۵۳.۲% | ۸۷.۳% |
| GPT-5.5 Pro | ۸۲.۳% | ۶۱.۵% | – | ۸۸.۶% |
| Claude Opus 4.7 | ۸۰.۳% | ۶۴.۴% | ۴۳.۶% | – |
| Gemini 3.1 Pro | ۶۷.۳% | ۵۹.۷% | ۱۸.۱% | – |
جیپیتی ۵.۵ در پژوهش علمی
GPT-5.5 در کارهای علمی و پژوهشی هم پیشرفت قابل توجهی داشته است. در GeneBench، BixBench و سایر ارزیابیهای مرتبط، این مدل بهتر از نسل قبلی عمل کرده و حتی OpenAI ادعا میکند که نسخهای داخلی از GPT-5.5 توانسته در یک مسئله مربوط به اعداد رمزی یک برهان جدید پیدا کند که بعداً در Lean هم تأیید شده است.
اگر این ادعا را جدی بگیریم، پیامش روشن است: GPT-5.5 فقط برای نوشتن کد یا متن نیست، بلکه میتواند در برخی روندهای پژوهشی نیز نقش یک همکار تحلیلی را بازی کند.
| مدل | GeneBench | BixBench | GPQA Diamond | Humanity’s Last Exam (with tools) |
|---|---|---|---|---|
| GPT-5.5 | ۲۵.۰% | ۸۰.۵% | ۹۳.۶% | ۵۲.۲% |
| GPT-5.4 | ۱۹.۰% | ۷۴.۰% | ۹۲.۸% | ۵۲.۱% |
| GPT-5.5 Pro | ۳۳.۲% | – | – | ۵۷.۲% |
| Claude Opus 4.7 | – | – | ۹۴.۲% | ۵۴.۷% |
| Gemini 3.1 Pro | – | – | ۹۴.۳% | ۵۱.۴% |
استفاده از کامپیوتر و ابزارها
در Tool use و computer use هم GPT-5.5 رشد خوبی نشان داده است. روی BrowseComp به ۸۴.۴٪، روی MCP Atlas به ۷۵.۳٪ و روی Toolathlon به ۵۵.۶٪ رسیده است.
در MMMU Pro نیز با و بدون ابزار، عملکرد مدل نسبت به GPT-5.4 بهتر یا حداقل همسطح بوده است. این یعنی مدل فقط در پاسخگویی زبانی قوی نیست، بلکه در کار با محیطهای واقعی و ابزارمحور هم رشد کرده است.
| مدل | OSWorld-Verified | MMMU Pro (no tools) | MMMU Pro (with tools) | BrowseComp | MCP Atlas |
|---|---|---|---|---|---|
| GPT-5.5 | ۷۸.۷% | ۸۱.۲% | ۸۳.۲% | ۸۴.۴% | ۷۵.۳% |
| GPT-5.4 | ۷۵.۰% | ۸۱.۲% | ۸۲.۱% | ۸۲.۷% | ۷۰.۶% |
| Claude Opus 4.7 | ۷۸.۰% | – | – | ۷۹.۳% | ۷۹.۱% |
| Gemini 3.1 Pro | – | ۸۰.۵% | – | ۸۵.۹% | ۷۸.۲% |
استدلال انتزاعی و کانتکست طولانی
در آزمونهایی مثل ARC-AGI-1 و ARC-AGI-2، GPT-5.5 نیز عملکرد خوبی ثبت کرده و در ارزیابیهای کانتکست طولانی مثل Graphwalks و OpenAI MRCR، نسبت به نسل قبل جهش قابل توجهی نشان داده است. این موضوع برای کارهای طولانیمدت، چندمرحلهای و وابسته به حافظه زمینهای بسیار مهم است.
| مدل | Graphwalks BFS 256k | Graphwalks BFS 1M | MRCR 512K–1M |
|---|---|---|---|
| GPT-5.5 | ۷۳.۷% | ۴۵.۴% | ۷۴.۰% |
| GPT-5.4 | ۶۲.۵% | ۹.۴% | ۳۶.۶% |
| Claude Opus 4.7 | ۷۶.۹% | ۴۱.۲% | ۳۲.۲% |
| Gemini 3.1 Pro | – | – | – |
چرا GPT-5.5 برای کدنویسی مهم است؟
OpenAI GPT-5.5 را «قویترین مدل عاملمحور در کدنویسی» خود معرفی کرده است. این مدل بهویژه در کارهایی مثل:
- پیادهسازی قابلیتهای جدید
- بازنویسی و refactor
- دیباگ
- تست
- اعتبارسنجی
- درک ساختار یک سیستم بزرگ
عملکرد بهتری از خود نشان میدهد.
طبق بازخوردهای اولیه، GPT-5.5 بهتر از GPT-5.4 میتواند ساختار یک پروژه را بفهمد. یعنی فقط به خطاها واکنش نشان نمیدهد، بلکه تشخیص میدهد مشکل از کجا شروع شده، در کدام بخش باید اصلاح شود و چه قسمتهای دیگری از کد تحت تأثیر قرار میگیرند.
این همان تفاوت میان یک مدل «پاسخگو» و یک مدل «فهممحور» است. اولی به سؤال جواب میدهد. دومی مسئله را میفهمد. انسانها معمولاً همینجا تازه متوجه میشوند که چقدر از کارشان تکراری بوده است.
کاربرد در کارهای روزمره و حرفهای
یکی از جالبترین بخشهای معرفی GPT-5.5 این است که OpenAI آن را فقط برای برنامهنویسان معرفی نکرده، بلکه آن را ابزاری برای کار دانشمحور در معنای وسیعتر میداند. این مدل در ChatGPT و Codex میتواند در کارهایی مثل:
- تحلیل اطلاعات
- ساخت گزارش
- تهیه فایلهای اکسل
- تولید اسلاید
- تحقیق آنلاین
- جمعبندی اسناد
- کار با نرمافزارها
کمک کند.
در نمونههای داخلی OpenAI، تیمهای مختلف از GPT-5.5 برای بررسی دادهها، ساخت چارچوبهای امتیازدهی، خودکارسازی پاسخها و حتی تحلیل هزاران فرم مالیاتی استفاده کردهاند. بهگفته OpenAI، بیش از ۸۵٪ کارکنان این شرکت هر هفته از Codex استفاده میکنند.
یعنی جیپیتی ۵.۵ قرار نیست فقط در دموها بدرخشد. قرار است در کارهای واقعی، وقت، انرژی و اعصاب آدمها را کمتر به نابودی بکشاند.

جیپیتی ۵.۵ در گیتهاب
مدل GPT 5.5، جدیدترین مدل GPT از OpenAI، اکنون در GitHub Copilot در دسترس عموم قرار گرفته است. طبق آزمایشهای اولیه، این مدل در حل چالشهای پیچیده برنامهنویسی و وظایف چندمرحلهای با عملکرد بسیار بالاتری نسبت به مدلهای قبلی نشان داده و قادر است مشکلات واقعی کدنویسی که مدلهای قبلی نتواسته بودند حل کنند را برطرف کند. GPT-5.5 با یک ضریب درخواست ۷.۵ برابر به عنوان بخشی از قیمتگذاری تبلیغاتی راهاندازی میشود و برای کاربران Copilot Pro+، Copilot Business و Copilot Enterprise در دسترس خواهد بود. این مدل را میتوان از طریق پیکربندی مدل در ابزارهای مختلف توسعه مانند Visual Studio Code، Visual Studio، Xcode، JetBrains و GitHub Mobile در اختیار گرفت. توجه داشته باشید که این قابلیت بهطور تدریجی فعال خواهد شد، بنابراین اگر هنوز آن را مشاهده نمیکنید، به زودی دوباره بررسی کنید.
GPT-5.5 Pro چیست؟
همراه با جیپیتی ۵.۵، نسخهای پیشرفتهتر با نام GPT-5.5 Pro هم معرفی شده است. این نسخه برای کارهای سختتر و دقیقتر طراحی شده و در تستهای اولیه، پاسخهای کاملتر، ساختارمندتر، دقیقتر و مفیدتری ارائه داده است. طبق توضیح OpenAI، این نسخه بهخصوص در زمینههای کسبوکار، حقوق، آموزش و علم داده عملکرد درخشانی نشان داده است.
GPT-5.5 Pro بیشتر به درد کسانی میخورد که مسئلهشان فقط «پاسخ سریع» نیست، بلکه به تحلیل عمیق، چندمرحلهای و با دقت بالا نیاز دارند.
امنیت و محافظت؛ بخش مهم اما کمتر جذاب
OpenAI تأکید کرده که مدل جیپیتی ۵.۵ با قویترین مجموعه حفاظتی تا امروز عرضه شده است. دلیلش هم روشن است: هرچه مدلها قدرتمندتر میشوند، سوءاستفاده از آنها هم خطرناکتر میشود. به همین خاطر، برای GPT-5.5 آزمونهای ویژهای در حوزه امنیت سایبری و زیستشناسی انجام شده و تیمهای داخلی و خارجی برای red teaming و ارزیابیهای ایمنی با این مدل کار کردهاند.
OpenAI گفته که برای برخی کاربردهای حساس، محدودیتها و طبقهبندیهای سختگیرانهتری اعمال شده تا مدل در عین مفید بودن، زمینه سوءاستفاده را کمتر کند. این سیاست بهخصوص در حوزه امنیت سایبری پررنگتر است، جایی که مدلهای قدرتمند هم میتوانند برای دفاع و هم برای حمله بهکار بروند.
دسترسی و قیمت
طبق اعلام OpenAI، مدل جیپیتی ۵.۵ در ChatGPT و Codex به کاربران Plus، Pro، Business و Enterprise ارائه میشود. نسخه Pro نیز برای کاربران Pro، Business و Enterprise در ChatGPT در دسترس است.
در API هم GPT-5.5 بهزودی در دسترس خواهد بود. قیمت اعلامشده برای نسخه استاندارد ۵ دلار برای هر ۱ میلیون توکن ورودی و ۳۰ دلار برای هر ۱ میلیون توکن خروجی است. برای نسخه Pro نیز قیمت بالاتری اعلام شده است.
OpenAI همچنین گفته GPT-5.5 در Codex با پنجره کانتکست 400K عرضه میشود و در حالت Fast هم سرعت تولید توکن بالاتر است.
جمعبندی
مدل جیپیتی ۵.۵ را باید یکی از جدیترین گامهای OpenAI به سمت هوش مصنوعی عاملمحور دانست. این مدل فقط در benchmarkها بهتر نیست، بلکه در دنیای واقعی هم برای کدنویسی، تحقیق، کار اداری، تحلیل داده، استفاده از ابزارها و کار با نرمافزارها توانمندتر شده است.
پیام اصلی این نسل روشن است: هوش مصنوعی دیگر فقط قرار نیست جواب بدهد. قرار است کار انجام دهد. از اینجا به بعد، رقابت فقط بر سر «باهوشتر بودن» نیست، بلکه بر سر این است که کدام مدل بهتر میتواند در یک جریان کاری واقعی، با کمترین دخالت انسان، مسئله را تا آخر جلو ببرد.
و بله، این همان نقطهای است که هیاهوی تبلیغاتی کمکم به واقعیت عملی نزدیک میشود. کاری که اگر درست اجرا شود، برای تولیدکننده محتوا، برنامهنویس، پژوهشگر، تحلیلگر و مدیر پروژه یک انقلاب کوچک روزمره است.