

معرفی جامع هوش مصنوعی دیپ سیک DeepSeek ( بررسی مدل دیپ سیک از صفر تا صد)
فهرست عناوین
۱. مقدمه
معرفی کلی هوش مصنوعی و اهمیت مدلهای زبان بزرگ
هوش مصنوعی (AI) بهعنوان یکی از پیشگامان تحول دیجیتال، نقش بسزایی در توسعه فناوریهای نوین ایفا میکند. مدلهای زبانی بزرگ (LLM) بهویژه در پردازش زبان طبیعی، ترجمه ماشینی و تولید محتوا کاربردهای گستردهای یافتهاند. این مدلها با تحلیل و درک متون، قادر به پاسخگویی به سؤالات پیچیده و ارائه اطلاعات دقیق هستند.
در این میان، DeepSeek بهعنوان یک مدل زبانی بزرگ و نوظهور، توجه بسیاری را به خود جلب کرده است. این مدل که توسط یک استارتاپ چینی توسعه یافته، با ارائه قابلیتهای پیشرفته و عملکرد قابلتوجه، بهسرعت در میان کاربران محبوبیت پیدا کرده است. DeepSeek با استفاده از الگوریتمهای پیچیده یادگیری ماشین و پردازش زبان طبیعی، توانایی پاسخدهی به سؤالات متنوع و ارائه اطلاعات بهروز را دارد.
در ادامه این مقاله، به بررسی تاریخچه، معماری، مقایسه با مدلهای مشابه، چالشها و کاربردهای DeepSeek خواهیم پرداخت تا درکی جامع از این مدل هوش مصنوعی پیشرفته ارائه دهیم.
هوش مصنوعی دیپ سیک DeepSeek به عنوان مدلی نوظهور
در میان تحولات اخیر هوش مصنوعی، انتشار یک مدل زبان بزرگ توسط یک آزمایشگاه کمتر شناختهشده در چین به نام DeepSeek موجی از نگرانی را در سیلیکون ولی برانگیخته است. این مدل که در اواخر دسامبر به صورت متنباز معرفی شد، تنها در دو ماه و با هزینهای کمتر از ۶ میلیون دلار توسعه یافت. نکته جالب توجه این است که DeepSeek با استفاده از تراشههای میانرده مانند Nvidia H800، موفق شده مدلی بسازد که از مدلهای مطرحی همچون GPT-4o OpenAI، Claude Sonnet 3.5 Anthropic و Llama 3.1 Meta عملکرد بهتری ارائه دهد.
این موفقیت پرسشهایی را در مورد جایگاه جهانی ایالات متحده در هوش مصنوعی و هزینههای هنگفت شرکتهای بزرگ فناوری برای توسعه مدلهای پیشرفته و مراکز داده مطرح کرده است.
۲. تاریخچه و توسعه هوش مصنوعی دیپ سیک DeepSeek
تأسیس شرکت DeepSeek و بنیانگذار آن، لیانگ ونفنگ
شرکت DeepSeek در سال ۲۰۲۳ توسط لیانگ ونفنگ در چین تأسیس شد. لیانگ، متولد استان گوانگدونگ، تحصیلات خود را در دانشگاه ژجیانگ در هانگژو ادامه داد و در آنجا بر روی آموزش کامپیوترها به شیوهای مشابه انسانها تمرکز داشت. او با مشاهده فرصتهای موجود در حوزه هوش مصنوعی، تصمیم به تأسیس DeepSeek گرفت تا مدلهای زبانی پیشرفتهای را توسعه دهد که بتوانند با مدلهای برجسته جهانی رقابت کنند.
مراحل توسعه مدل هوش مصنوعی دیپ سیک و نسخههای مختلف آن
DeepSeek در مدت زمان کوتاهی موفق به توسعه مدلهای زبانی قدرتمندی شد که توجه جهانی را به خود جلب کرد. این شرکت با استفاده از معماری بهینهشدهای به نام ترکیبی از متخصصان (MoE)، مدلهایی را ایجاد کرد که نیاز به قدرت محاسباتی گسترده و سختافزارهای قدرتمند را کاهش میدهد. این معماری شامل سیستمهایی از هوش مصنوعی تخصصی است که هر “متخصص” شبکه عصبی خود را دارد و برای انجام وظایف مرتبط با خود فعال میشود.
در اواخر دسامبر ۲۰۲۴، DeepSeek مدل DeepSeek-V3 را معرفی کرد که با عملکرد خیرهکنندهاش، در مدت کوتاهی محبوبیت زیادی کسب کرد. سپس، در ژانویه ۲۰۲۵، این شرکت مدل DeepSeek-R1 را عرضه کرد که در زمینههای مختلفی مانند ریاضی، کدنویسی و استدلال پیچیده با مدلهای پیشرفتهای مانند OpenAI-o1 رقابت میکند. این مدلها با تمرکز بر شفافیت و بهبود قابلیتهای استدلال، نویدبخش آیندهای روشن در تعامل با هوش مصنوعی هستند.
توسعه سریع و موفقیتآمیز این مدلها نشاندهنده تعهد DeepSeek به پیشرفت در حوزه هوش مصنوعی و ارائه ابزارهای قدرتمند و در دسترس برای کاربران جهانی است.
۳. معماری و فناوریهای بهکاررفته در هوش مصنوعی دیپ سیک DeepSeek
• معرفی معماری مدل و تکنیکهای یادگیری عمیق
دیپسیک از معماری “ترکیب کارشناسان” (Mixture-of-Experts – MoE) استفاده میکند. این معماری به مدل اجازه میدهد تا با مدیریت کارآمد تعداد عظیمی از پارامترها، عملکرد بهتری داشته باشد. در این ساختار، هر توکن تنها زیرمجموعهای از پارامترهای مدل را فعال میکند. این رویکرد باعث پردازش تخصصیتر دادهها شده و در عین حال، بار محاسباتی را کاهش میدهد. به عنوان مثال، در مدل DeepSeek-V3، با وجود ۶۷۱ میلیارد پارامتر، تنها ۳۷ میلیارد پارامتر برای پردازش هر توکن فعال میشوند.
• استفاده از پردازش زبان طبیعی (NLP)
دیپسیک از پردازش زبان طبیعی (NLP) به طور گسترده استفاده میکند. مدلهای این شرکت به گونهای طراحی شدهاند که در طیف وسیعی از وظایف پردازش زبان طبیعی، از جمله تولید متن، درک متون و ترجمه زبانها، عملکرد بسیار خوبی داشته باشند. با بهرهگیری از تکنیکهای پیشرفته NLP، این مدلها قادر به درک و تولید متنی شبیه به زبان انسان هستند و امکاناتی مانند ساخت چتباتها، تولید محتوا و ترجمههای دقیق را فراهم میکنند.
• بهینهسازیها و نوآوریهای فنی
- برای بهبود عملکرد و کارایی، دیپسیک چندین نوآوری فنی را پیادهسازی کرده است:
- توجه نهفته چندسری (MLA): این تکنیک با فشردهسازی حافظه کلید-مقدار (KV) به یک بردار نهفته، باعث کاهش استفاده از حافظه و نیازهای محاسباتی در زمان استنتاج میشود.
- یادگیری تقویتی (RL): مدل DeepSeek-R1-Zero با استفاده از یادگیری تقویتی در مقیاس بزرگ و بدون تنظیم دقیق نظارتشده آموزش داده شده است. این روش به مدل امکان میدهد تا از طریق مشوقها، استراتژیهای حل مسئله را توسعه دهد که منجر به ظهور رفتارهای استدلالی قدرتمند شده است.
- خودبازتابی نوظهور: با ادغام مکانیزمهای خودبازتابی، مدلهای دیپسیک میتوانند بهصورت تکراری خروجیهای خود را ارزیابی و بهبود بخشند که این امر منجر به پاسخهای دقیقتر و منسجمتر میشود.
این انتخابهای معماری و پیشرفتهای تکنولوژیکی به دیپسیک امکان ارائه مدلهای هوش مصنوعی با عملکرد بالا و کارآمد را در طیف گستردهای از کاربردها میدهد.
۴. مقایسه هوش مصنوعی دیپ سیک DeepSeek با مدلهای مشابه
• مقایسه با مدلهای مطرح مانند GPT-4o، Claude Sonnet 3.5 و Llama 3.1
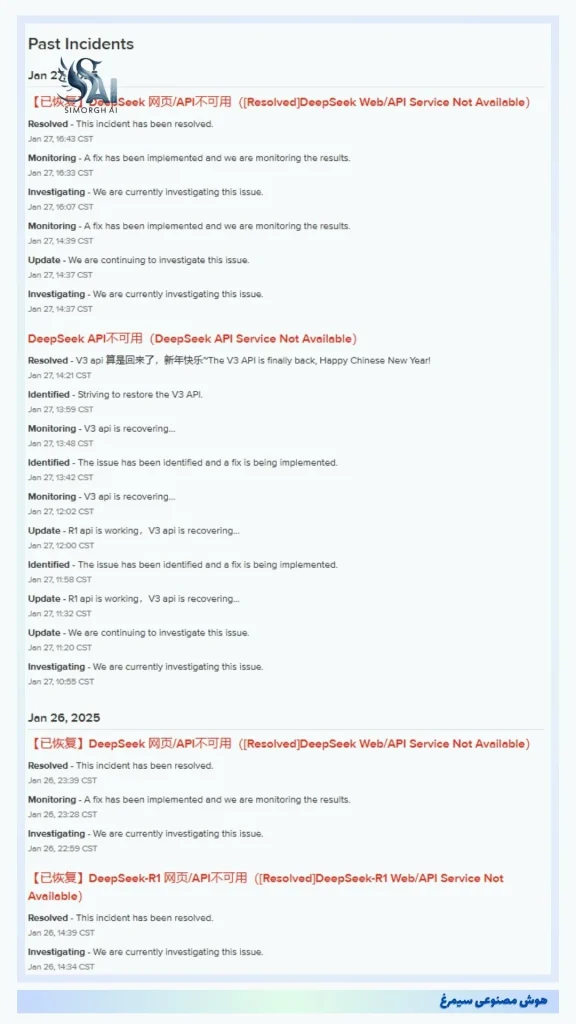
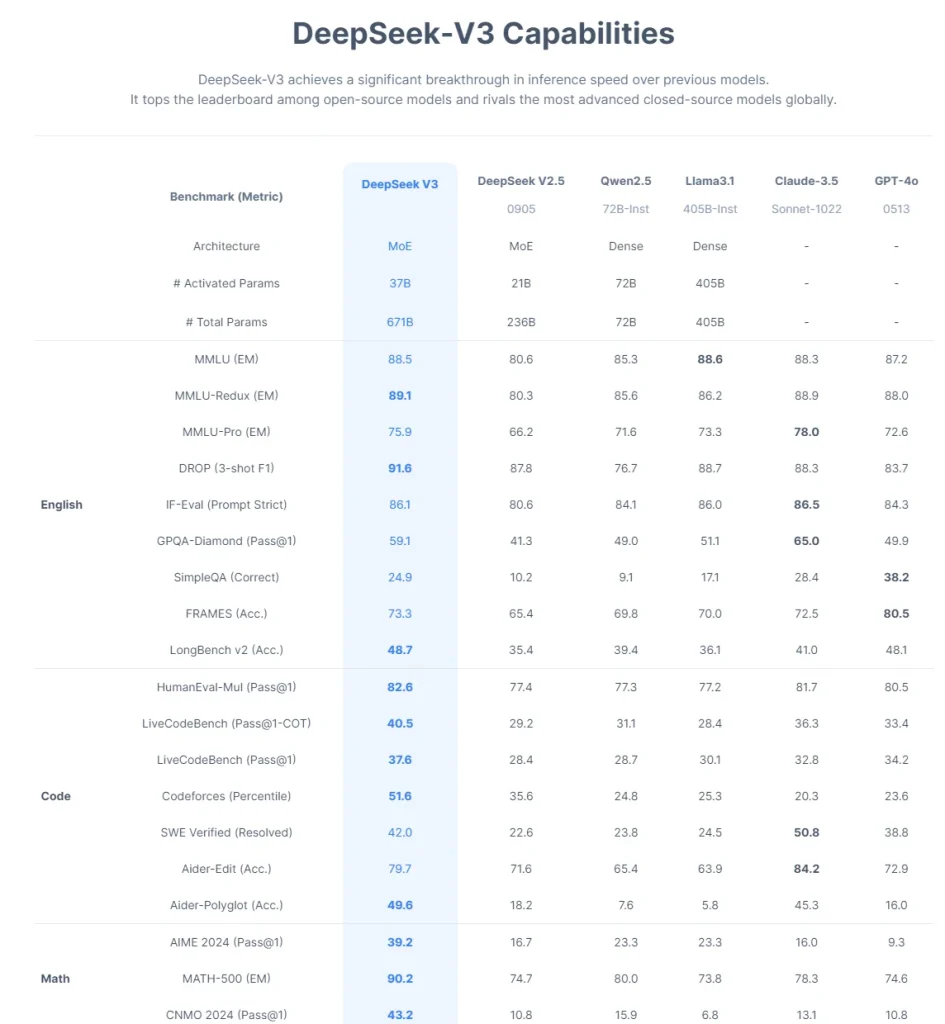
مدل DeepSeek-V3 با توجه به آزمایشهای جامع، توانسته است عملکردی در حد و حتی فراتر از مدلهای مطرحی نظیر GPT-4o، Claude Sonnet 3.5 و Llama 3.1 داشته باشد. این مدل در بسیاری از معیارهای استاندارد از جمله MMLU و GPQA عملکرد بهتری از خود نشان داده است. بهویژه در زمینههای مربوط به دانش عمومی و استدلال، DeepSeek-V3 توانسته است تفاوت میان مدلهای متنباز و متنبسته را کاهش دهد.
| Model | Chat | Chat-Hard | Safety | Reasoning | Average |
|---|---|---|---|---|---|
| GPT-4o-0513 | ۹۶.۶ | ۷۰.۴ | ۸۶.۷ | ۸۴.۹ | ۸۴.۷ |
| GPT-4o-0806 | ۹۶.۱ | ۷۶.۱ | ۸۸.۱ | ۸۶.۶ | ۸۶.۷ |
| GPT-4o-1120 | ۹۵.۸ | ۷۱.۳ | ۸۶.۲ | ۸۵.۲ | ۸۴.۶ |
| Claude-3.5-sonnet-0620 | ۹۶.۴ | ۷۴.۰ | ۸۱.۶ | ۸۴.۷ | ۸۴.۲ |
| Claude-3.5-sonnet-1022 | ۹۶.۴ | ۷۹.۷ | ۹۱.۱ | ۸۷.۶ | ۸۸.۷ |
| DeepSeek-V3 | ۹۶.۹ | ۷۹.۸ | ۸۷.۰ | ۸۴.۳ | ۸۷.۰ |
| DeepSeek-V3 (maj@6) | ۹۶.۹ | ۸۲.۶ | ۸۹.۵ | ۸۹.۲ | ۸۹.۶ |
مقایسه مدل های GPT-4o، کلود-۳.۵-سونت و DeepSeek-V3 در RewardBench
| Model | Arena-Hard | AlpacaEval 2.0 |
|---|---|---|
| DeepSeek-V2.5-0905 | ۷۶.۲ | ۵۰.۵ |
| Qwen2.5-72B-Instruct | ۸۱.۲ | ۴۹.۱ |
| LLaMA-3.1 405B | ۶۹.۳ | ۴۰.۵ |
| GPT-4o-0513 | ۸۰.۴ | ۵۱.۱ |
| Claude-Sonnet-3.5-1022 | ۸۵.۲ | ۵۲.۰ |
| DeepSeek-V3 | ۸۵.۵ | ۷۰.۰ |
بررسی عملکرد در وظایف مختلف مانند حل مسائل ریاضی، کدنویسی و استدلال
مدل DeepSeek-V3 در حل مسائل ریاضی و وظایف کدنویسی، بهویژه در آزمونهایی مانند MATH 500 و Codeforces، توانسته است رتبه اول را در میان مدلهای متنباز و برخی مدلهای متنبسته کسب کند. در زمینه کدنویسی، این مدل با ارائه نتایجی بسیار دقیق، به عنوان یکی از پیشرفتهترین مدلها شناخته شده است. همچنین، در وظایف مهندسی مرتبط، هرچند که عملکردی کمی پایینتر از Claude Sonnet 3.5 داشته، اما در مقایسه با دیگر مدلها پیشتاز بوده است.
این مقایسه نشان میدهد که DeepSeek-V3 توانسته است با هزینه کمتر و سختافزار میانرده، در رقابت با مدلهای پیچیده و پرهزینه جایگاهی برتر کسب کند.
Benchmark (Metric) | DeepSeek | DeepSeek | Qwen2.5 | LLaMA-3.1 | Claude-3.5- | GPT-4o | DeepSeek | |
| V2-0506 | V2.5-0905 | 72B-Inst. | 405B-Inst. | Sonnet-1022 | ۰۵۱۳ | V3 | ||
| Architecture | MoE | MoE | Dense | Dense | – | – | MoE | |
| # Activated Params | 21B | 21B | 72B | 405B | – | – | 37B | |
| # Total Params | 236B | 236B | 72B | 405B | – | – | 671B | |
| English | MMLU (EM) | ۷۸.۲ | ۸۰.۶ | ۸۵.۳ | ۸۸.۶ | ۸۸.۳ | ۸۷.۲ | ۸۸.۵ |
| MMLU-Redux (EM) | ۷۷.۹ | ۸۰.۳ | ۸۵.۶ | ۸۶.۲ | ۸۸.۹ | ۸۸.۰ | ۸۹.۱ | |
| MMLU-Pro (EM) | ۵۸.۵ | ۶۶.۲ | ۷۱.۶ | ۷۳.۳ | ۷۸.۰ | ۷۲.۶ | ۷۵.۹ | |
| DROP (3-shot F1) | ۸۳.۰ | ۸۷.۸ | ۷۶.۷ | ۸۸.۷ | ۸۸.۳ | ۸۳.۷ | ۹۱. | |
| IF-Eval (Prompt Strict) | ۵۷.۷ | ۸۰.۶ | ۸۴.۱ | ۸۶.۰ | ۸۶.۵ | ۸۴.۳ | ۸۶.۱ | |
| GPQA-Diamond (Pass@1) | ۳۵.۳ | ۴۱.۳ | ۴۹.۰ | ۵۱.۱ | ۶۵.۰ | ۴۹.۹ | ۵۹.۱ | |
| SimpleQA (Correct) | ۹.۰ | ۱۰.۲ | ۹.۱ | ۱۷.۱ | ۲۸.۴ | ۳۸.۲ | ۲۴.۹ | |
| FRAMES (Acc.) | ۶۶.۹ | ۶۵.۴ | ۶۹.۸ | ۷۰.۰ | ۷۲.۵ | ۸۰.۵ | ۷۳.۳ | |
| LongBench v2 (Acc.) | ۳۱.۶ | ۳۵.۴ | ۳۹.۴ | ۳۶.۱ | ۴۱.۰ | ۴۸.۱ | ۴۸.۷ | |
| Code | HumanEval-Mul (Pass@1) | ۶۹.۳ | ۷۷.۴ | ۷۷.۳ | ۷۷.۲ | ۸۱.۷ | ۸۰.۵ | ۸۲.۶ |
| LiveCodeBench (Pass@1-COT) | ۱۸.۸ | ۲۹.۲ | ۳۱.۱ | ۲۸.۴ | ۳۶.۳ | ۳۳.۴ | ۴۰.۵ | |
| LiveCodeBench (Pass@1) | ۲۰.۳ | ۲۸.۴ | ۲۸.۷ | ۳۰.۱ | ۳۲.۸ | ۳۴.۲ | ۳۷.۶ | |
| Codeforces (Percentile) | ۱۷.۵ | ۳۵.۶ | ۲۴.۸ | ۲۵.۳ | ۲۰.۳ | ۲۳.۶ | ۵۱.۶ | |
| SWE Verified (Resolved) | – | ۲۲.۶ | ۲۳.۸ | ۲۴.۵ | ۵۰.۸ | ۳۸.۸ | ۴۲.۰ | |
| Aider-Edit (Acc.) | ۶۰.۳ | ۷۱.۶ | ۶۵.۴ | ۶۳.۹ | ۸۴.۲ | ۷۲.۹ | ۷۹.۷ | |
| Aider-Polyglot (Acc.) | – | ۱۸.۲ | ۷.۶ | ۵.۸ | ۴۵.۳ | ۱۶.۰ | ۴۹.۶ | |
| Math | AIME 2024 (Pass@1) | ۴.۶ | ۱۶.۷ | ۲۳.۳ | ۲۳.۳ | ۱۶.۰ | ۹.۳ | ۳۹.۲ |
| MATH-500 (EM) | ۵۶.۳ | ۷۴.۷ | ۸۰.۰ | ۷۳.۸ | ۷۸.۳ | ۷۴.۶ | ۹۰.۲ | |
| CNMO 2024 (Pass@1) | ۲.۸ | ۱۰.۸ | ۱۵.۹ | ۶.۸ | ۱۳.۱ | ۱۰.۸ | ۴۳.۲ | |
| Chinese | CLUEWSC (EM) | ۸۹.۹ | ۹۰.۴ | ۹۱.۴ | ۸۴.۷ | ۸۵.۴ | ۸۷.۹ | ۹۰.۹ |
| C-Eval (EM) | ۷۸.۶ | ۷۹.۵ | ۸۶.۱ | ۶۱.۵ | ۷۶.۷ | ۷۶.۰ | ۸۶.۵ | |
| C-SimpleQA (Correct) | ۴۸.۵ | ۵۴.۱ | ۴۸.۴ | ۵۰.۴ | ۵۱.۳ | ۵۹.۳ | ۶۴.۸ |
۵. چالشها و محدودیتهای هوش مصنوعی دیپ سیک
محدودیتهای سختافزاری و استفاده از تراشههای میانرده
یکی از چالشهای اصلی مدل DeepSeek-V3 استفاده از تراشههای میانرده مانند NVIDIA H800 است. در حالی که این تراشهها هزینه و مصرف انرژی کمتری نسبت به مدلهای پیشرفته مانند NVIDIA H100 دارند، اما محدودیتهایی در قدرت پردازش و سرعت ارائه عملکرد بهینه ایجاد میکنند. با این حال، تیم DeepSeek از راهکارهایی مانند استفاده از الگوریتمهای فشردهسازی حافظه و تکنیکهای پردازشی بهینه برای کاهش این محدودیتها بهره برده است.
محدودیتهای ناشی از تحریمها و کنترلهای صادراتی
تحریمهای ایالات متحده علیه چین، محدودیتهایی برای دسترسی به سختافزارهای پیشرفته مانند پردازندههای NVIDIA H100 ایجاد کرده است. این محدودیتها تیم DeepSeek را مجبور به نوآوری در استفاده از منابع موجود کرده است. به عنوان مثال، استفاده از روشهای کاهش دقت عددی (FP8 Mixed Precision) به آنها کمک کرده است تا با منابع کمتر به بازدهی بالاتری دست یابند.
با وجود این چالشها، DeepSeek توانسته است با استفاده از راهکارهای نوآورانه در زمینه پردازش و مدیریت منابع، محدودیتهای سختافزاری و تحریمی را به فرصتی برای توسعه مدلهای کارآمدتر تبدیل کند. این موفقیت نشاندهنده تعهد این تیم به پیشرفت در حوزه هوش مصنوعی و ارائه ابزارهای قدرتمند با هزینه کمتر است.
۶. پاسخها و واکنشهای بینالمللی
واکنشهای سیلیکون ولی و شرکتهای فناوری آمریکایی
معرفی مدل هوش مصنوعی DeepSeek-V3 توسط استارتآپ چینی DeepSeek، واکنشهای قابلتوجهی در سیلیکون ولی و میان شرکتهای فناوری آمریکایی به همراه داشته است. این مدل متنباز و مقرونبهصرفه، با عملکردی قابلمقایسه با مدلهای پیشرفته آمریکایی، نگرانیهایی را در مورد سرمایهگذاریهای کلان در حوزه هوش مصنوعی و برتری فناوری آمریکا ایجاد کرده است. بهدنبال این رویداد، ارزش سهام شرکتهایی مانند انویدیا، مایکروسافت، متا و آلفابت کاهش یافته است.
اظهارات مدیران ارشد فناوری درباره DeepSeek
همچنین، تحلیلگران صنعت هوش مصنوعی معتقدند که موفقیت DeepSeek میتواند رقابت بین چین و آمریکا در این حوزه را تشدید کرده و تصورات موجود درباره هزینهها و مقیاسپذیری مدلهای هوش مصنوعی را به چالش بکشد.
این واکنشها نشاندهنده تأثیر عمیق موفقیت DeepSeek بر صنعت هوش مصنوعی جهانی و تغییر نگرشها نسبت به مدلهای متنباز و رقابت بینالمللی در این حوزه است.
۷. کاربردها و پتانسیلهای آینده هوش مصنوعی دیپ سیک
کاربردهای فعلی در صنایع مختلف
مدل DeepSeek-V3 به دلیل معماری پیشرفته و تواناییهای گستردهاش در بسیاری از صنایع کاربرد دارد. در حال حاضر، این مدل در حوزههایی همچون تحلیل داده، پردازش زبان طبیعی، و توسعه سیستمهای هوشمند مورد استفاده قرار میگیرد.
- در حوزه آموزش، از این مدل برای ایجاد سیستمهای یادگیری شخصیسازیشده و آموزش آنلاین استفاده میشود.
- در صنعت فناوری اطلاعات، DeepSeek-V3 در توسعه چتباتها، ابزارهای پردازش زبان و خدمات پشتیبانی هوشمند کاربرد دارد.
- بخش پزشکی نیز از قابلیتهای DeepSeek-V3 برای تحلیل دادههای پیچیده و ارائه پیشنهادات درمانی استفاده میکند.
پتانسیلهای توسعه و بهبود در آینده
با وجود دستاوردهای کنونی، تیم DeepSeek به دنبال گسترش قابلیتها و ارتقاء عملکرد مدلهای خود است. برنامههای آینده شامل موارد زیر است:
- افزایش کارایی معماری مدل: تلاش برای کاهش محدودیتهای موجود در معماری Transformer و ارائه مدلهایی با قابلیت پردازش متون بلندتر.
- افزایش تنوع دادههای آموزشی: گسترش منابع داده و استفاده از سیگنالهای آموزشی جدید برای بهبود کیفیت آموزش.
- توسعه قابلیتهای استدلال عمیق: افزایش توانایی مدلها در حل مسائل پیچیده و افزایش طول و عمق استدلالها.
- ارزیابی جامعتر مدلها: ایجاد روشهای ارزیابی چندبعدی برای پیشگیری از بهینهسازی صرفاً بر اساس معیارهای خاص و ارزیابی توانمندیهای واقعی مدل.
DeepSeek با تمرکز بر توسعه مداوم و استفاده از تکنیکهای نوآورانه، در مسیر تحقق اهداف خود در زمینه هوش مصنوعی عمومی (AGI) گام برمیدارد.
عملکرد برجسته هوش مصنوعی دیپ سیک DeepSeek
DeepSeek-R1 با عملکردی همتراز با مدلهای پیشرفتهای نظیر OpenAI-o1، به عنوان یک مدل متنباز (open-source) و پیشرو در حوزه هوش مصنوعی عرضه شده است. این مدل، که تحت مجوز MIT منتشر شده، ابزار قدرتمندی برای پژوهشگران و کسبوکارها فراهم میکند تا به راحتی از وزنها و خروجیهای مدل استفاده کنند یا آنها را برای نیازهای خود سفارشیسازی کنند.
مدل هوش مصنوعی دیپ سیک DeepSeek با استفاده از تکنیکهای پیشرفته نظیر تقطیر مدلها توانسته است مدلهای کوچکتر و مقرونبهصرفهای ارائه دهد که همچنان در وظایف پیچیدهای مانند حل مسائل ریاضی، برنامهنویسی و استدلال برتری دارند. این کار در شرایطی انجام شده که چین با محدودیتهای سختگیرانه در دسترسی به تراشههای پیشرفته آمریکا، مانند Nvidia H100، روبهرو بوده است.
پاسخ جامعه جهانی
ساتیا نادلا، مدیرعامل مایکروسافت، در مجمع جهانی اقتصاد در داووس این مدل را “بسیار تأثیرگذار” توصیف کرده و اظهار داشت: «توسعههای هوش مصنوعی دیپ سیک DeepSeek را باید بسیار جدی گرفت.» این موفقیت نشاندهنده پیشرفتی مهم برای جامعه هوش مصنوعی چین است که تحت فشار محدودیتهای صادراتی، به نوآوریهای کارآمدتری دست یافتهاند.
چالشهای جهانی و فرصتهای جدید
ظهور هوش مصنوعی دیپ سیک DeepSeek و مدلهای مشابه، نه تنها نشاندهنده کاهش هزینهها و افزایش بهرهوری در توسعه هوش مصنوعی است، بلکه رقابتی جدید را میان شرکتهای بزرگ فناوری و آزمایشگاههای مستقل ایجاد کرده است. این رقابت میتواند مرزهای پیشرفت در این حوزه را جابهجا کند و پرسشهای جدیدی درباره آینده این صنعت مطرح نماید.
DeepSeek با این دستاورد، نشان داده است که در دنیای هوش مصنوعی، نوآوری و بهرهوری میتواند فراتر از منابع مالی و سختافزاری عمل کند.
۸. ویژگیهای برجسته هوش مصنوعی دیپ سیک
- متنباز و شفاف: DeepSeek-R1 به همراه گزارش فنی کامل، برای بررسی و استفاده در دسترس جامعه قرار گرفته است.
- پلتفرم کاربردی: وبسایت و API این مدل اکنون فعال هستند و از طریق chat.deepseek.com میتوانید DeepThink را بررسی کنید.
- مدلهای کوچکتر، عملکرد بالا: نسخههای تقطیر شده این مدل شامل ۶ مدل کوچکتر (32B و 70B) هستند که با OpenAI-o1-mini رقابت میکنند.
کاربردها
- 🔐 ورود آسان: ایمیل/حساب جیمیل/Apple ID
- ☁️ همگام سازی تاریخچه چت بین پلتفرمی
- 🔍 جستجوی وب و حالت Deep-Think
- 📄 آپلود فایل و استخراج متن
۹. نکات فنی هوش مصنوعی دیپ سیک
- بهبود عملکرد با RL پس از آموزش: استفاده از یادگیری تقویتی در مراحل پس از آموزش، موجب افزایش کارایی مدل شده است.
- توانایی بالا در وظایف محاسباتی و استدلالی: DeepSeek-R1 در حل مسائل ریاضی، کدنویسی و استدلال به خوبی عمل میکند.
- جزئیات بیشتر: گزارش فنی را مطالعه کنید.
۱۰. مزیتهای استفاده از DeepSeek-R1
- مجوز MIT: قابلیت استفاده آزادانه برای مقاصد تجاری و غیربازرگانی.
- دسترسی به API: امکان استفاده از خروجیهای مدل برای تقویت و سفارشیسازی مدلهای دیگر.
- هزینه مقرونبهصرفه: قیمتگذاری شفاف برای دسترسی به API:
- $۰.۱۴ به ازای هر یک میلیون توکن ورودی (در صورت cache hit)
- $۰.۵۵ به ازای هر یک میلیون توکن ورودی (در صورت cache miss)
- $۲.۱۹ به ازای هر یک میلیون توکن خروجی
جامعه متنباز، مرزهای هوش مصنوعی را گسترش میدهد
DeepSeek-R1 با ارائه مدلهایی قدرتمند و مقرونبهصرفه، جامعه متنباز را توانمند میکند و زمینهساز پیشرفتهای بیشتر در حوزه هوش مصنوعی میشود. این مدل گامی مهم در جهت تحقق رؤیای هوش مصنوعی باز و در دسترس برای همه است.
۱۱. نتیجهگیری
جمعبندی دستاوردها و تأثیرات DeepSeek
مدل DeepSeek-V3 با بهرهگیری از معماری پیشرفته ترکیب کارشناسان (MoE) و فناوریهای نوین نظیر توجه نهفته چندسری (MLA) و آموزش با دقت FP8، به یکی از قدرتمندترین مدلهای متنباز موجود تبدیل شده است. این مدل با بهرهگیری از ۱۴.۸ تریلیون توکن آموزشی، توانسته عملکردی قابلمقایسه با مدلهای پیشرفته بسته مانند GPT-4o و Claude-Sonnet 3.5 ارائه دهد.
دیپسیک نه تنها در آزمونهای مرتبط با کدنویسی و ریاضی پیشتاز بوده است، بلکه در مدیریت هزینهها و کارایی آموزش نیز نوآوریهای قابلتوجهی به کار گرفته است. با هزینهای معادل ۵.۵۷۶ میلیون دلار و استفاده از ۲.۷۸۸ میلیون ساعت GPU مدل H800، این مدل توانسته است اقتصادیترین فرایند آموزش در میان مدلهای بزرگ را رقم بزند.
چشمانداز آینده و نقش آن در توسعه هوش مصنوعی
دیپسیک با تمرکز بر متنباز بودن و اهداف بلندمدت، گامی بزرگ به سمت تحقق هوش عمومی مصنوعی (AGI) برداشته است. برنامههای آینده شامل:
- ارتقاء معماری مدلها: هدف بهبود کارایی در آموزش و استنتاج، پشتیبانی از طول متنهای بینهایت و توسعه فراتر از محدودیتهای معماری فعلی.
- گسترش دادههای آموزشی: افزایش تنوع و کیفیت دادهها با استفاده از منابع آموزشی جدید.
- تقویت تواناییهای استدلال عمیق: گسترش طول و عمق استدلال مدلها برای حل مسائل پیچیدهتر.
- ارزیابی چندبعدی مدلها: ایجاد روشهایی برای جلوگیری از تمرکز بیشازحد بر معیارهای خاص و دستیابی به دیدگاه جامعتر از تواناییهای مدل.
دیپسیک با تداوم مسیر پیشرفت و بهرهگیری از نوآوریهای تکنولوژیکی، میتواند نقش کلیدی در توسعه هوش مصنوعی ایفا کند و مرزهای عملکرد مدلهای متنباز را گسترش دهد.
مقاله انگلیسی مدل دیپ سیک DeepSeek
رسانه تخصصی هوش مصنوعی سیمرغ
مجله تخصصی هوش مصنوعی,سایت هوش مصنوعی,Gemini1.5 pro,GPT 4o,Leonardo AI,krea ai,Claude,آهنگ با هوش مصنوعی,ساخت عکس با هوش مصنوعی,سوال از هوش مصنوعی,مجله هوش مصنوعی، پایگاه خبری هوش مصنوعی سیمرغ، رسانه رسمی هوش مصنوعی