



فهرست دسترسی سریع
۱. مقدمه
نقش لایههای Fully Connected در شبکههای عصبی
لایههای کاملاً متصل یا Fully Connected (که در بسیاری از چارچوبهای یادگیری عمیق با عنوان Dense Layer نیز شناخته میشوند) بخش جداییناپذیر از معماری شبکههای عصبی مصنوعی (ANN) بهشمار میروند. این لایهها در قلب بسیاری از سیستمهای یادگیری قرار دارند و وظیفهی ترکیب غیرخطی ویژگیها را بر عهده دارند.
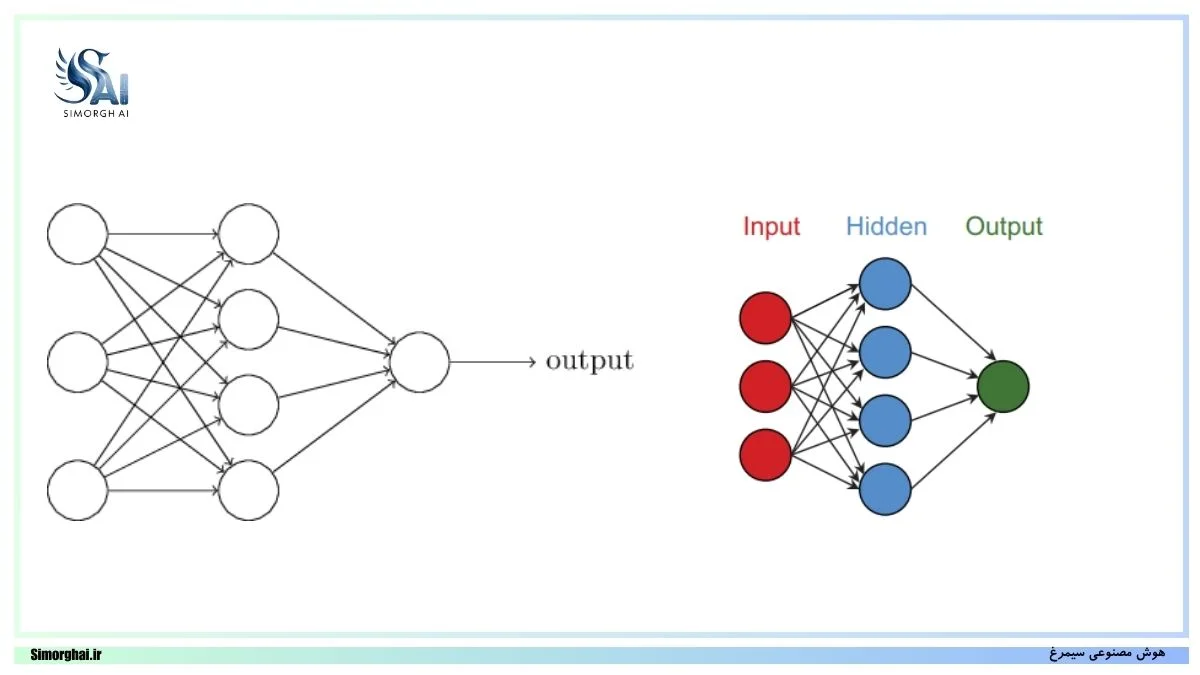
در لایه Fully Connected، هر نورون به تمامی نورونهای لایه قبلی متصل است؛ بدین ترتیب، این لایه حداکثر ظرفیت مدلسازی روابط پیچیده بین ویژگیها را دارد. این ارتباط کامل باعث میشود تا مدل بتواند الگوهای غیرخطی و انتزاعی را فرا بگیرد، که برای وظایف با پیچیدگی بالا همچون طبقهبندی تصویر یا تشخیص زبان ضروری است.
مرور کلی کاربردها در بینایی ماشین و دستهبندی
در حوزه بینایی ماشین (Computer Vision)، لایههای Fully Connected معمولاً پس از چندین لایه کانولوشنی و pooling قرار میگیرند تا ویژگیهای استخراجشده را برای تصمیمگیری نهایی ترکیب و تفسیر کنند. برای مثال، در یک شبکه کانولوشنی کلاسیک مانند LeNet یا AlexNet، لایههای کانولوشنی وظیفه استخراج ویژگیهای مکانی-محلی را دارند، در حالی که لایههای Fully Connected در انتهای شبکه قرار میگیرند تا این ویژگیها را به خروجی نهایی مانند برچسب کلاس نگاشت کنند.
همچنین در شبکههای چندلایهی پرسپترونی (MLP)، که فاقد ساختارهای خاص مکانی هستند، لایههای Fully Connected نقش اصلی را در نگاشت ورودی به خروجی بازی میکنند و برای مسائل طبقهبندی ساده، رگرسیون و پیشبینی مورد استفاده قرار میگیرند. انعطافپذیری این لایهها در مدلسازی توابع پیچیده، آنها را به انتخابی مناسب برای بسیاری از کاربردهای یادگیری نظارتشده تبدیل کرده است.
۲. ساختار لایه Fully Connected
تعریف نورون و لایه Fully Connected
در معماری شبکههای عصبی مصنوعی، لایه Fully Connected (به اختصار FC) یکی از اصلیترین اجزای مدل بهشمار میرود. این لایه از مجموعهای از نورونها تشکیل شده است که هر نورون در آن به تمام نورونهای لایه قبلی متصل است. این اتصال کامل به مدل این امکان را میدهد تا روابط پیچیده و غیرخطی میان ویژگیهای ورودی را یاد بگیرد.


در سادهترین حالت، یک نورون در لایه Fully Connected، ورودیهای خود را بهصورت ترکیبی خطی از مقادیر لایه قبل دریافت میکند. این ترکیب بهصورت مقابل تعریف میشود:
که در آن:
- x بردار ورودی،
- w بردار وزنهای قابل آموزش،
- و b بایاس نورون است.

سپس با اعمال یک تابع فعالسازی (مانند ReLU، Sigmoid یا Tanh) به مقدار z خروجی نورون بهدست میآید.
ارتباط کامل بین نورونها
در یک لایه Fully Connected با m نورون در لایه قبلی و n نورون در لایه جاری، مجموعاً m×n وزن و n بایاس قابل یادگیری وجود دارد. این یعنی لایه FC معمولاً بیشترین تعداد پارامترها را در کل شبکه داراست، و از این رو مهمترین منبع ظرفیت مدل و در عین حال منبع بالقوهی بیشبرازش (overfitting) محسوب میشود.
برای مثال، اگر لایهای با ۷۸۴ نورون ورودی (مانند تصویر ۲۸×۲۸ پیکسل) و ۱۲۸ نورون در لایه FC داشته باشیم، آنگاه تعداد پارامترها برابر است با:
۷۸۴×۱۲۸+۱۲۸=۱۰۰۴۸۰
این پارامترها باید طی فرایند آموزش از داده یاد گرفته شوند، و نقش کلیدی در نگاشت ورودی به خروجی ایفا میکنند.
لایه Fully Connected در قالب ماتریسی
به منظور بهینهسازی پیادهسازی و بهرهگیری از قدرت محاسباتی موازی، معمولاً محاسبات FC بهشکل ماتریسی انجام میشود. اگر ورودی x یک بردار ۱×m و وزنها در قالب ماتریس W∈Rm×n باشند، خروجی لایه FC از رابطهی زیر محاسبه میشود:
y=ϕ(x⋅W+b)
که در آن b بردار بایاس و ϕ تابع فعالسازی اعمالشده بهصورت عنصری (element-wise) است.
۳. روابط ریاضی در لایه Fully Connected
وزنها، بایاس و ضرب نقطهای
در لایه Fully Connected، محاسبات اصلی مبتنی بر اعمال یک ضرب نقطهای (Dot Product) بین ورودیها و وزنهای هر نورون است. هر نورون در این لایه، یک بردار وزن w دارد که به تمامی خروجیهای لایه قبلی متصل است. بهعلاوه، یک بایاس b نیز به هر نورون اختصاص داده میشود که به عنوان مقدار ثابتی به مجموع ورودی اضافه میشود.

اگر ورودی به لایه را x=[x1,x2,…,xn] و وزنهای نورون را w=[w۱,w۲,…,wn] در نظر بگیریم، خروجی اولیه نورون (پیش از اعمال تابع فعالسازی) به صورت زیر محاسبه میشود:
این فرمول نشان میدهد که هر نورون نقش یک ترکیب خطی از ورودیها را ایفا میکند، و توانایی مدل در یادگیری روابط پیچیده از طریق تنظیم مناسب این ضرایب حاصل میشود.
محاسبه مجموع ورودی و اعمال تابع فعالسازی
برای افزایش ظرفیت غیرخطی شبکه و مدلسازی توابع پیچیده، خروجی خطی zzz از هر نورون به یک تابع فعالسازی (Activation Function) اعمال میشود. این تابع معمولاً یک نگاشت غیرخطی مانند ReLU، Sigmoid یا Tanh است و خروجی نهایی نورون را مشخص میکند:

در اینجا:
- ϕ تابع فعالسازی انتخابشده،
- a خروجی نهایی نورون است.
برای مثال، اگر از تابع ReLU استفاده شود، خروجی بهصورت زیر خواهد بود:
a=max(۰,z)

در ساختار ماتریسی، اگر لایهای شامل چندین نورون باشد و بخواهیم خروجی کل لایه را با یک معادله توصیف کنیم، میتوان نوشت:

که:
این روابط ریاضی پایهی یادگیری مدل هستند و طی فرآیند آموزش، مقادیر وزنها و بایاسها به گونهای تنظیم میشوند که خروجی شبکه به بهترین شکل ممکن با اهداف مورد نظر همراستا گردد.
۴. بردارسازی محاسبات (Vectorization)
استفاده از ضرب ماتریسی برای افزایش بهرهوری محاسباتی
در شبکههای عصبی، بهویژه در لایههای Fully Connected، انجام محاسبات برای هر نورون بهصورت جداگانه (با حلقههای for) بسیار کند و ناکارآمد است. بردارسازی یا Vectorization به معنای بازنویسی این محاسبات بهگونهای است که با استفاده از عملیات ماتریسی بتوان آنها را همزمان و با سرعت بسیار بالاتری انجام داد.
ایده اصلی این است که به جای پردازش هر ورودی و نورون بهصورت جداگانه، ورودیها را در قالب یک بردار و وزنها را در قالب یک ماتریس قرار دهیم، و خروجی کل لایه را با یک ضرب ماتریس محاسبه کنیم. این روش امکان استفاده مؤثر از سختافزارهای بردارگرا مانند GPU را فراهم میکند.

فرمول ریاضی آن بهصورت زیر است:
که:
- X ماتریس ورودی (مثلاً از چند نمونه در یک batch)
- W ماتریس وزنها برای لایه Fully Connected
- b بردار بایاسها (broadcast میشود روی سطرها)
- ϕ تابع فعالسازی (مثلاً ReLU)
- Y خروجی لایه برای کل batch
مثال عددی برای درک بهتر
فرض کنید میخواهیم یک لایه FC را برای دو تصویر ورودی (batch size = 2) اجرا کنیم. هر تصویر پس از Flatten شدن به برداری با ۳ ویژگی تبدیل شده و لایه FC ما دارای ۲ نورون است.
- ماتریس ورودی (دو نمونه، هرکدام با ۳ ویژگی):

- ماتریس وزنها (۳ ورودی × ۲ نورون):

بردار بایاس:
b=[0.1,0.2]
ابتدا ضرب ماتریسی X⋅W را محاسبه میکنیم:

حال بایاس را اضافه میکنیم

در نهایت با اعمال تابع فعالسازی (مثلاً ReLU):

نتیجه نهایی، خروجی لایه Fully Connected برای هر دو نمونه ورودی است.
۵. تابع فعالسازی در لایههای Fully Connected
معرفی ReLU و دیگر توابع رایج
در شبکههای عصبی، پس از محاسبه مجموع وزندار ورودیها به هر نورون، نیاز است که یک تابع فعالسازی (Activation Function) بر روی این مجموع اعمال شود. این تابع وظیفه دارد که مشخص کند خروجی نورون چه مقدار باشد و چگونه به مرحله بعدی منتقل شود.
رایجترین توابع فعالسازی که در لایههای Fully Connected استفاده میشوند عبارتاند از:
- ReLU (Rectified Linear Unit)
سادهترین و محبوبترین تابع، که خروجی آن برابر است با: ReLU(x)=max(۰,x)
این تابع مقدارهای منفی را حذف میکند و فقط مقدارهای مثبت را عبور میدهد. سرعت اجرا بالا و عدم اشباع در مقدارهای مثبت باعث شده ReLU در بسیاری از مدلهای امروزی مانند VGG و ResNet مورد استفاده قرار گیرد. - Sigmoid
خروجی را به بازه بین ۰ تا ۱ محدود میکند:
در گذشته کاربرد زیادی در لایههای FC داشت، اما بهدلیل مشکل اشباع (vanishing gradients) در شبکههای عمیق، امروزه کمتر استفاده میشود.

- Tanh
خروجی را بین -۱ تا +۱ محدود میکند:
نسبت به سیگموید عملکرد بهتری دارد چون میانگین خروجی آن صفر است

- Softmax
اغلب در لایه آخر شبکه برای دستهبندی چندکلاسه استفاده میشود. خروجی آن یک بردار احتمال است که جمع عناصر آن برابر ۱ است.
اهمیت غیرخطیسازی خروجی
اگر در تمام لایههای شبکه فقط از توابع خطی (مثل ضرب ماتریس و جمع بایاس) استفاده کنیم، شبکه در نهایت معادل یک تابع خطی ساده خواهد بود — حتی اگر تعداد زیادی لایه داشته باشیم. این یعنی:
بدون توابع غیرخطی، شبکه نمیتواند روابط پیچیده و غیرخطی در دادهها را مدلسازی کند.
استفاده از توابع فعالسازی مانند ReLU باعث میشود شبکه بتواند:
- ویژگیهای پیچیدهتر و معنادارتر استخراج کند،
- مرزهای تصمیمگیری غیرخطی ایجاد کند (برای دستهبندی دقیقتر)،
- و یادگیری مؤثرتری انجام دهد.
در فایل ارسالی نیز بهوضوح تأکید شده است که تابع فعالسازی، همانند وزن و بایاس، یک بخش حیاتی از تعریف کامل یک نورون در لایه Fully Connected محسوب میشود.
۶. شبکههای چند لایه (MLP)
اتصال چندین لایه Fully Connected برای مدلسازی روابط پیچیده
وقتی چندین لایه Fully Connected (FC) بهصورت پشتسرهم به یکدیگر متصل شوند و بین آنها توابع فعالسازی غیرخطی قرار گیرد، ساختاری شکل میگیرد که به آن شبکه عصبی چند لایه (Multi-Layer Perceptron یا MLP) گفته میشود.
در چنین شبکهای:
- هر نورون در یک لایه به تمام نورونهای لایه قبلی متصل است (fully connected).
- هر لایه اطلاعات را از لایه قبلی دریافت کرده و پس از اعمال وزن، بایاس و تابع فعالسازی، آن را به لایه بعدی منتقل میکند.
- این اتصالهای چندلایهای امکان یادگیری روابط بسیار پیچیده و غیرخطی در دادهها را فراهم میکند.
MLP یکی از سادهترین اما قدرتمندترین ساختارها در یادگیری عمیق است و اساس بسیاری از مدلهای پیشرفتهتر (مثل شبکههای کانولوشنی یا بازگشتی) را تشکیل میدهد.
بررسی خروجی و الگوریتم پسانتشار (Backpropagation) در چند لایه
برای یادگیری مؤثر در شبکههای چند لایه، از الگوریتمی بهنام پسانتشار خطا (Backpropagation) استفاده میشود. فرآیند کلی آن به شکل زیر است:
- پیشرو (Forward Pass):
داده ورودی از طریق لایههای FC عبور کرده و به خروجی نهایی میرسد. - محاسبه خطا:
خروجی پیشبینیشده با مقدار واقعی مقایسه میشود و یک تابع هزینه (مانند MSE یا Cross-Entropy) میزان خطا را مشخص میکند. - پسرو (Backward Pass):
خطا به صورت معکوس از خروجی به سمت ورودی منتقل میشود. در این مرحله، با استفاده از مشتقهای زنجیرهای، گرادیانها نسبت به وزنها و بایاسها در هر لایه محاسبه میشوند. - بهروزرسانی پارامترها:
با کمک گرادیانها و الگوریتمهایی مانند Gradient Descent، وزنها و بایاسها طوری بهروزرسانی میشوند که خطا کاهش یابد.
در فایل پیوستشده نیز بهوضوح توضیح داده شده که:
در شبکههای چند لایه، خروجی هر لایه بهعنوان ورودی به لایه بعدی عمل میکند و گرادیانها در جهت معکوس از خروجی نهایی به تمام لایههای قبلی انتشار مییابند.
همچنین به استفاده از کتابخانههای مدرن (مثل PyTorch) برای پیادهسازی ساده و سریع چنین ساختارهایی اشاره شده است.
۷. تعداد پارامترها و پیچیدگی مدل
چگونگی محاسبه تعداد پارامترها در لایههای Fully Connected
در یک لایه Fully Connected (FC)، هر نورون به تمام نورونهای لایه قبل متصل است. بنابراین تعداد پارامترهای قابل یادگیری (که شامل وزنها و بایاسها میشود) بهصورت زیر محاسبه میگردد
یا به بیانی دیگر:
این رابطه ساده بهوضوح در فایل نیز آمده و نشان میدهد که با بزرگتر شدن لایهها، بهسرعت تعداد پارامترها افزایش مییابد.
پیامدهای افزایش پارامترها (Overfitting و مصرف منابع)
افزایش تعداد پارامترها، به معنای افزایش توان مدل برای یادگیری الگوهای پیچیدهتر است. اما این مسئله پیامدهایی دارد:
- Overfitting (بیشبرازش):
وقتی تعداد پارامترها زیاد باشد، مدل بهجای یادگیری الگوهای کلی و مفید، ممکن است دادههای آموزشی را «حفظ» کند. در نتیجه، عملکرد آن روی دادههای جدید (آزمایشی) کاهش مییابد. - افزایش مصرف منابع:
مدلهای بزرگتر به حافظه و زمان محاسباتی بیشتری نیاز دارند، بهویژه در هنگام آموزش. - نیاز به داده بیشتر:
هرچه مدل پیچیدهتر باشد، برای آموزش مؤثر به مجموعه دادههای بزرگتری نیاز دارد. در غیر اینصورت احتمال overfitting بیشتر میشود.
فایل ارسالی به خوبی این نکته را یادآور میشود که در شبکههایی مثل Fully Connected، «پارامترهای فراوان باعث افزایش ریسک بیشبرازش میشوند و لازم است بهکمک تکنیکهایی مثل dropout یا regularization آن را کنترل کرد.»
۸. کاربردهای FC در معماریهای مدرن
لایههای Fully Connected در انتهای شبکههای عصبی کانولوشنی (CNN)
در معماریهای مدرن شبکههای عصبی، مانند LeNet، AlexNet و VGG، معمولاً از ترکیبی از لایههای کانولوشنی (Convolutional Layers)، لایههای pooling و در پایان از چند لایه Fully Connected (FC) استفاده میشود. در این ساختارها:
- لایههای ابتدایی مسئول استخراج ویژگیهای محلی (مثل لبهها، بافتها و الگوها) هستند.
- و لایههای Fully Connected در انتهای شبکه، این ویژگیها را تجمیع و تفسیر میکنند تا در نهایت به تصمیمگیری (مثلاً تشخیص کلاس تصویر) منجر شوند.
فایل پیوستشده به وضوح توضیح میدهد که چگونه FC بهعنوان یک «طبقهبند نهایی» عمل میکند که خروجی ویژگیهای استخراجشده را به بردار نهایی کلاسها تبدیل میکند.
فرایند Flatten کردن دادهها برای ورود به لایه FC
از آنجایی که خروجی لایههای کانولوشنی بهصورت تنسورهای چندبعدی (مثلاً ۷×۷×۵۱۲) هستند، برای ورود این خروجیها به لایههای Fully Connected که فقط با بردارهای یکبعدی کار میکنند، باید آنها را صاف (flatten) کرد.
به زبان ساده:
- یک تصویر یا ویژگی چندبعدی به یک بردار طولانی یکبعدی تبدیل میشود.
- سپس این بردار وارد لایه FC میشود تا عملیات وزندهی و فعالسازی روی آن انجام گیرد.
اهمیت این ترکیب
این ساختار ترکیبی (CNN + FC) باعث میشود شبکه:
- هم ویژگیهای محلی را با دقت استخراج کند،
- و هم با استفاده از FC، بتواند درک کلی و انتزاعیتری از تصویر بهدست آورد.
FC بخش جداییناپذیر انتهایی بسیاری از معماریهای شناختهشده است و اغلب برای تصمیمگیری نهایی در دستهبندی استفاده میشود.
۹. محدودیتها و چالشها
۱. تعداد زیاد پارامترها در لایههای Fully Connected
یکی از مهمترین چالشهای لایههای FC، تعداد بسیار زیاد پارامترها است. برخلاف لایههای کانولوشنی که با تعداد محدودی فیلتر کار میکنند، در FC هر نورون به تمام نورونهای لایه قبلی متصل است. این یعنی:
- اگر لایه قبلی دارای ۴۰۹۶ نورون و لایه FC نیز ۴۰۹۶ نورون باشد، شبکه باید بیش از ۱۶ میلیون پارامتر (وزن) را یاد بگیرد!
- این افزایش شدید در تعداد پارامترها منجر به حافظه زیاد و زمان آموزش طولانی میشود.
در فایل پیوست نیز با ذکر فرمول دقیق تعداد پارامترها (تعداد وزنها + بایاسها) به این موضوع تأکید شده است.
۲. وابستگی شدید به دادههای زیاد
به دلیل وجود تعداد زیادی پارامتر، لایههای FC نیاز به حجم زیادی از داده برای آموزش دارند. در غیر این صورت:
- مدل دچار overfitting میشود؛ یعنی بهجای یادگیری الگوهای کلی، فقط دادههای آموزش را حفظ میکند.
- شبکه نمیتواند بهخوبی تعمیم یابد و روی دادههای جدید عملکرد ضعیفی دارد.
فایل PDF اشاره میکند که در پروژههایی با دادههای محدود، استفاده مستقیم از چندین لایه FC میتواند خطرناک باشد.
۳. نیاز به تنظیم دقیق هایپرپارامترها
لایههای FC بسیار حساس به انتخاب هایپرپارامترها هستند. برخی از این پارامترها عبارتاند از:
- تعداد نورونها در هر لایه FC
- نوع تابع فعالسازی (مانند ReLU یا Sigmoid)
- نرخ یادگیری (Learning Rate)
- روشهای منظمسازی (مثل Dropout یا L2 regularization)
اگر این پارامترها بهدرستی تنظیم نشوند، مدل ممکن است یا آموزش نبیند (underfitting) یا بیشازحد به داده وابسته شود.
این محدودیتها باعث شدهاند که در سالهای اخیر، برخی معماریهای مدرن مانند GoogleNet، ResNet و MobileNet از لایههای Fully Connected صرفنظر کرده و بهجای آن از Global Average Pooling استفاده کنند تا پیچیدگی مدل کاهش یابد.
۱۰. جمعبندی و نتیجهگیری
نقش کلیدی لایه Fully Connected در ترکیب ویژگیها
لایههای Fully Connected (FC) یکی از مهمترین اجزای شبکههای عصبی مصنوعی به شمار میآیند. این لایهها، برخلاف لایههای کانولوشنی یا pooling که بیشتر به استخراج ویژگیها از دادهها میپردازند، مسئولیت ترکیب نهایی این ویژگیها و اتخاذ تصمیم نهایی (مانند دستهبندی یا پیشبینی) را بر عهده دارند.
- FC مانند یک جمعبند منطقی عمل میکند که همهی ویژگیهای استخراجشده را در نظر میگیرد و خروجی نهایی را تولید میکند.
- اهمیت این لایه زمانی بیشتر میشود که بدانیم حتی شبکههای پیچیدهای مانند CNN، در پایان به FC برای اتخاذ تصمیم نهایی متکی هستند.
جایگاه لایه FC در معماریهای یادگیری عمیق
بر اساس توضیحات دقیق فایل، لایه Fully Connected معمولاً در بخش انتهایی مدلهای یادگیری عمیق قرار دارد و دادههای پردازششده را از حالت چندبعدی به یک بردار خطی (flat) تبدیل میکند تا امکان استفاده از عملیات برداری و ضرب ماتریسی فراهم شود.
- در شبکههای کانولوشنی، پس از لایههای استخراج ویژگی، معمولاً دادهها توسط عملیات flatten به لایه FC وارد میشوند.
- FC همچنین نقش مهمی در مدلسازی روابط غیرخطی پیچیده دارد، بهویژه در معماریهای چندلایه (MLP).
نگاه رو به آینده
اگرچه در برخی معماریهای جدید تلاش شده استفاده از لایه FC کاهش یابد یا با روشهایی مانند Global Average Pooling جایگزین شود، اما نقش ساختاری و تحلیلی آن هنوز بسیار مهم است، بهویژه در کاربردهایی که دقت نهایی مدل اولویت دارد.
در مجموع، لایه Fully Connected در قلب فرآیند تصمیمسازی مدلهای یادگیری عمیق قرار دارد و درک دقیق عملکرد آن برای طراحی معماریهای بهینه ضروری است.
