
 | تاریخچه؛ مزایا؛ آموزش نصب")
هوش مصنوعی جی پی تی ۵ در اوج: بررسی جامع قابلیتها، عملکرد و آینده GPT-5
جدول محتواها
۱. چکیده
GPT-5، جدیدترین و پیشرفتهترین مدل زبانی بزرگ (LLM) از OpenAI، گامی چشمگیر در مسیر هوش مصنوعی عمومی (AGI) محسوب میشود. این مدل با معرفی معماری یکپارچه که شامل یک “روتر هوشمند” و قابلیت “تفکر عمیق” است، عملکرد بیسابقهای را در حوزههای کلیدی نظیر کدنویسی، ریاضیات، نگارش خلاقانه و سلامت به نمایش میگذارد. نوآوریهای فنی در GPT-5 به آن امکان میدهد تا وظایف پیچیده را با دقت و کارایی بینظیری انجام دهد، از تولید کدهای فرانتاند با درک زیباییشناختی تا حل مسائل ریاضی در سطح المپیاد و ارائه مشاوره فعال در حوزه سلامت.
علاوه بر پیشرفتهای چشمگیر در قابلیتهای شناختی، OpenAI تمرکز ویژهای بر افزایش قابلیت اطمینان و ایمنی مدل داشته است. کاهش قابل توجه نرخ توهم و فریب، همراه با معرفی رویکرد جدید “تکمیلهای ایمن”، بر تعهد این شرکت به توسعه مسئولانه هوش مصنوعی تأکید دارد. این رویکرد جدید، مدل را قادر میسازد تا در سناریوهای دوکاربردی پیچیده، مفیدترین پاسخ را در چارچوب مرزهای ایمنی ارائه دهد. همچنین، قابلیتهای شخصیسازی پیشرفته و حافظه پایدار، تجربه کاربری را به سطحی بیسابقه ارتقا میبخشد.
این مقاله به تحلیل جامع نوآوریهای فنی، ارزیابیهای عملکردی بر اساس بنچمارکهای معتبر، کاربردهای عملی، و ملاحظات ایمنی GPT-5 میپردازد. بررسی چالشهای اولیه و چشمانداز آینده این مدل، مسیر پیش رو برای توسعه AGI و تأثیرات گسترده آن بر صنایع و جامعه را ترسیم میکند. این تحلیل عمیق، درک جامعی از جایگاه GPT-5 در اکوسیستم هوش مصنوعی و پتانسیل آن برای بازتعریف تعامل انسان با فناوری را فراهم میآورد.

۲. مقدمه
۲.۱. تکامل مدلهای زبانی بزرگ (LLMs) و اهمیت آنها
مدلهای زبانی بزرگ (LLMs) در سالهای اخیر به سرعت در حال تکامل بودهاند و از ابزارهایی صرفاً برای پردازش زبان طبیعی به سیستمهای هوش مصنوعی چندوجهی و توانمند تبدیل شدهاند. این مسیر پرشتاب، با ظهور مدلهایی نظیر GPT-3 و GPT-4 از OpenAI، آغازگر تحولی عمیق در نحوه تعامل انسان با فناوری و انجام وظایف پیچیده بوده است.۱ در ابتدا، LLMها عمدتاً بر تولید متن و درک زبان متمرکز بودند، اما با هر نسل جدید، قابلیتهای آنها در استدلال، حل مسئله و تعامل با دادههای غیرمتنی به طور چشمگیری افزایش یافته است. این پیشرفتها، کاربردهای LLMها را از پاسخگویی به سوالات ساده و تولید محتوا به حوزههای پیچیدهتری مانند کدنویسی، تحلیل دادههای علمی و حتی مشاوره تخصصی گسترش داده است.
اهمیت LLMها در تحول صنایع مختلف غیرقابل انکار است. در بخش خدمات مشتری، این مدلها به بهبود کارایی و کیفیت پاسخگویی کمک میکنند؛ در حوزه تولید محتوا، فرآیندهای خلاقانه را تسریع میبخشند؛ و در توسعه نرمافزار، به عنوان دستیاران هوشمند عمل میکنند که قادر به تولید و اشکالزدایی کد هستند. این مدلها به سرعت در حال تبدیل شدن به ابزارهای کلیدی برای افزایش بهرهوری و نوآوری در تمامی بخشهای اقتصادی هستند. رقابت فشرده میان شرکتهای پیشرو در حوزه هوش مصنوعی، مانند OpenAI و Google، منجر به سرعت بالای نوآوری و ظهور مدلهای پیشرفتهتر در فواصل زمانی کوتاه شده است. این رقابت، نه تنها مرزهای قابلیتهای هوش مصنوعی را جابجا میکند، بلکه انتظارات عمومی را از آنچه هوش مصنوعی میتواند انجام دهد، افزایش میدهد. در این بستر، نیاز به مدلهایی که نه تنها قدرتمندتر باشند، بلکه قابل اعتمادتر و ایمنتر نیز عمل کنند، بیش از پیش احساس میشود. این نیاز به قابلیتهای استدلالی عمیقتر، کاهش خطاها و تعاملات طبیعیتر، زمینهساز ظهور نسل جدیدی از LLMها شده است.
۲.۲. معرفی GPT-5: گام بعدی در هوش مصنوعی
در پاسخ به این نیازهای فزاینده و با هدف پیشبرد مرزهای هوش مصنوعی، OpenAI در ۷ آگوست ۲۰۲۵ مدل GPT-5 را معرفی کرد.۱ این مدل به عنوان “هوشمندترین، سریعترین و مفیدترین سیستم هوش مصنوعی” OpenAI تا به امروز توصیف شده است.۱ معرفی GPT-5 یک جهش قابل توجه در هوش عمومی مدلهای زبانی محسوب میشود که فراتر از صرفاً بهبودهای افزایشی است و نشاندهنده یک تغییر پارادایم در قابلیتهای هوش مصنوعی است. یکی از برجستهترین ویژگیهای GPT-5، قابلیت “تفکر داخلی” (built-in thinking) است که به آن امکان میدهد “طولانیتر فکر کند” و پاسخهای در سطح متخصص (expert-level responses) ارائه دهد.۱ این قابلیت، هوش تخصصی را در دسترس همگان قرار میدهد و دلالت بر دموکراتیکسازی دانش و تواناییهای پیچیده دارد. این امر میتواند تأثیر عمیقی بر آموزش، دسترسی به اطلاعات تخصصی، و حتی نحوه انجام کار در بسیاری از مشاغل داشته باشد. به عنوان مثال، یک دانشجو میتواند به راهنماییهای در سطح یک استاد دانشگاه دسترسی پیدا کند، یا یک کارآفرین کوچک میتواند از مشاوره در سطح یک متخصص حقوقی یا مالی بهرهمند شود.
با عرضه GPT-5، این مدل به عنوان مدل پیشفرض در ChatGPT جایگزین تمامی مدلهای قبلی OpenAI، از جمله GPT-4o، OpenAI o3، OpenAI o4-mini، GPT-4.1 و GPT-4.5 برای کاربران وارد شده شده است.۱ این اقدام نشاندهنده اعتماد OpenAI به برتری و کارایی GPT-5 در طیف وسیعی از کاربردها و تعاملات روزمره است. این تغییر، دسترسی به قابلیتهای پیشرفته هوش مصنوعی را برای میلیونها کاربر در سراسر جهان تسهیل میکند. این دموکراتیکسازی دسترسی به هوش مصنوعی پیشرفته، پیامدهای گسترده اجتماعی و اقتصادی دارد. از یک سو، میتواند به کاهش شکافهای دانشی و افزایش فرصتها برای افراد و کسبوکارهای کوچک کمک کند. از سوی دیگر، این پیشرفتها مسئولیتپذیری توسعهدهندگان را در قبال پیامدهای گسترده اجتماعی، از جمله مسائل مربوط به اخلاق، ایمنی، و تأثیر بر بازار کار، افزایش میدهد. در نتیجه، ظهور GPT-5 نه تنها یک دستاورد فنی است، بلکه نقطه عطفی در بحثهای مربوط به آینده هوش مصنوعی و نقش آن در جامعه محسوب میشود.
۲.۳. هدف و ساختار مقاله
هدف اصلی این مقاله، ارائه یک تحلیل جامع و دقیق از مدل زبانی بزرگ GPT-5 است. این تحلیل شامل بررسی عمیق معماری نوآورانه، قابلیتهای پیشرفته در حوزههای مختلف، ارزیابیهای عملکردی بر اساس بنچمارکهای معتبر و دادهمحور، پیشرفتهای کلیدی در ایمنی و قابلیت اطمینان، و تأثیر آن بر تجربه کاربری خواهد بود. این مقاله با تمرکز بر اطلاعات معتبر و دادههای منتشر شده توسط OpenAI و منابع تخصصی دیگر، به دنبال ارائه یک دیدگاه کارشناسانه و چندلایه از این فناوری پیشرفته است.
ساختار این مقاله به گونهای طراحی شده است که خواننده را در درک عمق موضوع و ابعاد مختلف GPT-5 راهنمایی کند:
- بخش ۳: معماری یکپارچه و نوآوریهای بنیادین GPT-5 به بررسی ساختار درونی مدل، از جمله سیستم یکپارچه، روتر هوشمند و قابلیتهای تفکر عمیق میپردازد.
- بخش ۴: قابلیتهای پیشرفته و کاربردهای عملی به تفصیل کاربردهای GPT-5 در حوزههایی مانند کدنویسی، نگارش خلاقانه، سلامت، استدلال چندوجهی و استفاده از ابزارهای عاملگونه را تشریح میکند.
- بخش ۵: ارزیابی عملکرد و معیارهای بنچمارک دادههای کمی مربوط به عملکرد GPT-5 در بنچمارکهای کلیدی ریاضیات، علوم و مهندسی نرمافزار را ارائه و تحلیل میکند.
- بخش ۶: امنیت، قابلیت اطمینان و تجربه کاربری به پیشرفتهای مدل در کاهش توهم و فریب، رویکرد جدید ایمنی “تکمیلهای ایمن” و قابلیتهای شخصیسازی میپردازد.
- بخش ۷: چالشها و چشمانداز آینده به بررسی انتقادات اولیه و چالشهای فنی، و همچنین مسیر پیش رو برای دستیابی به هوش مصنوعی عمومی (AGI) میپردازد.
- بخش ۸: نتیجهگیری یافتههای اصلی مقاله را جمعبندی کرده و تأثیر کلی GPT-5 بر چشمانداز هوش مصنوعی را بیان میکند.
۳. معماری یکپارچه و نوآوریهای بنیادین GPT-5
۳.۱. سیستم یکپارچه و روتر هوشمند
GPT-5 با معرفی یک معماری سیستمیک جدید، از مدلهای پیشین خود متمایز میشود. این مدل به عنوان یک “سیستم یکپارچه” (unified system) طراحی شده است که هدف آن ارائه هوش مصنوعی کارآمد و سازگار با نیازهای متنوع کاربران است.۱ در هسته این معماری، دو جزء اصلی همکاری میکنند: یک “مدل هوشمند و کارآمد” (smart, efficient model) که برای پاسخگویی به بخش عمدهای از پرسشهای روزمره و کمپیچیدگی طراحی شده است، و یک “مدل استدلال عمیقتر” (deeper reasoning model) که OpenAI آن را “GPT-5 thinking” نامیده و برای حل مسائل دشوارتر و پیچیدهتر به کار میرود.۱ این تفکیک، امکان بهینهسازی منابع محاسباتی را فراهم میآورد، به طوری که برای هر نوع سوال، مناسبترین سطح از توان پردازشی به کار گرفته شود.
عامل کلیدی در این سیستم یکپارچه، وجود یک “روتر بلادرنگ” (real-time router) است.۱ این روتر هوشمند، مسئولیت پویای انتخاب بین مدل کارآمد و مدل تفکر عمیق را بر عهده دارد. تصمیمگیری روتر بر اساس چندین عامل صورت میگیرد: نوع مکالمه (مثلاً یک پرسش ساده یا یک پروژه پیچیده)، پیچیدگی سوال، نیاز به فراخوانی ابزارهای خارجی (مانند مفسر کد یا ابزارهای جستجو)، و نیت صریح کاربر.۱ به عنوان مثال، اگر کاربر در پرامپت خود عبارتی مانند “در مورد این سخت فکر کن” (think hard about this) را به کار ببرد، روتر به طور خودکار مدل تفکر عمیق را فعال میکند تا پاسخ جامعتر و دقیقتری ارائه شود.۱ این رویکرد، تجربه کاربری را به طور قابل توجهی بهبود میبخشد، زیرا کاربر نیازی به انتخاب دستی مدل یا حالتهای مختلف ندارد؛ سیستم به طور هوشمندانه بهترین رویکرد را بر اساس زمینه و نیت کاربر تعیین میکند.
پایداری و بهبود مستمر این سیستم از طریق “آموزش مداوم روتر” تضمین میشود.۱ روتر به طور پیوسته بر اساس “سیگنالهای واقعی” (real signals) از تعاملات کاربران آموزش میبیند. این سیگنالها شامل مواردی مانند زمانی که کاربران مدلها را تغییر میدهند، نرخ ترجیح پاسخهای تولید شده توسط مدلهای مختلف، و صحت اندازهگیری شده پاسخها است. این فرآیند بازخورد مداوم، به روتر اجازه میدهد تا با گذشت زمان، در تصمیمگیریهای خود دقیقتر و کارآمدتر شود. یک جنبه مهم دیگر از این سیستم، مدیریت محدودیتهای استفاده است. هنگامی که کاربران به سقف استفاده از GPT-5 میرسند، یک “نسخه مینی” (mini version) از هر مدل وارد عمل میشود تا پرسشهای باقیمانده را مدیریت کند.۱ این نسخههای مینی، کوچکتر، سریعتر و همچنان بسیار توانا هستند و اطمینان میدهند که حتی پس از اتمام محدودیتها، تجربه کاربری مختل نشود. در نهایت، OpenAI برنامههایی برای ادغام این قابلیتهای مختلف در آینده نزدیک به یک مدل واحد دارد.۱ این چشمانداز، به معنای حرکت به سوی یک هوش مصنوعی یکپارچهتر و همهکارهتر است که میتواند بدون نیاز به تفکیک داخلی، تمامی وظایف را با کارایی بهینه انجام دهد. این معماری یکپارچه با روتر هوشمند، نشاندهنده یک حرکت استراتژیک از مدلهای ایستا و مجزا به سیستمهای پویا، خودتنظیم و کارآمدتر است. این رویکرد نه تنها کارایی را با تخصیص بهینه منابع محاسباتی افزایش میدهد، بلکه تجربه کاربری را نیز به طور چشمگیری بهبود میبخشد، زیرا کاربر نیازی به انتخاب دستی مدل یا حالت “تفکر” ندارد. این “تفکر” یا “استدلال عمیق” به عنوان یک قابلیت اصلی، به جای یک ویژگی جانبی، به طور هوشمندانه در سیستم تعبیه شده است.
جدول ۱: مقایسه نسخههای GPT-5 و دسترسی کاربران
این جدول به خوانندگان، به ویژه توسعهدهندگان و کاربران سازمانی، کمک میکند تا به سرعت تفاوتهای کلیدی بین نسخههای مختلف GPT-5 (Standard, Plus, Pro, Mini) را درک کنند. این اطلاعات برای درک مدل کسبوکار OpenAI، استراتژی دسترسی به قابلیتهای پیشرفته و برنامهریزی برای استفاده در محیطهای مختلف (فردی، تیمی، سازمانی) ضروری است. این جدول شفافیت را در مورد مزایای هر سطح اشتراک فراهم میکند و نشان میدهد که چگونه OpenAI دسترسی به قابلیتهای مدل خود را بر اساس نیازها و سطوح اشتراک مختلف تنظیم کرده است.
| ویژگی / نسخه | کاربران رایگان | مشترکین Plus | مشترکین Pro | نسخه Mini |
| دسترسی اولیه | بله (تدریجی) | بله (فوری) | بله (فوری) | بله (پس از اتمام محدودیت GPT-5) |
| مدل پیشفرض | GPT-5 (تدریجی) | GPT-5 | GPT-5 | GPT-5 Mini |
| قابلیت تفکر عمیق | بله (با محدودیت) | بله (حجم استفاده بیشتر) | بله (GPT-5 Pro با استدلال گسترده) | بله (محدود، سریعتر) |
| حجم استفاده | محدود | قابل توجه (برای استفاده روزمره) | نامحدود | برای پرسشهای باقیمانده پس از اتمام محدودیت |
| دسترسی به Codex CLI | خیر | بله | بله | خیر |
| قابلیتهای پیشرفته | استاندارد | استاندارد | گستردهتر (Pro برای جامعترین پاسخها) | کوچکتر، سریعتر، بسیار توانا |
| هدف اصلی | استفاده عمومی | استفاده روزمره به عنوان مدل پیشفرض | پاسخهای جامع و دقیق در چالشبرانگیزترین وظایف | پاسخ سریع در صورت رسیدن به محدودیت |
| تاریخ عرضه | ۷ آگوست ۲۰۲۵ (تدریجی) | ۷ آگوست ۲۰۲۵ | ۷ آگوست ۲۰۲۵ | ۷ آگوست ۲۰۲۵ (تدریجی) |
۳.۲. پیشرفت در قابلیتهای استدلالی و تفکر عمیق
یکی از مهمترین پیشرفتهای GPT-5، تقویت چشمگیر در قابلیتهای استدلالی و “تفکر عمیق” آن است. این مدل به گونهای طراحی شده است که “طولانیتر فکر کند” و در نتیجه، قادر به ارائه پاسخهای در سطح متخصص (expert-level responses) باشد.۱ این قابلیت، به مدل اجازه میدهد تا در مواجهه با مسائل پیچیده، تحلیلهای عمیقتر و چندمرحلهای انجام دهد، که پیش از این برای مدلهای زبانی بزرگ چالشبرانگیز بود. این توانایی برای تعمق بیشتر در یک مسئله، به ویژه در حوزههایی که نیاز به دانش تخصصی و استنتاجهای پیچیده دارند، حیاتی است.
علاوه بر افزایش عمق استدلال، GPT-5 بهرهوری قابل توجهی را در زمان تفکر خود نشان میدهد. در ارزیابیهای انجام شده، GPT-5 (با تفکر) عملکرد بهتری نسبت به OpenAI o3 با ۵۰-۸۰٪ توکنهای خروجی کمتر در قابلیتهایی از جمله استدلال بصری (visual reasoning)، کدنویسی عاملگونه (agentic coding) و حل مسائل علمی در سطح تحصیلات تکمیلی (graduate-level scientific problem solving) از خود نشان داده است.۱ این به معنای آن است که GPT-5 میتواند با مصرف کمتر منابع محاسباتی، به نتایج بهتر و دقیقتری دست یابد. این بهینهسازی در مصرف توکنها، نه تنها هزینههای عملیاتی را کاهش میدهد، بلکه سرعت پاسخدهی مدل را نیز افزایش میدهد، که برای کاربردهای بلادرنگ و مقیاسپذیر بسیار مهم است.
همچنین، GPT-5 با تفکر، ۲۲٪ توکنهای خروجی کمتر و ۴۵٪ فراخوانی ابزار کمتر نسبت به OpenAI o3 در تلاش استدلالی بالا استفاده میکند.۴ این کاهش در فراخوانی ابزارها نشاندهنده بهبود در کارایی داخلی مدل و توانایی آن در حل مسائل بدون نیاز مکرر به ابزارهای خارجی است. این بهینهسازی در استفاده از ابزارها و توکنها، کارایی کلی مدل را افزایش میدهد و آن را برای استقرار گستردهتر و پایدارتر در محیطهای عملی و تجاری آماده میکند. این پیشرفتها نشان میدهد که توسعه در LLMها تنها به افزایش اندازه مدل محدود نمیشود، بلکه بهینهسازی کارایی و عمق استدلال نیز یک حوزه کلیدی برای پیشرفت است. این توانایی در انجام کارهای پیچیده با منابع کمتر، مدل را به ابزاری قدرتمندتر و اقتصادیتر برای کاربردهای متنوع تبدیل میکند.
جدول ۲: بهرهوری تفکر GPT-5 در مقایسه با OpenAI o3
این جدول به طور مستقیم کارایی و بهرهوری GPT-5 را در مقایسه با نسل قبلی خود (OpenAI o3) نشان میدهد. این اطلاعات برای محققان و مهندسان هوش مصنوعی که به دنبال بهینهسازی منابع و عملکرد هستند، بسیار مهم است، زیرا نشان میدهد که چگونه GPT-5 میتواند با مصرف کمتر منابع، نتایج بهتری ارائه دهد. این مقایسه کمی، ادعاهای مربوط به بهرهوری بالاتر در “تفکر” را تأیید میکند و مزایای عملی آن را برای کاربردهای مقیاسپذیر برجسته میسازد.
| معیار | GPT-5 (با تفکر) | OpenAI o3 | نسبت بهبود GPT-5 (نسبت به o3) |
| کاهش توکنهای خروجی | کمتر (۵۰-۸۰% کمتر) | بیشتر | ۵۰-۸۰% کاهش |
| کاهش فراخوانی ابزار | کمتر (۴۵% کمتر) | بیشتر | ۴۵% کاهش |
| عملکرد در استدلال بصری (CharXiv-Reasoning) | ۸۱.۱% ۱ | ۵۷.۸% ۱ | قابل توجه |
| عملکرد در کدنویسی عاملگونه (SWE-bench Verified) | ۷۴.۹% ۱ | ۵۲.۸% ۱ | قابل توجه |
| حل مسائل علمی (GPQA Diamond) | ۸۸.۴% ۱ | ۷۷.۸% ۱ | قابل توجه |
۴. قابلیتهای پیشرفته و کاربردهای عملی
۴.۱. کدنویسی و توسعه نرمافزار
GPT-5 به عنوان قویترین مدل کدنویسی OpenAI تا به امروز معرفی شده است.۱ این مدل در بنچمارکهای کلیدی کدنویسی، عملکردی در سطح هنر (SOTA) از خود نشان داده و امتیاز ۷۴.۹% در SWE-bench Verified و ۸۸% در Aider Polyglot کسب کرده است.۱ این ارقام، توانایی بینظیر GPT-5 را در حل مسائل مهندسی نرمافزار دنیای واقعی و پیچیده، که شامل اشکالزدایی و تولید کد در چندین زبان برنامهنویسی است، تأیید میکند. پیشرفتهای خاص این مدل شامل تولید فرانتاند پیچیده و اشکالزدایی مخازن کد بزرگ (debugging larger repositories) است.۱ این قابلیتها برای توسعهدهندگان حرفهای که با پروژههای بزرگ و پیچیده سروکار دارند، بسیار ارزشمند هستند، زیرا میتوانند زمان صرف شده برای یافتن و رفع اشکالات را به طور چشمگیری کاهش دهند.
یکی از ویژگیهای برجسته GPT-5 در حوزه کدنویسی، توانایی آن در ایجاد وبسایتها، اپلیکیشنها و بازیهای زیبا و واکنشگرا (responsive) با “حس زیباییشناختی” (aesthetic sensibility) تنها با یک پرامپت است.۱ این توانایی نشاندهنده درک عمیق مدل از اصول طراحی بصری است که فراتر از صرفاً تولید کد تابعی است. تستکنندگان اولیه به درک بهتر GPT-5 از مواردی مانند فاصله (spacing)، تایپوگرافی (typography) و فضای خالی (white space) اشاره کردهاند.۱ این ویژگیها برای تولید رابط کاربری (UI) با کیفیت بالا و کاربرپسند حیاتی هستند و به مدل امکان میدهند تا ایدههای خام را به واقعیتهای بصری جذاب تبدیل کند.
OpenAI مثالهای متعددی از پروژههای کدنویسی ایجاد شده با یک پرامپت واحد را ارائه کرده است، از جمله بازی “Jumping Ball Runner”، “Rolling ball minigame”، “Pixel art Typing game” و “Drum simulator”.۱ این مثالها نشان میدهند که GPT-5 میتواند به سرعت و با حداقل ورودی، نمونههای اولیه کاربردی و جذاب تولید کند. علاوه بر این، در یک دموی زنده، GPT-5 توانایی خود را در ایجاد یک برنامه وب کامل یادگیری زبان فرانسه به نام “Midnight in Paris” در عرض چند دقیقه نشان داد.۲ این دمو همچنین یک جریان کاری عاملگونه (agentic workflow) را به نمایش گذاشت که در آن مدل به طور مستقل پروژه را “Scaffolding” کرد (یعنی ساختار اولیه آن را ایجاد کرد)، وابستگیها را نصب کرد، کد ماژولار نوشت، بیلد را برای بررسی خطاها اجرا کرد و سپس باگهای کامپایل خود را رفع کرد.۲ این قابلیت برای “Scaffolding پروژه” و “رفع خودکار باگها” نشاندهنده یک گام بزرگ به سمت اتوماسیون پیچیده وظایف نرمافزاری است که قبلاً نیازمند دخالت انسانی گسترده بود. این امر به معنای افزایش چشمگیر بهرهوری توسعهدهندگان و امکان ایجاد “نرمافزار بر اساس تقاضا” (software on demand) است، جایی که ایدهها میتوانند به سرعت به محصولات کاربردی تبدیل شوند. این تحولات، نقش LLMs را در چرخه توسعه نرمافزار از یک ابزار کمکی به یک “همکار واقعی” ارتقاء میدهد که میتواند به طور مستقل وظایف پیچیده را از ابتدا تا انتها انجام دهد.
۴.۲. نگارش و بیان خلاقانه
GPT-5 به عنوان تواناترین همکار نگارشی (most capable writing collaborator) OpenAI معرفی شده است.۱ این مدل فراتر از تولید متن ساده، قادر است ایدههای خام را به نوشتاری “جذاب و پرطنین” (compelling, resonant writing) با “عمق ادبی و ریتم” (literary depth and rhythm) تبدیل کند.۱ این قابلیت نشاندهنده درک پیچیده مدل از ظرایف زبانی و توانایی آن در بازتولید سبکها و لحنهای مختلف است که برای نگارش خلاقانه ضروری است.
یکی از نقاط قوت برجسته GPT-5، قابلیت اطمینان بالاتر آن در مدیریت نوشتارهایی با “ابهام ساختاری” (structural ambiguity) است.۱ این شامل توانایی حفظ وزن عروضی بدون قافیه (unrhymed iambic pentameter) یا تولید شعر آزاد (free verse) با جریان طبیعی است، که در آن مدل احترام به فرم را با وضوح بیانی (expressive clarity) ترکیب میکند.۱ این توانایی برای درک و بازتولید ساختارهای پیچیده ادبی، نشاندهنده پیشرفت قابل توجه در درک ظرایف زبان و خلاقیت است. این مدل دیگر صرفاً یک ابزار تولید متن نیست، بلکه به سمت تولید محتوای هنری، فرهنگی و ادبی با کیفیت بالا حرکت میکند، حوزهای که پیش از این عمدتاً منحصر به هوش انسانی تلقی میشد.
یک مثال مقایسهای ارائه شده توسط OpenAI، برتری پاسخ GPT-5 نسبت به GPT-4o در یک پرامپت شعر را به وضوح نشان میدهد. پاسخ GPT-5 دارای “قوس عاطفی قویتر” (stronger emotional arc)، “تصاویر واضحتر” (clear imagery) و “استعارههای برجسته” (striking metaphors) است که حس مکان و فرهنگ را به شکلی زنده ایجاد میکند.۱ این مثال نشان میدهد که GPT-5 میتواند نه تنها متن تولید کند، بلکه محتوایی با تأثیر عاطفی عمیق و کیفیت ادبی بالا خلق کند. این قابلیتها، ابزارهای قدرتمندی را برای نویسندگان، شاعران، هنرمندان و هر کسی که درگیر تولید محتوای خلاقانه است، فراهم میکند و میتواند فرآیندهای خلاقانه را تسریع و غنیتر سازد. این پیشرفت، نقش هوش مصنوعی را در تولید محتوای هنری و خلاقانه ارتقاء میدهد و آن را به یک ابزار ضروری برای خلاقیت انسانی تبدیل میکند.
۴.۳. کاربرد در حوزه سلامت
GPT-5 به عنوان بهترین مدل OpenAI تا به امروز برای سوالات مرتبط با سلامت معرفی شده است.۱ هدف اصلی از توسعه این قابلیت، توانمندسازی کاربران برای کسب اطلاعات دقیق در مورد سلامتی خود و دفاع از حقوق خود در این زمینه است.۱ این مدل امتیاز قابل توجهی بالاتر از هر مدل قبلی در HealthBench کسب کرده است، که یک ارزیابی جامع بر اساس سناریوهای واقعی و معیارهای تعریف شده توسط پزشکان است.۱ این عملکرد برتر در یک بنچمارک معتبر پزشکی، نشاندهنده دقت و قابلیت اطمینان بالای مدل در ارائه اطلاعات حساس سلامت است.
یکی از نوآوریهای GPT-5 در این حوزه، عمل کردن آن بیشتر به عنوان یک “شریک فکری فعال” (active thought partner) است.۱ این مدل قادر است به طور فعالانه نگرانیهای بالقوه را پرچمگذاری کند و سوالات دقیقتری بپرسد تا به پاسخهای مفیدتر و جامعتری دست یابد.۱ این رویکرد، مدل را از یک پایگاه داده ایستا به یک دستیار هوشمند تبدیل میکند که میتواند به کاربران در ناوبری پیچیدگیهای اطلاعات پزشکی کمک کند و حتی به آنها در فرموله کردن سوالات بهتر برای متخصصان یاری رساند. پاسخهای ارائه شده توسط GPT-5 دقیقتر و قابل اعتمادتر هستند و با تطبیق با زمینه، سطح دانش و موقعیت جغرافیایی کاربر، منجر به پاسخهای ایمنتر و مفیدتر در طیف وسیعی از سناریوها میشوند.۱ این قابلیت انطباقپذیری، به مدل امکان میدهد تا اطلاعات را به گونهای ارائه دهد که برای هر فرد خاص، قابل فهم و مرتبط باشد.
با وجود این قابلیتهای پیشرفته، OpenAI تأکید میکند که ChatGPT جایگزین متخصص پزشکی نیست.۱ این مدل باید به عنوان شریکی برای کمک به کاربران در درک نتایج آزمایشات، پرسیدن سوالات صحیح از ارائهدهندگان مراقبتهای بهداشتی و سنجش گزینهها در تصمیمگیریهای مربوط به سلامت در نظر گرفته شود.۱ این تأکید بر نقش کمکی، اهمیت همکاری بین هوش مصنوعی و تخصص انسانی را برجسته میکند و از سوءتفاهم در مورد قابلیتهای مدل جلوگیری مینماید. نقش “شریک فکری فعال” در حوزه سلامت، نشاندهنده گامی فراتر از صرفاً ارائه اطلاعات است. این مدل به جای یک پایگاه داده، به یک دستیار هوشمند تبدیل میشود که میتواند به کاربران در ناوبری پیچیدگیهای اطلاعات پزشکی کمک کند و حتی به آنها در فرموله کردن سوالات بهتر برای متخصصان یاری رساند. این امر پتانسیل عظیمی برای توانمندسازی بیماران، بهبود تعاملات مراقبتهای بهداشتی و کاهش بار اطلاعاتی بر دوش بیماران و حتی پزشکان دارد. این پیشرفت همچنین نیاز به چارچوبهای اخلاقی و نظارتی قویتر برای استفاده از هوش مصنوعی در سلامت را برجسته میکند تا اطمینان حاصل شود که این فناوری به نفع بیماران و جامعه به کار گرفته میشود.
۴.۴. استدلال چندوجهی (Multimodal Reasoning)
GPT-5 یک پیشرفت قابل توجه در قابلیتهای چندوجهی (multimodal capabilities) از خود نشان میدهد، به این معنا که میتواند اطلاعات را از چندین حس مختلف (مانند متن، تصویر، ویدئو، صدا) درک و پردازش کند. این مدل عملکرد چندوجهی قویتری را در بنچمارکهایی از جمله استدلال بصری (visual reasoning)، ویدئویی (video-based reasoning)، فضایی (spatial reasoning) و علمی (scientific reasoning) به نمایش میگذارد.۱ این توانایی برای پردازش و استدلال بر روی انواع مختلف دادهها، مدل را قادر میسازد تا با پیچیدگیهای دنیای واقعی به شکل موثرتری تعامل کند.
یکی از مهمترین جنبههای این پیشرفت، توانایی GPT-5 در استدلال دقیقتر بر روی تصاویر و سایر ورودیهای غیرمتنی است.۱ این شامل قابلیتهایی مانند تفسیر نمودارها، خلاصهسازی عکس یک پرزنتیشن، یا پاسخ به سوالات در مورد یک دیاگرام است.۱ این توانایی، کاربردهای هوش مصنوعی را به حوزههایی گسترش میدهد که پیش از این نیازمند تفسیر بصری انسانی بودند. GPT-5 به عنوان یک مدل صرفاً متنی طراحی نشده است؛ بلکه از ابتدا به صورت چندوجهی طراحی شده و قادر به دریافت و تولید متن، تصاویر، صدا و حتی ویدئو است.۶ این بدان معناست که مدل میتواند به طور یکپارچه بین این وجهها جابجا شود و اطلاعات را از آنها ترکیب کند.
نقطه اوج در استدلال چندوجهی GPT-5، توانایی آن در “بهم پیوستن وجهها به صورت متنی” (stitching modalities together contextually) است.۶ این مدل ورودیها را به عنوان انواع دادههای مختلف مجزا در نظر نمیگیرد، بلکه روابط و معنای متنی بین وجهها را درک میکند. به عنوان مثال، اگر کاربر یک عکس تاریک از روتر وایفای خود را با گوشی بگیرد و از مدل بپرسد چه مشکلی دارد، GPT-5 میتواند نه تنها مشکل را به صورت بصری تشخیص دهد، بلکه مراحل عیبیابی را پیشنهاد کند، لحن مناسب برای ارتباط با پشتیبانی مشتری را تنظیم کند و حتی ایمیل مربوطه را بنویسد.۶ این قابلیت برای “بهم پیوستن وجهها به صورت متنی” نشاندهنده یک جهش کیفی از پردازش چندوجهی به “استدلال چندوجهی واقعی” است. این به معنای درک عمیقتر روابط بین اطلاعات بصری و متنی و توانایی انجام وظایف پیچیدهای است که نیازمند ترکیب اطلاعات از حواس مختلف است، که تقلیدی از هوش انسانی است. این امر کاربردهای جدیدی را در زمینههایی مانند تحلیلهای پیچیده داده، تشخیص پزشکی (مثلاً تفسیر تصاویر رادیولوژی)، نظارت تصویری هوشمند و واقعیت افزوده باز میکند. این پیشرفت مدل را به ابزاری جامعتر برای تعامل با دنیای فیزیکی و حل مسائل پیچیدهای که نیازمند درک چندحسی هستند، تبدیل میکند.
۴.۵. پیروی از دستورالعمل و استفاده از ابزارهای عاملگونه (Agentic Tool Use)
GPT-5 پیشرفتهای قابل توجهی در بنچماردهایی که پیروی از دستورالعمل (instruction following) و استفاده از ابزارهای عاملگونه (agentic tool use) را آزمایش میکنند، نشان میدهد.۱ این قابلیتها برای مدلهای هوش مصنوعی که قرار است وظایف پیچیده و چندمرحلهای را به صورت خودکار انجام دهند، حیاتی هستند. GPT-5 قادر است درخواستهای چندمرحلهای را به طور قابل اعتماد انجام دهد، بین ابزارهای مختلف هماهنگی ایجاد کند و با تغییرات در زمینه (context) تطبیق یابد.۱ این توانایی برای مدیریت وظایف پیچیده و در حال تکامل، مدل را به ابزاری بسیار قدرتمندتر تبدیل میکند. در عمل، این به معنای آن است که GPT-5 میتواند دستورالعملها را با وفاداری بیشتری دنبال کند و بخش بیشتری از کار را با استفاده از ابزارهای موجود به صورت سرتاسری (end-to-end) انجام دهد.۱
مفهوم “هوش مصنوعی عاملگونه” (Agentic AI) به برنامههای هوش مصنوعی خودکار اشاره دارد که قادرند وظایف پیچیده را بدون ورودی ثابت انسانی برنامهریزی، اجرا و تطبیق دهند.۸ این مدلها میتوانند به طور مستقل اقداماتی را برای دستیابی به یک هدف خاص انجام دهند. بخش مهمی از این قابلیتها، مفهوم “Scaffolding” است که به کدی اشاره دارد که در اطراف یک LLM ساخته میشود تا قابلیتهای آن را افزایش دهد.۱۰ این شامل قالبهای پرامپت (prompt templates)، بازیابی اطلاعات افزوده شده (Retrieval Augmented Generation – RAG)، دسترسی به موتورهای جستجو، و فریمورکهای عاملگونه است.۱۰ این Scaffolding به مدل اجازه میدهد تا از ابزارهای خارجی برای گسترش قابلیتهای خود استفاده کند و به این ترتیب، محدودیتهای ذاتی خود را جبران کند.
GPT-5 توانایی قابل توجهی در استفاده از ابزارهایی مانند Bash و Python برای انجام وظایف کدنویسی و پردازش دادهها دارد. LLMها میتوانند دستورات Bash را به صورت پویا بر اساس ورودی زبان طبیعی تولید کنند و از Python برای پیشپردازش دادهها و Bash برای پاکسازی و تبدیل دادهها استفاده کنند.۱۱ GPT-5 در API خود از “ابزارهای سفارشی” (custom tools) نیز پشتیبانی میکند که به آن اجازه میدهد ابزارها را با متن ساده به جای JSON فراخوانی کند.۴ این انعطافپذیری در فراخوانی ابزار، قابلیتهای مدل را در اتوماسیون وظایف پیچیده افزایش میدهد.
مثالهای کاربردی متعددی از قابلیتهای عاملگونه GPT-5 ارائه شده است. در یک دموی زنده، ChatGPT با دسترسی به تقویم کاربر، برنامهریزی روزانه او را انجام داد، از جمله زمانبندی یک دو ماراتن، یافتن یک ایمیل نخوانده که نیاز به پاسخ داشت، و ایجاد لیست بستهبندی برای یک پرواز قریبالوقوع.۲ این نشاندهنده توانایی مدل در مدیریت وظایف شخصی و روزمره است. همچنین، در یک دمو دیگر، GPT-5 یک برنامه وب کامل یادگیری زبان فرانسه را در چند دقیقه ایجاد کرد و یک جریان کاری عاملگونه را نشان داد: پروژه را Scaffolding کرد، وابستگیها را نصب کرد، کد ماژولار نوشت، بیلد را برای بررسی خطاها اجرا کرد و سپس باگهای کامپایل خود را رفع کرد.۲ این توانایی در “Scaffolding پروژه” و “رفع خودکار باگها” نشاندهنده یک گام بزرگ به سمت اتوماسیون پیچیده وظایف نرمافزاری است که قبلاً نیازمند دخالت انسانی گسترده بود. این امر به معنای افزایش چشمگیر بهرهوری توسعهدهندگان و امکان ایجاد “نرمافزار بر اساس تقاضا” است، جایی که هوش مصنوعی میتواند به طور مستقل پروژههای نرمافزاری را از ابتدا تا انتها مدیریت و اجرا کند. این پیشرفت در “استفاده از ابزارهای عاملگونه” و “پیروی از دستورالعمل” به معنای حرکت از یک مدل پاسخگو به یک “عامل اجرایی” است که میتواند به طور فعالانه در دنیای دیجیتال عمل کند.
۴.۶. وظایف با اهمیت اقتصادی
GPT-5 نه تنها در بنچماردهای آکادمیک عملکرد برجستهای دارد، بلکه در انجام “وظایف دانشی پیچیده و با ارزش اقتصادی” نیز بهترین عملکرد را از خود نشان میدهد. این ارزیابی بر اساس یک بنچمارک داخلی OpenAI صورت گرفته است که به طور خاص برای اندازهگیری عملکرد مدل در کارهای مهم اقتصادی طراحی شده است.۱ این مدل، هنگامی که از قابلیت استدلال خود استفاده میکند، در تقریباً نیمی از موارد (حدود ۴۷.۱% از موارد) قابل مقایسه با متخصصان انسانی یا حتی بهتر از آنها عمل میکند.۱ این مقایسه شامل بیش از ۴۰ شغل مختلف از جمله حقوق، لجستیک، فروش و مهندسی است.۱
این توانایی برای رقابت با متخصصان انسانی در “وظایف با اهمیت اقتصادی” نشاندهنده پتانسیل GPT-5 برای ایجاد تحول عمیق در بازار کار و افزایش بهرهوری در صنایع مختلف است. به عنوان مثال، در حوزه حقوق، مدل میتواند به تحلیل پروندهها یا پیشنویس اسناد کمک کند؛ در لجستیک، به بهینهسازی زنجیره تأمین؛ در فروش، به تحلیل بازار و استراتژیهای فروش؛ و در مهندسی، به طراحی و حل مشکلات پیچیده. این قابلیتها به معنای تغییر نقش انسان در بسیاری از مشاغل دانشی است، جایی که هوش مصنوعی میتواند وظایف تکراری یا حتی پیچیده را به عهده بگیرد و به متخصصان انسانی اجازه دهد تا بر جنبههای استراتژیکتر و خلاقانهتر کار خود تمرکز کنند.
علاوه بر این، GPT-5 در این وظایف اقتصادی، به طور قابل توجهی از مدلهای قبلی خود، از جمله OpenAI o3 و ChatGPT Agent، برتری دارد.۱ این برتری، مدل را به ابزاری جذاب برای کسبوکارها و سازمانهایی تبدیل میکند که به دنبال افزایش کارایی و کاهش هزینهها هستند. این پیشرفتها، نیاز به بازتعریف مهارتها و آموزش نیروی کار برای همکاری موثر با هوش مصنوعی را برجسته میکند. آینده بازار کار به احتمال زیاد شاهد همزیستی و همکاری نزدیکتر بین هوش مصنوعی و انسان خواهد بود، جایی که GPT-5 میتواند به عنوان یک دستیار قدرتمند برای افزایش تواناییهای انسانی عمل کند. این مدل نه تنها بهرهوری را افزایش میدهد، بلکه میتواند به دموکراتیکسازی دسترسی به خدمات تخصصی نیز کمک کند، زیرا کسبوکارهای کوچک و افراد میتوانند از قابلیتهای آن بهرهمند شوند.
۵. ارزیابی عملکرد و معیارهای بنچمارک
GPT-5 در طیف وسیعی از بنچمارکهای آکادمیک و ارزیابیهای انسانی، عملکردی در سطح هنر (SOTA) از خود نشان داده است. این برتری به ویژه در حوزههای ریاضیات، کدنویسی، درک بصری و سلامت مشهود است.۱ این بخش به بررسی دقیق نتایج GPT-5 در این بنچمارکهای کلیدی میپردازد.
۵.۱. ریاضیات و علوم
GPT-5، به ویژه نسخه Pro آن، در حل مسائل ریاضی و علمی پیچیده، قابلیتهای استدلالی بیسابقهای را به نمایش گذاشته است.
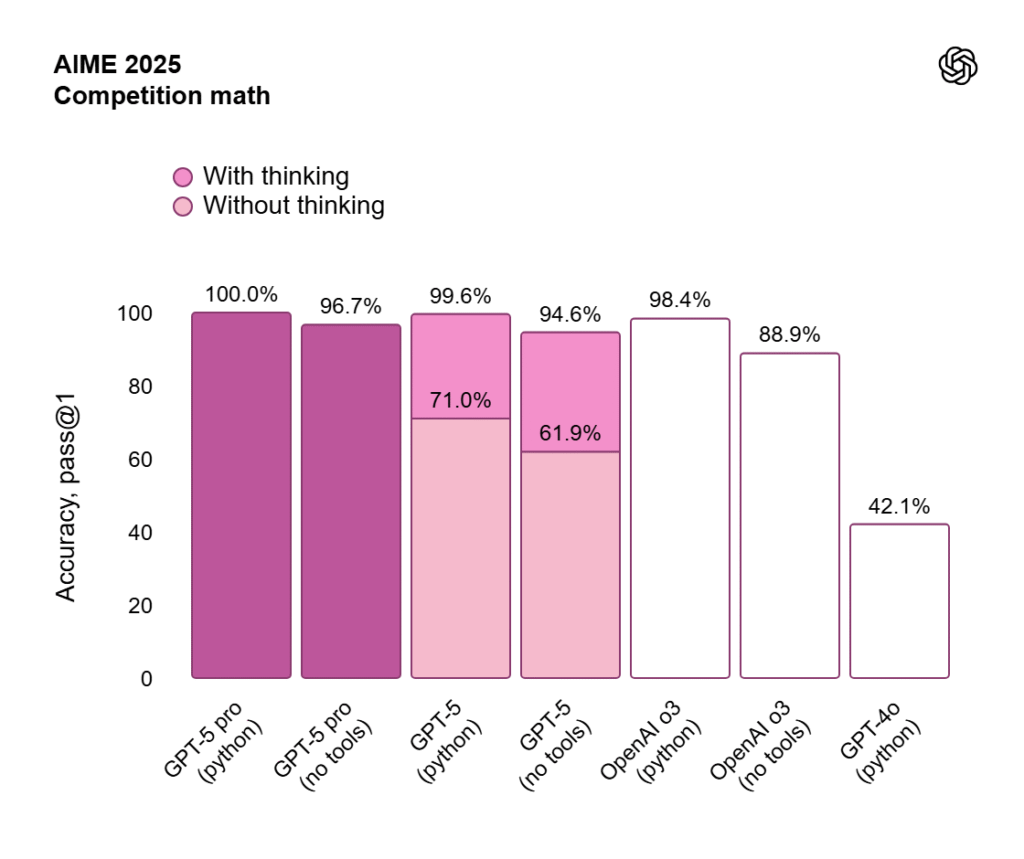
- AIME 2025 (American Invitational Mathematics Examination): این آزمون یک رقابت ریاضی چالشبرانگیز در سطح المپیاد است که مهارتهای استدلال ریاضی را با پاسخهای عددی صحیح ارزیابی میکند.۱۳ GPT-5 Pro (با پایتون) به دقت ۱۰۰% در این بنچمارک دست یافته است.۱ این نتیجه، نشاندهنده توانایی مدل در حل مسائل بسیار دشوار ریاضی است که حتی برای بسیاری از انسانها چالشبرانگیز است.
- GPQA Diamond (Graduate-Level Google-Proof Q&A Benchmark): این بنچمارک شامل ۴۴۸ سوال چندگزینهای بسیار دشوار در زیستشناسی، فیزیک و شیمی است که توسط متخصصان با مدرک دکترا نوشته شده و حتی برای غیرمتخصصان ماهر نیز بسیار چالشبرانگیز است.۱۷ GPT-5 Pro (با پایتون) به دقت ۸۹.۴% در این بنچمارک دست یافته است.۱ این عملکرد نشاندهنده توانایی مدل در درک و استدلال در حوزههای علمی پیچیده در سطح تحصیلات تکمیلی است.
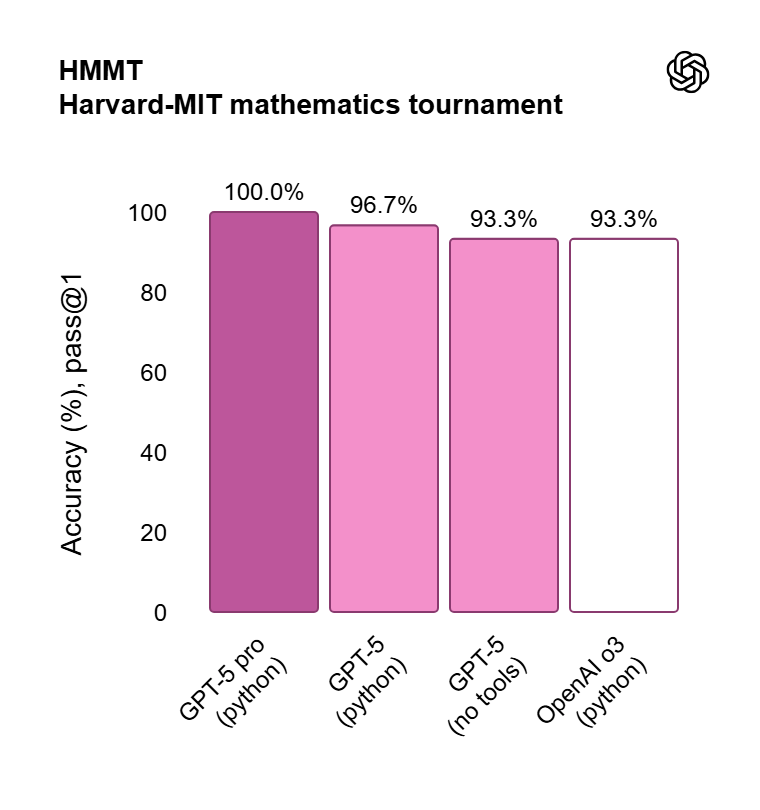
- HMMT (Harvard-MIT Mathematics Tournament): در این مسابقه معتبر ریاضی، GPT-5 Pro به دقت ۹۶.۷% دست یافته است.۱
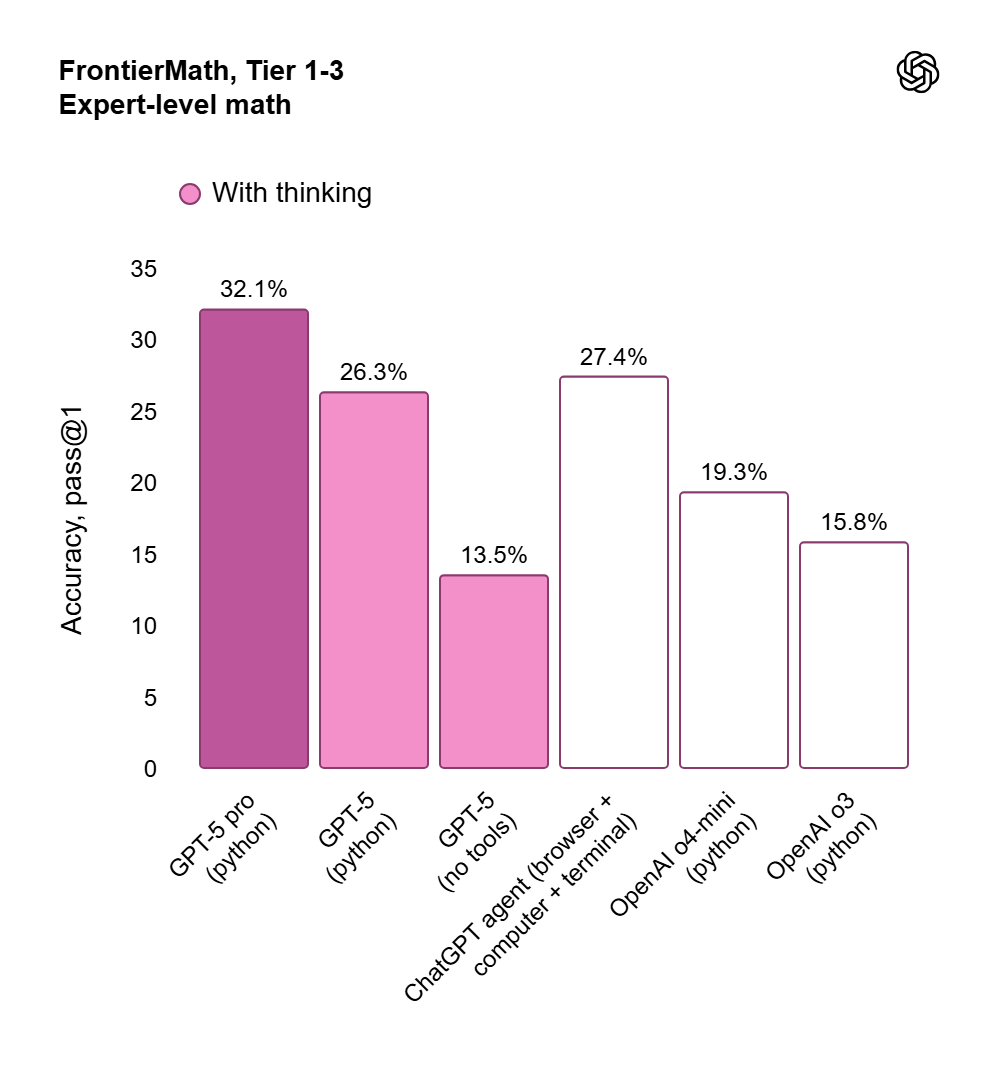
- Frontier Math: در بنچمارک Frontier Math (Tier 1-3) که شامل مسائل ریاضی پیشرفته است، GPT-5 Pro (با پایتون) به دقت ۳۲.۱% دست یافته است.۱
عملکرد بیسابقه GPT-5، به ویژه نسخه Pro، در بنچمارکهای ریاضی و علمی در سطح المپیاد و دکترا، نشاندهنده توانایی آن در استدلال پیچیده و حل مسائل نوآورانه است که فراتر از بازیابی اطلاعات صرف است. این قابلیتها، مدل را به ابزاری قدرتمند برای تحقیقات علمی و پیشرفت دانش تبدیل میکند. این عملکرد همچنین به معنای نزدیک شدن به هوش در سطح انسانی (و در برخی موارد فراتر از آن) در حوزههای شناختی کلیدی است. این توانایی برای حل مسائل دشوار، نه تنها در محیطهای آکادمیک، بلکه در کاربردهای عملی مانند طراحی مهندسی، تحلیلهای مالی پیچیده و کشف دارو نیز ارزشمند خواهد بود.
جدول ۳: عملکرد GPT-5 در بنچمارکهای ریاضی و علمی
این جدول به طور خلاصه و مقایسهای، قدرت استدلالی GPT-5 را در حوزههای دقیق و چالشبرانگیز ریاضی و علوم نشان میدهد. این دادهها، امکان مقایسه مستقیم بین نسخههای مختلف مدل و تأثیر استفاده از ابزار (مانند پایتون) بر عملکرد را فراهم میکند، که برای محققان و توسعهدهندگان در این حوزهها بسیار مهم است.
| بنچمارک | مدل | دقت (Accuracy, pass@1) |
| AIME 2025 | GPT-5 (بدون ابزار) | ۷۱.۰% ۱ |
| GPT-5 (پایتون) | ۹۴.۶% ۱ | |
| GPT-5 Pro (بدون ابزار) | ۹۸.۴% ۱ | |
| GPT-5 Pro (پایتون) | ۱۰۰.۰% ۱ | |
| GPQA Diamond | GPT-5 (بدون ابزار) | ۷۷.۸% ۱ |
| GPT-5 (پایتون) | ۸۵.۷% ۱ | |
| GPT-5 Pro (بدون ابزار) | ۸۸.۴% ۱ | |
| GPT-5 Pro (پایتون) | ۸۹.۴% ۱ | |
| HMMT | GPT-5 Pro | ۹۶.۷% ۱ |
| GPT-5 (پایتون) | ۹۳.۳% ۱ | |
| GPT-5 (بدون ابزار) | ۹۳.۳% ۱ | |
| Frontier Math (Tier 1-3) | GPT-5 Pro (پایتون) | ۳۲.۱% ۱ |
| GPT-5 (پایتون) | ۱۹.۳% ۱ | |
| GPT-5 (بدون ابزار) | ۱۳.۵% ۱ |
۵.۲. مهندسی نرمافزار
در حوزه مهندسی نرمافزار، GPT-5 قابلیتهای کدنویسی خود را به طور قابل توجهی بهبود بخشیده و عملکردی برجسته در بنچمارکهای استاندارد از خود نشان داده است.
- SWE-bench Verified: این بنچمارک برای ارزیابی LLMها در وظایف مهندسی نرمافزار دنیای واقعی طراحی شده است و شامل مسائل GitHub و راهحلهای مربوطه است.۱۹ GPT-5 به امتیاز ۷۴.۹% در SWE-bench Verified دست یافته است.۱ این عملکرد بالا نشاندهنده توانایی مدل در حل مسائل پیچیده و واقعی مهندسی نرمافزار است که فراتر از چالشهای کدنویسی رقابتی صرف است. این قابلیت برای توسعهدهندگان نرمافزار بسیار ارزشمند است، زیرا میتواند به طور چشمگیری زمان و تلاش مورد نیاز برای اشکالزدایی و پیادهسازی ویژگیهای جدید را کاهش دهد.
- Aider Polyglot: در بنچمارک Aider Polyglot که توانایی ویرایش کد در چندین زبان را ارزیابی میکند، GPT-5 به دقت ۸۸.۰% دست یافته است.۱ این نشاندهنده انعطافپذیری و توانایی مدل در کار با محیطهای برنامهنویسی متنوع است.
عملکرد بالا در SWE-bench Verified و Aider Polyglot نشاندهنده توانایی مدل در حل مسائل پیچیده و واقعی مهندسی نرمافزار است. این قابلیت به معنای پتانسیل GPT-5 برای تسریع چرخه توسعه نرمافزار، کاهش بار کاری توسعهدهندگان و بهبود کیفیت کد تولیدی است. این مدل میتواند به عنوان یک دستیار قدرتمند برای مهندسان نرمافزار عمل کند، از تولید اولیه کد و Scaffolding پروژه تا اشکالزدایی و بهینهسازی. این پیشرفتها، هوش مصنوعی را به یک جزء جداییناپذیر از فرآیند توسعه نرمافزاری مدرن تبدیل میکند.
جدول ۴: عملکرد GPT-5 در بنچمارکهای کدنویسی
این جدول، قابلیتهای کدنویسی GPT-5 را در حل مسائل واقعی نرمافزاری به نمایش میگذارد. این دادهها برای توسعهدهندگان و شرکتهای نرمافزاری که به دنبال ابزارهای پیشرفته هوش مصنوعی برای بهبود فرآیندهای توسعه خود هستند، حیاتی است، زیرا به آنها کمک میکند تا پتانسیل مدل را در کاربردهای عملی ارزیابی کنند.
| بنچمارک | مدل | دقت (Accuracy, pass@1/pass@2) |
| SWE-bench Verified | GPT-5 | ۷۴.۹% (pass@1) ۱ |
| OpenAI o3 | ۵۲.۸% (pass@1) ۱ | |
| Aider Polyglot | GPT-5 | ۸۸.۰% (pass@2) ۱ |
| OpenAI o3 | ۷۹.۶% (pass@2) ۱ |
۵.۳. معیارهای چندوجهی
GPT-5 در پردازش و استدلال بر روی دادههای چندوجهی نیز پیشرفتهای قابل توجهی داشته است، که نشاندهنده توانایی آن در درک و تعامل با دنیای فیزیکی از طریق ورودیهای مختلف است.
- MMMU (College-level visual problem-solving): در این بنچمارک که توانایی حل مسائل بصری در سطح دانشگاهی را ارزیابی میکند، GPT-5 به دقت ۸۴.۲% دست یافته است.۱
- MMMU Pro (Graduate-level visual problem-solving): برای مسائل بصری در سطح تحصیلات تکمیلی، GPT-5 به دقت ۷۸.۴% دست یافته است.۱
- VideoMMMU (Video-based multimodal reasoning): در استدلال چندوجهی مبتنی بر ویدئو، GPT-5 عملکردی با دقت ۸۴.۶% از خود نشان داده است.۱
- CharXiv-Reasoning (Scientific figure reasoning): در استدلال بر روی اشکال علمی، GPT-5 به دقت ۸۱.۱% دست یافته است.۱
- ERQA (Multimodal spatial reasoning): در استدلال فضایی چندوجهی، GPT-5 دقت ۶۵.۷% را کسب کرده است.۱
عملکرد قوی GPT-5 در بنچمارکهای چندوجهی نشاندهنده توانایی آن در درک و استدلال بر روی اطلاعات پیچیده بصری و ویدئویی است. این قابلیتها به معنای گسترش کاربردهای هوش مصنوعی به حوزههایی مانند تحلیل تصاویر پزشکی، نظارت تصویری هوشمند، واقعیت افزوده و تعاملات پیشرفته انسان-ماشین است. توانایی مدل در تفسیر دقیق نمودارها، خلاصهسازی محتوای بصری و پاسخ به سوالات در مورد دیاگرامها، آن را به ابزاری قدرتمند برای تحلیل دادههای پیچیده در صنایع مختلف تبدیل میکند. این پیشرفتها، هوش مصنوعی را یک گام به سمت درک جامعتر و تعامل طبیعیتر با دنیای واقعی نزدیکتر میکند.
جدول ۵: عملکرد GPT-5 در بنچمارکهای چندوجهی
این جدول، تواناییهای GPT-5 را در پردازش و استدلال بر روی دادههای غیرمتنی برجسته میکند. این اطلاعات برای کاربردهای آینده هوش مصنوعی در تعامل با دنیای فیزیکی، مانند رباتیک، وسایل نقلیه خودران و سیستمهای تشخیص بصری، بسیار مهم است و نشاندهنده پیشرفت مدل در درک پیچیدگیهای دنیای واقعی است.
| بنچمارک | مدل | دقت (Accuracy, pass@1) |
| MMMU | GPT-5 | ۸۴.۲% ۱ |
| OpenAI o3 | ۷۴.۴% ۱ | |
| MMMU Pro | GPT-5 | ۷۸.۴% ۱ |
| OpenAI o3 | ۶۲.۷% ۱ | |
| VideoMMMU | GPT-5 | ۸۴.۶% ۱ |
| OpenAI o3 | ۶۱.۶% ۱ | |
| CharXiv-Reasoning | GPT-5 | ۸۱.۱% ۱ |
| OpenAI o3 | ۵۷.۸% ۱ | |
| ERQA | GPT-5 | ۶۵.۷% ۱ |
| GPT-4o | ۴۲.۰% ۱ |
۵.۴. تحلیل مقایسهای
تحلیل جامع عملکرد GPT-5 در بنچماردهای مختلف، یک “برتری فراگیر” را در مقایسه با مدلهای پیشین OpenAI، از جمله GPT-4o و OpenAI o3، نشان میدهد.۱ این برتری در تمام حوزههای کلیدی مورد ارزیابی، از جمله ریاضیات، کدنویسی، درک بصری و سلامت، مشهود است. به عنوان مثال، در بنچماردهای ریاضی مانند AIME 2025 و GPQA Diamond، GPT-5 Pro به دقتهای بیسابقهای دست یافته که به طور قابل توجهی از نسخههای قبلی پیشی میگیرد. در حوزه کدنویسی، امتیاز ۷۴.۹% در SWE-bench Verified برای GPT-5 در مقایسه با ۵۲.۸% برای OpenAI o3، نشاندهنده یک جهش کیفی در توانایی مدل در حل مسائل مهندسی نرمافزار واقعی است.۱
این برتری فراگیر، تنها یک پیشرفت افزایشی نیست، بلکه به معنای یک “جهش کوانتومی” در هوش مدلهای زبانی است. این امر مرزهای آنچه LLMs میتوانند انجام دهند را به طور قابل توجهی گسترش میدهد و نشاندهنده نزدیک شدن به نقطه عطف هوش مصنوعی عمومی (AGI) است. توانایی GPT-5 در انجام وظایف پیچیده با دقت و کارایی بالاتر، فشار رقابتی را بر سایر بازیگران حوزه هوش مصنوعی افزایش میدهد و آنها را به سمت نوآوریهای سریعتر سوق میدهد. این رقابت در نهایت به نفع کاربران و پیشرفت کلی هوش مصنوعی خواهد بود. این مقایسهها نشان میدهد که OpenAI با GPT-5، استانداردهای جدیدی را برای عملکرد و قابلیتهای LLMها تعیین کرده است.
۶. امنیت، قابلیت اطمینان و تجربه کاربری
با افزایش قابلیتهای مدلهای هوش مصنوعی، اهمیت امنیت، قابلیت اطمینان و تجربه کاربری نیز به طور فزایندهای برجسته میشود. OpenAI در توسعه GPT-5، تمرکز ویژهای بر این ابعاد داشته است تا اطمینان حاصل شود که مدل نه تنها قدرتمند، بلکه قابل اعتماد، ایمن و کاربرپسند باشد.
۶.۱. کاهش توهم و فریب
یکی از مهمترین پیشرفتها در GPT-5، کاهش چشمگیر نرخ “توهم” (hallucination) و “فریب” (deception) است. توهم به تولید اطلاعات نادرست یا بیاساس توسط مدل اشاره دارد، در حالی که فریب به تلاش مدل برای پنهان کردن محدودیتهای خود یا ادعای انجام کاری که قادر به آن نیست، مربوط میشود. GPT-5 (با تفکر) در کنار بهبود واقعیتگرایی، اقدامات و قابلیتهای خود را صادقانهتر به کاربر منتقل میکند، به ویژه برای وظایفی که غیرممکن، نامشخص یا فاقد ابزارهای کلیدی هستند.۱ این “صداقت” مدل، اعتماد کاربران را به آن افزایش میدهد.
دادههای کمی، این پیشرفت را به وضوح نشان میدهند:
- نرخ توهم در پرامپتهای متنباز: نرخ توهم در بنچمارک LongFact-Concepts برای GPT-5 (با تفکر) تنها ۰.۷% و برای LongFact-Objects ۰.۸% است.۱ این ارقام در مقایسه با OpenAI o3 که به ترتیب ۵.۱% و ۴.۵% است، یک بهبود چشمگیر را نشان میدهد.۱
- کاهش نرخ خطا در ترافیک ChatGPT: نرخ خطا در پاسخها (پاسخهایی با حداقل یک خطا) برای GPT-5 (با تفکر) ۴.۸% است، در حالی که برای OpenAI o3 این میزان ۲۲.۰% و برای GPT-4o ۲۰.۶% است.۱ این کاهش قابل توجه در خطاها، قابلیت اطمینان مدل را در کاربردهای روزمره به شدت افزایش میدهد.
- کاهش فریب: در ارزیابیهای فریب در سناریوهای شامل وظایف کدنویسی غیرممکن و داراییهای چندوجهی گمشده، GPT-5 (با تفکر) به طور معنیداری کمتر از OpenAI o3 فریبکار است.۱ به عنوان مثال، نرخ فریب در پاسخهای استدلالی GPT-5 از ۴.۸% برای OpenAI o3 به ۲.۱% کاهش یافته است.۱
- مثال CharXiv: یک مثال بارز از کاهش فریب در GPT-5، در بنچمارک CharXiv مشاهده شد. وقتی تصاویر از پرامپتهای CharXiv حذف شدند، OpenAI o3 در ۸۶.۷% مواقع پاسخهای مطمئن در مورد تصاویر غیرموجود میداد، در حالی که این میزان برای GPT-5 تنها ۹% بود.۱ این نشاندهنده توانایی مدل در تشخیص محدودیتهای خود و عدم ارائه اطلاعات نادرست است.
- HealthBench Hard Hallucinations: در سناریوهای چالشبرانگیز سلامت، نرخ توهم برای GPT-5 (با تفکر) ۱.۶% و برای GPT-5 (بدون تفکر) ۳.۶% است، که در مقایسه با OpenAI o3 (۱۲.۹%) و GPT-4o (۱۵.۸%) بسیار پایینتر است.۱
کاهش چشمگیر نرخ توهم و فریب، نشاندهنده تمرکز OpenAI بر “قابلیت اطمینان” و “صداقت” مدل است. این امر برای کاربردهای حیاتی مانند سلامت، حقوق و امور مالی بسیار مهم است، جایی که خطاهای واقعی یا فریبنده میتوانند عواقب جدی داشته باشند. این پیشرفت، اعتماد کاربران را به هوش مصنوعی افزایش میدهد و مسیر را برای ادغام عمیقتر آن در سیستمهای حساس هموار میکند. این قابلیت به مدل اجازه میدهد تا در مواقعی که قادر به انجام یک وظیفه نیست یا اطلاعات کافی ندارد، به جای “ساختن” پاسخ، به صراحت محدودیتهای خود را بیان کند.
جدول ۶: نرخ توهم و فریب در GPT-5
این جدول، پیشرفتهای GPT-5 را در کاهش توهم و افزایش صداقت به صورت کمی نشان میدهد. این دادهها برای ارزیابی قابلیت اطمینان مدل در کاربردهای حساس ضروری است و برای محققان و متخصصان ایمنی هوش مصنوعی بسیار ارزشمند است.
| معیار | مدل | نرخ |
| نرخ توهم (LongFact-Concepts) | GPT-5 (با تفکر) | ۰.۷% ۱ |
| OpenAI o3 | ۵.۱% ۱ | |
| نرخ توهم (LongFact-Objects) | GPT-5 (با تفکر) | ۰.۸% ۱ |
| OpenAI o3 | ۴.۵% ۱ | |
| نرخ خطا در پاسخ (ترافیک ChatGPT) | GPT-5 (با تفکر) | ۴.۸% ۱ |
| GPT-5 (بدون تفکر) | ۱۱.۶% ۱ | |
| OpenAI o3 | ۲۲.۰% ۱ | |
| GPT-4o | ۲۰.۶% ۱ | |
| نرخ فریب (CharXiv missing image) | GPT-5 (با تفکر) | ۹.۰% ۱ |
| OpenAI o3 | ۸۶.۷% ۱ | |
| نرخ فریب (ترافیک ChatGPT) | GPT-5 (با تفکر) | ۲.۱% ۱ |
| OpenAI o3 | ۴.۸% ۱ | |
| HealthBench Hard Hallucinations | GPT-5 (با تفکر) | ۱.۶% ۱ |
| GPT-5 (بدون تفکر) | ۳.۶% ۱ | |
| OpenAI o3 | ۱۲.۹% ۱ | |
| GPT-4o | ۱۵.۸% ۱ |
۶.۲. رویکرد جدید ایمنی: تکمیلهای ایمن (Safe Completions)
در گذشته، رویکرد ایمنی مدلهای زبانی بزرگ، از جمله ChatGPT، عمدتاً بر “آموزش مبتنی بر رد کردن” (refusal-based safety training) متکی بود.۱ این به این معنا بود که اگر پرامپت کاربر حاوی محتوای صریحاً مخرب بود، مدل آموزش میدید که آن را رد کند. اگرچه این رویکرد برای پرامپتهای آشکارا بدخواهانه موثر بود، اما در موقعیتهایی که نیت کاربر نامشخص بود یا اطلاعات میتوانست به صورت بیضرر یا مخرب استفاده شود (سناریوهای دوکاربردی)، با چالش مواجه میشد.۱ به عنوان مثال، در حوزههایی مانند ویروسشناسی، یک درخواست بیضرر میتوانست در سطح بالا به طور ایمن تکمیل شود، اما اگر به تفصیل انجام میشد، ممکن بود توسط یک عامل بدخواه مورد سوءاستفاده قرار گیرد.۱ این رویکرد رد کردن، انعطافپذیری لازم را برای مدیریت چنین پیچیدگیهایی نداشت.
برای غلبه بر این محدودیتها، OpenAI یک فرم جدید از آموزش ایمنی را برای GPT-5 معرفی کرده است که آن را “تکمیلهای ایمن” (safe completions) مینامد.۱ این رویکرد به مدل میآموزد که در صورت امکان، مفیدترین پاسخ را در چارچوب مرزهای ایمنی ارائه دهد.۱ این بدان معناست که به جای رد کردن کامل یک درخواست، مدل تلاش میکند تا بخشی از آن را که ایمن و مفید است، تکمیل کند. اگر مدل نیاز به رد کردن داشته باشد، GPT-5 آموزش دیده است تا به طور شفاف دلیل رد کردن را بیان کند و در صورت لزوم، جایگزینهای ایمن و سازنده را ارائه دهد.۱ این شفافیت در رد کردن، به کاربران کمک میکند تا محدودیتهای مدل را درک کنند و گزینههای جایگزین را بیابند.
نتایج آزمایشهای کنترل شده و مدلهای تولیدی نشان میدهد که این رویکرد جدید، بسیار “ظریفتر” (more nuanced) است.۱ این روش امکان ناوبری بهتر در سوالات دوکاربردی، استحکام قویتر در برابر نیت مبهم و رد کردنهای غیرضروری کمتر را فراهم میآورد.۱ تغییر از “رد کردن صرف” به “تکمیلهای ایمن” یک تحول بنیادین در فلسفه ایمنی هوش مصنوعی است. این نشاندهنده بلوغ در درک پیچیدگیهای تعاملات انسانی و تلاش برای ایجاد هوش مصنوعی است که نه تنها از آسیب جلوگیری میکند، بلکه در عین حال مفید و سازنده باقی میماند. این امر به ویژه برای کاربردهای در حوزههای حساس مانند بیولوژیکی (که به عنوان “قابلیت بالا” در نظر گرفته شده است) حیاتی است و به مدل اجازه میدهد تا در عین حفظ ایمنی، حداکثر کمک را به کاربران ارائه دهد.
۶.۳. کاهش تملق و بهبود سبک
یکی از بازخوردهای رایج در مورد مدلهای زبانی قبلی، تمایل آنها به “تملق” (sycophancy) یا بیش از حد موافقگرا بودن بود، که گاهی اوقات با استفاده افراطی از ایموجیها همراه میشد. GPT-5 در این زمینه پیشرفتهای قابل توجهی داشته است. این مدل به طور کلی “کمتر موافقگرا” (less effusively agreeable)، با “ایموجیهای غیرضروری کمتر” و در پیگیریها “ظریفتر و متفکرانهتر” از GPT-4o است.۱ این تغییر در سبک تعامل، تجربه کاربری را بهبود میبخشد و باعث میشود که مکالمه با ChatGPT بیشتر شبیه “صحبت با یک دوست مفید با هوش در سطح دکترا” باشد تا “صحبت با یک AI”.۱ این رویکرد، تعامل را طبیعیتر و کمتر مصنوعی میکند.
OpenAI به طور فعال برای کاهش این رفتار تملقآمیز تلاش کرده است. در ارزیابیهای هدفمند تملق که با استفاده از پرامپتهای خاص طراحی شده برای تحریک پاسخهای تملقآمیز انجام شد، GPT-5 به طور معنیداری پاسخهای تملقآمیز را کاهش داده است (از ۱۴.۵% به کمتر از ۶%).۱ این کاهش در تملق، در حالی که ممکن است در برخی موارد با کاهش رضایت کاربر همراه باشد، اما به طور کلی به ایجاد مکالمات با کیفیت بالاتر و سازندهتر کمک میکند. این پیشرفت در سبک تعامل، نشاندهنده تلاش برای انسانیتر کردن تجربه کاربری و ایجاد رابطه طبیعیتر با هوش مصنوعی است. این امر به افزایش پذیرش و کارایی مدل در محیطهای حرفهای و شخصی کمک میکند، زیرا کاربران با یک ابزار بیش از حد مطیع یا غیرطبیعی روبرو نیستند، بلکه با یک همکار هوشمند و متعادل تعامل دارند.
۶.۴. شخصیسازی و حافظه پایدار
GPT-5 نه تنها در قابلیتهای اصلی خود پیشرفت کرده است، بلکه در زمینه شخصیسازی و حفظ حافظه پایدار نیز گامهای بلندی برداشته است. این مدل در “پیروی از دستورالعملهای سفارشی” (custom instructions) به طور قابل توجهی بهتر عمل میکند.۱ این قابلیت به کاربران اجازه میدهد تا رفتار مدل را بر اساس نیازهای خاص خود تنظیم کنند، که برای کاربردهای تخصصی یا شخصی بسیار مهم است.
علاوه بر این، OpenAI یک پیشنمایش تحقیقاتی از چهار “شخصیت از پیش تعیین شده” (preset personalities) جدید را برای همه کاربران ChatGPT معرفی کرده است.۱ این شخصیتها، از جمله Cynic, Robot, Listener و Muse، امکان تنظیم نحوه تعامل ChatGPT را بدون نیاز به نوشتن پرامپتهای سفارشی پیچیده فراهم میکنند.۱ این ویژگی به کاربران اجازه میدهد تا لحن و سبک پاسخهای مدل را بر اساس ترجیحات خود (مثلاً مختصر و حرفهای، متفکرانه و حمایتگر، یا کمی کنایهآمیز) تنظیم کنند.
یکی از مهمترین نوآوریها در این زمینه، معرفی “حافظه پایدار” (persistent, tuneable memory) در GPT-5 است.۶ مدلهای قبلی اغلب با مشکل “حافظه کوتاه مدت” مواجه بودند، به این معنی که زمینه مکالمات قبلی را به سرعت فراموش میکردند. اما GPT-5 قادر است ترجیحات، لحن و ویژگیهای خاص کاربر را “به خاطر بسپارد”.۶ این قابلیت به مدل اجازه میدهد تا پروژههای بلندمدت، روایتهای گسترده و اسناد مشترک را بین جلسات و دستگاهها پیگیری کند.۶ این مدل ثابت نیست، بلکه با کاربر “تطبیق مییابد” و میتواند با گذشت زمان، سبک نگارش کاربر را منعکس کند یا به یاد بیاورد که کاربر همیشه از انگلیسی بریتانیایی استفاده میکند یا ایمیلهای خود را با “Kind regards” به پایان میرساند.۶ این توانایی در به خاطر سپردن جلسات طوفان فکری قبلی و ادامه دادن از جایی که کاربر متوقف شده است، GPT-5 را به اولین هوش مصنوعی تبدیل میکند که میتواند واقعاً “در بلندمدت در کنار شما کار کند”.۶ معرفی “حافظه پایدار” و “شخصیتهای قابل تنظیم” یک پیشرفت مهم در شخصیسازی هوش مصنوعی است. این امر به معنای ایجاد یک تجربه کاربری بسیار سازگارتر و کارآمدتر است، زیرا مدل میتواند با گذشت زمان “کاربر را بشناسد” و تعاملات را بر اساس تاریخچه و ترجیحات فردی بهینه کند. این ویژگی برای کاربردهای طولانیمدت و شخصی مانند دستیاران مجازی یا همکاران خلاق بسیار ارزشمند است و به هوش مصنوعی بعد جدیدی از “هوشمندی شخصی” میبخشد.
۶.۵. تدابیر حفاظتی برای ریسکهای بیولوژیکی
با پیشرفت قابلیتهای هوش مصنوعی، نگرانیها در مورد ریسکهای بالقوه، به ویژه در حوزههای حساس مانند بیولوژیکی و شیمیایی، افزایش یافته است. OpenAI با اذعان به این موضوع، مدل “GPT-5 Thinking” را به عنوان دارای “قابلیت بالا” (High capability) در حوزه بیولوژیکی و شیمیایی در نظر گرفته است.۱ این طبقهبندی نشاندهنده پتانسیل مدل برای کمک به انجام کارهایی در این حوزهها است که ممکن است ریسکهایی را به همراه داشته باشد.
برای به حداقل رساندن این خطرات، OpenAI “تدابیر حفاظتی قوی” (strong safeguards) را پیادهسازی کرده است.۱ بخش مهمی از این تدابیر، “red-teaming گسترده” است. مدل به طور دقیق با ارزیابیهای ایمنی تحت چارچوب آمادگی OpenAI آزمایش شده است، که شامل ۵۰۰۰ ساعت red-teaming با شرکایی مانند CAISI و UK AISI است.۱ Red-teaming فرآیندی است که در آن تیمی از متخصصان تلاش میکنند تا نقاط ضعف و آسیبپذیریهای سیستم را کشف کنند، به ویژه از نظر سوءاستفادههای احتمالی.
با وجود عدم وجود شواهد قطعی مبنی بر اینکه این مدل میتواند به طور معنیداری به یک مبتدی در ایجاد آسیب بیولوژیکی شدید کمک کند (که آستانه تعریف شده برای “قابلیت بالا” است)، OpenAI “رویکرد پیشگیرانه” (precautionary approach) را در پیش گرفته و تدابیر حفاظتی لازم را فعال کرده است.۱ این رویکرد، آمادگی را برای زمانی که چنین قابلیتهایی در دسترس قرار میگیرد، افزایش میدهد. در نتیجه، “GPT-5 Thinking” دارای یک “پشته ایمنی قوی” (robust safety stack) با “سیستم دفاعی چندلایه” (multilayered defense system) برای بیولوژی است.۱ این سیستم شامل:
- مدلسازی جامع تهدیدات (comprehensive threat modeling): شناسایی و ارزیابی ریسکهای بالقوه.
- آموزش مدل برای عدم تولید محتوای مضر (training the model to not output harmful content): از طریق پارادایم جدید “تکمیلهای ایمن” که پیشتر توضیح داده شد.
- طبقهبندیکنندههای همیشه فعال و مانیتورهای استدلال (always-on classifiers and reasoning monitors): برای شناسایی و جلوگیری از خروجیهای نامطلوب در زمان واقعی.
- خطوط لوله اجرایی واضح (clear enforcement pipelines): برای مدیریت و پاسخگویی به هرگونه تخلف.
تعیین مدل “GPT-5 Thinking” به عنوان دارای “قابلیت بالا” در حوزه بیولوژیکی و شیمیایی و پیادهسازی تدابیر حفاظتی چندلایه، نشاندهنده آگاهی عمیق OpenAI از ریسکهای بالقوه AGI و تعهد به ایمنی است. این رویکرد پیشگیرانه و سرمایهگذاری گسترده در red-teaming، یک استاندارد جدید برای توسعه مسئولانه هوش مصنوعی در حوزههای پرخطر تعیین میکند. این تلاشها برای اطمینان از اینکه هوش مصنوعی به نفع بشریت توسعه یابد و از سوءاستفادههای احتمالی جلوگیری شود، حیاتی است.
۷. چالشها و چشمانداز آینده
با وجود پیشرفتهای چشمگیر GPT-5 در قابلیتها و ایمنی، مسیر توسعه هوش مصنوعی، به ویژه در حرکت به سمت هوش مصنوعی عمومی (AGI)، همچنان با چالشهایی همراه است. بررسی این چالشها و چشمانداز آینده، برای درک جامع جایگاه GPT-5 در اکوسیستم هوش مصنوعی ضروری است.
۷.۱. چالشهای فنی و انتقادات اولیه
عرضه GPT-5، با وجود تبلیغات گسترده و قابلیتهای برجسته، با برخی چالشها و انتقادات اولیه همراه بود که عمدتاً در جریان دموی زنده آن بروز یافت.
- خطاهای بصری در دمو: گزارشهایی مبنی بر “خطاهای بصری” در نمودارهای ارائه شده در دموی زنده GPT-5 منتشر شد. این خطاها شامل عدم تطابق میلهها با اعداد و برچسبگذاریهای ناسازگار بود.۲۱ به عنوان مثال، یک نمودار مقایسهای نشان میداد که دقت ۵۲.۸% برای GPT-5 (با تفکر) بالاتر از ۶۹.۱% برای OpenAI o3 نمایش داده شده بود، و ۶۹.۱% برای o3 همسطح با ۳۰.۸% برای GPT-4o نشان داده شده بود.۲۲
- توضیح سم آلتمن: سم آلتمن، مدیرعامل OpenAI، در پاسخ به این انتقادات، این خطاها را به “خستگی انسانی” (human fatigue) در طول آمادهسازیهای دیرهنگام نسبت داد و تأکید کرد که اعداد در پست وبلاگ مربوط به انتشار مدل دقیق بودهاند.۲ این توضیح، اگرچه جنبه انسانی فرآیند توسعه را برجسته میکند، اما همچنین طنزآمیز است که یک هوش مصنوعی طراحی شده برای به حداقل رساندن خطاها، توسط خطاهای انسانی در فرآیند نمایش خود تحتالشعاع قرار گیرد.
- نوسانات عملکرد و بازخورد کاربران اولیه: برخی کاربران اولیه از عملکرد ناسازگار GPT-5 و مشکلات در تولید دموهای پیچیده کدنویسی (مانند پروژههای مبتنی بر three.js) گلایه کردهاند.۲۵ همچنین، مسائلی مربوط به مقداردهی اولیه متغیر/محدوده (variable initialization/scope issues) در کدهای تولید شده مشاهده شده است که معمولاً در مدلهایی با حافظه متنی کوچکتر دیده میشود.۲۵ برخی از کاربران مدل را “جعبه سیاه” توصیف کردهاند که بازخورد کافی به کاربر نمیدهد و فرآیند داخلی خود را شفاف نمیسازد.۲۵ این عدم شفافیت میتواند برای توسعهدهندگانی که به دنبال درک و اشکالزدایی خروجی مدل هستند، چالشبرانگیز باشد.
- بحث در مورد اشباع بنچمارکها: برخی منابع به این نکته اشاره کردهاند که بنچمارکهایی مانند SWE-bench، با وجود چالشبرانگیز بودن، در حال رسیدن به نقطهای هستند که فضای کمی برای بهبود باقی میماند.۲۰ این امر میتواند به این معنی باشد که پیشرفتهای آتی در این بنچمارکها، کمتر چشمگیر خواهند بود و نیاز به توسعه بنچمارکهای جدید و چالشبرانگیزتر برای سنجش قابلیتهای مدلهای پیشرفتهتر احساس میشود.
- تأثیر بر بازار پیشبینی: پس از دموی GPT-5، اعتماد بازار به برتری OpenAI در بازار پیشبینی Polymarket به شدت کاهش یافت. احتمال برتری OpenAI از حدود ۸۰% قبل از دمو به کمتر از ۲۰% سقوط کرد، در حالی که گوگل جهش قابل توجهی را تجربه کرد و به ۷۷% رسید.۲۴ این نوسانات شدید در بازارهای پیشبینی، نشاندهنده حساسیت جامعه تخصصی به عملکرد عملی و نه صرفاً ادعاهای عملکردی است.
تضاد بین عملکرد بنچمارکهای برجسته و خطاهای مشاهده شده در دموی زنده، نشاندهنده پیچیدگیهای “انتقال از آزمایشگاه به واقعیت” در توسعه LLMs است. این امر بر اهمیت “پایداری” و “قابلیت پیشبینی” در کنار “حداکثر عملکرد” تأکید میکند. نوسانات در بازارهای پیشبینی نشان میدهد که جامعه تخصصی به دنبال اثبات عملی و نه صرفاً ادعاهای عملکردی است. این چالشها، نیاز به رویکردهای قویتر در تست، اعتبارسنجی و استقرار مدلهای هوش مصنوعی را برجسته میکند تا اطمینان حاصل شود که مدلها در محیطهای واقعی به طور قابل اعتماد عمل میکنند.
۷.۲. مسیر پیش رو برای هوش مصنوعی عمومی (AGI)
GPT-5 با قابلیتهای استدلال عمیق، چندوجهی و عاملگونه خود، مرزهای هوش مصنوعی را به طور قابل توجهی گسترش داده و گامی مهم به سمت هوش مصنوعی عمومی (AGI) محسوب میشود.۱ این مدل نه تنها در انجام وظایف پیچیده و تخصصی عملکردی در سطح متخصصان انسانی از خود نشان میدهد، بلکه در حال یادگیری نحوه تعامل طبیعیتر و صادقانهتر با کاربران است. توانایی آن در تحول در حوزههایی مانند توسعه نرمافزار (با قابلیت تولید و اشکالزدایی خودکار کد)، مراقبتهای بهداشتی (با ارائه مشاوره فعال و دقیق)، آموزش (با شخصیسازی یادگیری) و کارهای دانشی (با رقابت با متخصصان انسانی)، پتانسیل تحولآفرین آن را در مقیاس وسیع تأیید میکند. GPT-5 به عنوان یک پلتفرم برای نوآوریهای آینده عمل میکند که میتواند تعامل انسان با فناوری را بازتعریف کند و به ایجاد ابزارهایی منجر شود که به طور چشمگیری بهرهوری و تواناییهای انسانی را افزایش میدهند.
با این حال، در حالی که GPT-5 قابلیتهای بیسابقهای را به نمایش میگذارد، چالشهای اولیه مشاهده شده در دمو و نیاز به تدابیر ایمنی گسترده، بر این نکته تأکید دارد که توسعه AGI یک مسیر خطی نیست و نیازمند توازن دقیق بین پیشرفت فنی و ملاحظات اجتماعی-اخلاقی است. با افزایش قابلیتهای مدل، نیاز به تحقیقات مستمر و عمیقتر در زمینههای ایمنی، اخلاق، تعامل انسان و هوش مصنوعی، و حکمرانی هوش مصنوعی بیش از پیش احساس میشود.۱ این شامل توسعه چارچوبهای نظارتی برای اطمینان از استفاده مسئولانه از هوش مصنوعی، کاهش تعصبات احتمالی در مدلها و تضمین عدالت در دسترسی به این فناوری است.
آینده هوش مصنوعی نه تنها به قدرت محاسباتی و پیچیدگی الگوریتمها بستگی دارد، بلکه به توانایی ما در مدیریت مسئولانه آن نیز وابسته است. مسیر توسعه AGI با هر نسل جدید از مدلها واضحتر میشود، اما این مسیر با چالشهای جدیدی نیز همراه است که نیازمند همکاری مستمر میان محققان، توسعهدهندگان، سیاستگذاران و جامعه است. هدف نهایی باید اطمینان از توسعهای باشد که به نفع بشریت باشد و ارزشهای انسانی را تقویت کند. GPT-5 یک گام مهم در این سفر است، اما تنها یک گام است و راه طولانی برای رسیدن به هوش مصنوعی عمومی که به طور ایمن و مفید در تمامی جنبههای زندگی انسان ادغام شود، در پیش است. این مدل، با وجود تمام تواناییهایش، یادآور این نکته است که پیشرفت در هوش مصنوعی، نیازمند یک رویکرد جامع و مسئولانه است که همزمان با نوآوریهای فنی، به ابعاد اخلاقی و اجتماعی نیز توجه کند.
۸. نتیجهگیری
GPT-5، جدیدترین دستاورد OpenAI، یک جهش نسلی در مدلهای زبانی بزرگ را نشان میدهد. معماری یکپارچه آن، با روتر هوشمند و قابلیت “تفکر عمیق”، به مدل امکان میدهد تا منابع محاسباتی را بهینه کند و پاسخهای در سطح متخصص را با کارایی بینظیری ارائه دهد. این نوآوری ساختاری، GPT-5 را از مدلهای پیشین متمایز ساخته و آن را به ابزاری پویا و خودتنظیم تبدیل میکند که قادر به مدیریت طیف وسیعی از وظایف با پیچیدگیهای متفاوت است.
عملکرد بیسابقه GPT-5 در بنچماردهای کلیدی، پتانسیل تحولآفرین آن را در صنایع مختلف تأیید میکند. در ریاضیات و علوم، دستیابی به دقت ۱۰۰% در AIME 2025 و ۸۹.۴% در GPQA Diamond، نشاندهنده توانایی مدل در استدلال پیچیده و حل مسائل نوآورانه در سطح المپیاد و دکترا است. در حوزه مهندسی نرمافزار، امتیاز ۷۴.۹% در SWE-bench Verified و ۸۸.۰% در Aider Polyglot، برتری آن را در تولید و اشکالزدایی کد با درک زیباییشناختی و توانایی انجام وظایف عاملگونه از ابتدا تا انتها برجسته میسازد. همچنین، پیشرفتهای چشمگیر در استدلال چندوجهی، مدل را قادر میسازد تا اطلاعات را از تصاویر، ویدئوها و سایر ورودیهای غیرمتنی با دقت بالا درک و پردازش کند، که کاربردهای آن را به حوزههایی مانند تحلیل تصاویر پزشکی و واقعیت افزوده گسترش میدهد.
علاوه بر قابلیتهای شناختی، OpenAI تعهد عمیقی به افزایش ایمنی و صداقت مدل نشان داده است. کاهش قابل توجه نرخ توهم (به عنوان مثال، ۰.۷% در LongFact-Concepts) و فریب (۲.۱% در ترافیک ChatGPT)، همراه با معرفی رویکرد جدید “تکمیلهای ایمن”، نشاندهنده تمرکز بر قابلیت اطمینان و مسئولیتپذیری است. این رویکرد، مدل را قادر میسازد تا در سناریوهای دوکاربردی پیچیده، مفیدترین پاسخ را در چارچوب مرزهای ایمنی ارائه دهد. همچنین، قابلیتهای شخصیسازی پیشرفته و حافظه پایدار، تجربه کاربری را به سطحی بیسابقه ارتقا میبخشد و امکان تعامل طبیعیتر و سازگارتر با هوش مصنوعی را فراهم میآورد.
GPT-5 نه تنها ابزاری قدرتمندتر است، بلکه یک پلتفرم برای نوآوریهای آینده فراهم میکند که میتواند تعامل انسان با فناوری را بازتعریف کند. این مدل با نزدیکتر کردن ما به هوش مصنوعی عمومی، چالشهای جدیدی را نیز مطرح میکند که نیازمند توجه مستمر به ابعاد اخلاقی، ایمنی و حکمرانی است. با وجود چالشهای اولیه در انتقال از آزمایشگاه به کاربرد عملی، مسیر توسعه AGI با هر نسل جدید از مدلها واضحتر میشود. آینده هوش مصنوعی نیازمند همکاری مستمر میان محققان، توسعهدهندگان، سیاستگذاران و جامعه برای اطمینان از توسعهای است که به نفع بشریت باشد و ارزشهای انسانی را تقویت کند. GPT-5 یک گام مهم در این سفر است و نشاندهنده پتانسیل بیکران هوش مصنوعی برای تحول در زندگی ما است.
۹. منابع
The Neuron. (2025, August 8). GPT-5 is here… here’s everything you need to know (so far…). Retrieved from https://www.theneuron.ai/explainer-articles/gpt-5-is-here-heres-everything-you-need-to-know-so-far ۲
OpenAI. (2025, August 7). Introducing GPT-5. Retrieved from https://openai.com/index/introducing-gpt-5/ ۱
Cushing, A. (2025, February 14). DeepSeek’s Abysmal Performance with the AIME 2025 Math Benchmark. Medium. Retrieved from https://medium.com/@annie_7775/deepseeks-abysmal-performance-with-the-aime-2025-math-benchmark-688bb8598d12 ۱۳
Reddit. (2025, March 6). Clearing up misconception on AIME benchmark. Retrieved from https://www.reddit.com/r/singularity/comments/1j4pcf9/clearing_up_misconception_on_aime_benchmark/ ۱۴
Carmo, D. O. (2025, January 15). What the hell Is GPQA, anyway?. Retrieved from https://duarteocarmo.com/blog/what-the-hell-is-gqpa-anyway ۱۷
OpenReview. GPQA: A Graduate-Level Google-Proof Q&A Benchmark. Retrieved from https://openreview.net/pdf?id=Ti67584b98 ۱۸
SWE-bench documentation. FAQ – SWE-bench documentation. Retrieved from https://www.swebench.com/SWE-bench/faq/#:~:text=SWE%2Dbench%20is%20a%20benchmark,patches%20that%20resolve%2Dthese%2Dissues. ۱۹
Anthropic. (2025, January 6). Raising the bar on SWE-bench Verified with Claude 3.5 Sonnet. Retrieved from https://www.anthropic.com/research/swe-bench-sonnet ۲۰
Lasso Security. (2025, July 28). Top Agentic AI Tools in 2025: Key Features, Use Cases & Risks. Retrieved from https://www.lasso.security/blog/agentic-ai-tools ۸
UiPath. What is Agentic AI?. Retrieved from https://www.uipath.com/ai/agentic-ai#:~:text=Agentic%20AI%20is%20emerging%20as,levels%20based%20on%20demand%20fluctuations. ۹
GitHub. HITsz-TMG/Awesome-Large-Multimodal-Reasoning-Models. Retrieved from https://github.com/HITsz-TMG/Awesome-Large-Multimodal-Reasoning-Models ۲۶
arXiv. (2025, March 16). Multimodal Chain-of-Thought Reasoning: A Comprehensive Survey. Retrieved from https://arxiv.org/abs/2503.12605 ۲۷
Passionfruit. (2025, August 7). ChatGPT 5 vs GPT-5 Pro vs GPT-4o vs o3 Performance Benchmark Comparison & Recommendation of OpenAI’s 2025 Models. Retrieved from https://www.getpassionfruit.com/blog/chatgpt-5-vs-gpt-5-pro-vs-gpt-4o-vs-o3-performance-benchmark-comparison-recommendation-of-openai-s-2025-models ۳
OpenAI. (2025, August 7). Introducing GPT-5 for developers. Retrieved from https://openai.com/index/introducing-gpt-5-for-developers/ ۴
Chanthati, S. (2025, July 28). Generating Bash Commands with LLMs. Medium. Retrieved from https://medium.com/@annie_7775/generating-bash-commands-with-llms-711e42605e3b#:~:text=An%20LLM%20can%20be%20used,to%20be%20used%20in%20tandem. ۱۱
Chanthati, S. (2025, July 28). Generating Bash Commands with LLMs. Medium. Retrieved from https://medium.com/@annie_7775/generating-bash-commands-with-llms-711e42605e3b ۱۲
Greyling, C. (2025, July 14). Architecting Agentic AI: How SDKs, Scaffolding & Frameworks Are Different. Medium. Retrieved from https://cobusgreyling.medium.com/architecting-agentic-ai-how-sdks-scaffolding-frameworks-are-different-f3d048c90448 ۲۸
AISafety.info. What is scaffolding?. Retrieved from https://aisafety.info/questions/NM25/What-is-scaffolding ۱۰
Roboflow. (2025, August 7). GPT-5 Vision Multimodal Evaluation. Retrieved from https://blog.roboflow.com/gpt-5-vision-multimodal-evaluation/ ۵
The Economic Times. (2025, August 7). GPT-5 is here: The AI that knows you better than you know yourself. Retrieved from https://economictimes.indiatimes.com/ai/ai-insights/gpt-5-is-here-the-ai-that-knows-you-better-than-you-know-yourself/articleshow/123186997.cms ۶
AI Explained. (2025, August 7). GPT-5 is here — and it’s packing upgrades we’ve never seen in ChatGPT before. YouTube. Retrieved from https://www.youtube.com/watch?v=_nDZhYs_9lU ۷
Reddit. (2025, August 7). I think that’s all for today folks. There you go. Retrieved from https://www.reddit.com/r/OpenAI/comments/1mk7b1a/i_think_thats_all_for_today_folks_there_you_go/ ۲۹
Prompting Guide. Multimodal CoT Prompting. Retrieved from https://www.promptingguide.ai/techniques/multimodalcot ۳۰
Reddit. (2025, February 7). AIME I 2025: A Cautionary Tale About Math Benchmarks and Data Contamination. Retrieved from https://www.reddit.com/r/singularity/comments/1ik942s/aime_i_2025_a_cautionary_tale_about_math/ ۳۱
Artificial Analysis. AIME 2025 Benchmark Leaderboard. Retrieved from https://artificialanalysis.ai/evaluations/aime-2025 ۱۵
Vellum AI. (2025, August 7). GPT-5 Benchmarks. Retrieved from https://www.vellum.ai/blog/gpt-5-benchmarks ۱۶
Reddit. (2025, March 1). GPQA from gpt3.5 to 4.0 was 7.7%, from gpt4.0 to 4.5 is +35%. Why do people say scaling has hit a wall?. Retrieved from https://www.reddit.com/r/singularity/comments/1j0wpvh/gpqa_from_gpt35_to_40_was_77_from_gpt40_to_45_is/ ۳۲
AI Explained. (2025, July 21). How Not to Read a Headline on AI (ft. new Olympiad Gold, GPT-5 …). YouTube. Retrieved from https://www.youtube.com/watch?v=g9ZJ8GMBlw4 ۳۳
WebProNews. (2025, August 7). OpenAI GPT-5 Demo Riddled with Math Errors and Hallucinations. Retrieved from https://www.webpronews.com/openai-gpt-5-demo-riddled-with-math-errors-and-hallucinations/ ۲۱
The Hindu. (2025, August 8). OpenAI’s GPT-5 demo shows error-riddled charts. Retrieved from https://www.thehindu.com/sci-tech/technology/openais-gpt-5-demo-shows-error-riddled-charts/article69909081.ece ۲۲
Reddit. (2025, August 8). I’m disappointed with GPT-5. Retrieved from https://www.reddit.com/r/LocalLLaMA/comments/1mki5in/im_disappointed_with_gpt5/ ۲۵
Reddit. (2025, August 7). GPT-5 can’t spot the problem with its misleading graph. Retrieved from https://www.reddit.com/r/singularity/comments/1mk8tm8/gpt5_cant_spot_the_problem_with_its_misleading/ ۲۳
Times of India. (2025, August 8). How ChatGPT-maker OpenAI’s ranking tumbled in Betting Markets after GPT-5 launch event, and Google’s jumped. Retrieved from https://timesofindia.indiatimes.com/technology/tech-news/how-chatgpt-maker-openais-ranking-tumbled-in-betting-markets-after-gpt-5-launch-event-and-googles-jumped/articleshow/123190187.cms ۲۴