

مقدمه

هوش مصنوعی (AI) امروز بیش از هر زمان دیگری در کانون توجه قرار گرفته است. از خودروهای خودران گرفته تا توصیهگرهای فیلم و موسیقی، از چتباتها تا پردازش تصویر؛ همه جا نشانی از هوش مصنوعی دیده میشود. اما آیا میدانیم واقعاً AI چیست؟ این فناوری شگفتانگیز چگونه تعریف میشود؟ و چرا درک آن تا این حد دشوار شده است؟ در این مقاله بهطور تخصصی و قابلفهم به بررسی چیستی هوش مصنوعی، کاربردها و برداشتهای متفاوت از آن میپردازیم.
تعریف هوش مصنوعی چیست؟
هوش مصنوعی از دید تخصصی
تا به امروز هیچ تعریف رسمی و واحدی از هوش مصنوعی وجود ندارد. حتی در میان پژوهشگران این حوزه نیز توافق دقیقی بر سر تعریف آن نیست. با این حال، بهطور کلی میتوان AI را مجموعهای از فناوریها دانست که هدف آنها شبیهسازی یا جایگزینی برخی از تواناییهای شناختی انسان مانند یادگیری، استدلال، ادراک و تصمیمگیری است.
کاربردهای مهم هوش مصنوعی


۱. خودروهای خودران
کاربردها:
خودروهای خودران از ترکیب پیچیدهای از تکنیکهای AI استفاده میکنند:
- جستجو و برنامهریزی مسیر برای یافتن بهترین راه از مبدأ تا مقصد.
- بینایی ماشین برای شناسایی موانع و علائم راهنمایی.
- تصمیمگیری در شرایط عدم قطعیت برای مواجهه با محیط پویا و متغیر.
تأثیرات:
- بهبود ایمنی جادهها.
- افزایش بهرهوری در زنجیرههای حملونقل.
- نقش ناظر انسانی به جای راننده فعال.
| مؤلفه | تکنولوژی مورد استفاده |
|---|---|
| تشخیص اشیاء | بینایی ماشین |
| مسیریابی | الگوریتمهای جستجو و بهینهسازی |
| تصمیمگیری | مدلهای یادگیری تقویتی و احتمالاتی |

۲. سیستمهای توصیهگر محتوا
کاربردها:
از رسانههای اجتماعی گرفته تا سرویسهای پخش فیلم و موسیقی، اکثر محتواهایی که امروزه با آنها روبرو میشویم شخصیسازی شدهاند. الگوریتمهای توصیهگر مبتنی بر AI در پلتفرمهایی چون TikTok، Netflix، Spotify و Google نقش محوری دارند.
تأثیرات:
- شکلگیری پدیدههایی مانند اتاق پژواک (Echo Chamber) و حباب فیلتر (Filter Bubble).
- پتانسیل سوءاستفاده در قالب اخبار جعلی یا کارخانههای ترول.
محتوای دیجیتال دیگر یکسان برای همه نیست؛ هر کاربر نسخهای منحصربهفرد از جهان را میبیند.

۳. پردازش تصویر و ویدئو
کاربردها:
- تشخیص چهره در شبکههای اجتماعی و کنترل نواحی مرزی.
- تحلیل حیاتوحش از طریق شناسایی تصویری.
- ایجاد محتوا با تکنیکهایی مانند سبکانتقال (Style Transfer) یا تولید چهرههای مجازی در فیلمهایی مانند آواتار یا ارباب حلقهها.
تأثیرات:
- ساخت ویدئوهای جعلی اما کاملاً طبیعی (Deepfake).
- به چالش کشیدهشدن مفهوم «دیدن یعنی باور کردن».

=چرا درک دقیق AI دشوار است؟
۱. نبود تعریف رسمی
هوش مصنوعی همیشه در حال بازتعریف است. تکنولوژیهایی که یک دهه قبل AI تلقی میشدند، امروز بخشی از مهندسی نرمافزار یا آمار محسوب میشوند.
۲. میراث داستانهای علمی-تخیلی
از رباتهای خدمتکار تا ماشینهای شورشی، تخیلات ادبیات و سینما برداشتهای غیرواقعی اما تأثیرگذار از AI ایجاد کردهاند که گاه بیش از دانش واقعی در ذهن مردم ماندهاند.
۳. خطای درک دشواری
کارهایی مثل شناسایی اشیاء یا گرفتن یک لیوان برای انسان آسان اما برای ماشین فوقالعاده دشوارند. در مقابل، مسائلی مثل شطرنج یا ریاضی که برای انسانها سختاند، برای کامپیوترها سادهتر قابلحل هستند.
هوش مصنوعی بیشتر از آنکه یک تعریف داشته باشد، یک طیف است؛ از الگوریتمهای ساده گرفته تا سیستمهایی که به خودیادگیری میپردازند.
جمعبندی
هوش مصنوعی حوزهای پویا، گسترده و چندوجهی است. از تکنولوژیهایی که پشت محتوای دیجیتال روزانه ما هستند تا سامانههای خودران و ابزارهای خلاقانه، AI بخشی از زندگی ما شده است. اما درک دقیق آن نیازمند جدایی بین واقعیت و تخیل، و شناخت عمیقتر از فناوریها و کاربردهای موجود است.
پرسش و پاسخ
۱. آیا هر نوع فناوری دیجیتال را میتوان AI نامید؟
خیر. تنها فناوریهایی که قابلیت یادگیری، تطبیق یا تصمیمگیری خودکار دارند در حوزه AI قرار میگیرند.
۲. تفاوت بین AI، یادگیری ماشین (ML) و یادگیری عمیق (DL) چیست؟
AI حوزه کلیتر است؛ ML یکی از زیرمجموعههای آن است که به یادگیری از دادهها میپردازد و DL خود زیرمجموعهای از ML است که بر شبکههای عصبی عمیق تکیه دارد.
۳. آیا AI میتواند جایگزین کامل انسان شود؟
در برخی وظایف بله، اما در بسیاری از حوزهها به تعامل انسان و ماشین نیاز است.
۴. آیا AI تهدیدی برای امنیت اطلاعات است؟
همانند هر فناوری دیگر، AI نیز میتواند هم ابزار حفاظت و هم تهدید باشد. بستگی به نحوه استفاده دارد.
۵. آیا میتوان به ویدئوهای ساختهشده با AI اعتماد کرد؟
نه همیشه؛ با پیشرفت Deepfake، راستیآزمایی منابع از اهمیت بالاتری برخوردار شده است.
نقشهبرداری از هوش مصنوعی: درک روابط بین AI، یادگیری ماشین، یادگیری عمیق، علم داده و علوم کامپیوتر
هوش مصنوعی (Artificial Intelligence یا AI) به سرعت در حال تحول است و درک دقیق از زیرشاخهها و حوزههای مرتبط با آن برای متخصصان و علاقهمندان ضروری است. در ادامه این مقاله، به بررسی روابط بین هوش مصنوعی، یادگیری ماشین (Machine Learning)، یادگیری عمیق (Deep Learning)، علم داده (Data Science) و علوم کامپیوتر (Computer Science) میپردازیم و با استفاده از دیاگرام اویلر، ساختار سلسلهمراتبی این حوزهها را تحلیل میکنیم.
ساختار سلسلهمراتبی حوزههای مرتبط با هوش مصنوعی
هوش مصنوعی (AI)
هوش مصنوعی شاخهای از علوم کامپیوتر است که به توسعه سیستمهایی میپردازد که قادر به انجام وظایفی هستند که به طور معمول نیاز به هوش انسانی دارند. این وظایف شامل یادگیری، استدلال، درک زبان طبیعی و ادراک بصری میشوند.
یادگیری ماشین (Machine Learning)
یادگیری ماشین زیرمجموعهای از هوش مصنوعی است که بر توسعه الگوریتمهایی تمرکز دارد که به سیستمها امکان میدهد از دادهها یاد بگیرند و عملکرد خود را بهبود بخشند بدون اینکه به طور صریح برنامهریزی شوند.
یادگیری عمیق (Deep Learning)
یادگیری عمیق زیرمجموعهای از یادگیری ماشین است که از شبکههای عصبی مصنوعی با لایههای متعدد برای مدلسازی و درک الگوهای پیچیده در دادهها استفاده میکند.
علم داده (Data Science)
علم داده حوزهای است که به استخراج دانش و بینش از دادهها میپردازد. این حوزه شامل تکنیکهایی از آمار، یادگیری ماشین و تحلیل دادهها است و در زمینههای مختلفی مانند کسبوکار، علوم اجتماعی و زیستی کاربرد دارد.
علوم کامپیوتر (Computer Science)
علوم کامپیوتر زمینهای گسترده است که به مطالعه الگوریتمها، ساختار دادهها، معماری کامپیوتر و توسعه نرمافزار میپردازد. هوش مصنوعی یکی از زیرشاخههای این حوزه محسوب میشود.

دیاگرام اویلر: نمایش تصویری روابط بین حوزهها
برای درک بهتر روابط بین این حوزهها، از دیاگرام اویلر استفاده میکنیم:
- علوم کامپیوتر: دایرهای بزرگ که شامل همه حوزههای مرتبط است.
- هوش مصنوعی: دایرهای درون علوم کامپیوتر که به توسعه سیستمهای هوشمند میپردازد.
- یادگیری ماشین: دایرهای درون هوش مصنوعی که بر الگوریتمهای یادگیری از دادهها تمرکز دارد.
- یادگیری عمیق: دایرهای درون یادگیری ماشین که از شبکههای عصبی برای مدلسازی استفاده میکند.
- یادگیری ماشین: دایرهای درون هوش مصنوعی که بر الگوریتمهای یادگیری از دادهها تمرکز دارد.
- هوش مصنوعی: دایرهای درون علوم کامپیوتر که به توسعه سیستمهای هوشمند میپردازد.
- علم داده: دایرهای که با علوم کامپیوتر و یادگیری ماشین همپوشانی دارد، اما حوزهای مستقل با تمرکز بر تحلیل دادهها است.
جدول مقایسهای حوزهها
| حوزه | زیرمجموعهی | تمرکز اصلی | تکنیکهای کلیدی |
|---|---|---|---|
| علوم کامپیوتر | – | الگوریتمها، ساختار دادهها، نرمافزار | برنامهنویسی، طراحی الگوریتم |
| هوش مصنوعی | علوم کامپیوتر | توسعه سیستمهای هوشمند | یادگیری ماشین، منطق، استدلال |
| یادگیری ماشین | هوش مصنوعی | یادگیری از دادهها | الگوریتمهای یادگیری نظارتشده و بدون نظارت |
| یادگیری عمیق | یادگیری ماشین | مدلسازی الگوهای پیچیده | شبکههای عصبی عمیق |
| علم داده | مستقل (با همپوشانی) | استخراج دانش از دادهها | تحلیل آماری، یادگیری ماشین، مصورسازی |
جمعبندی
درک روابط بین هوش مصنوعی، یادگیری ماشین، یادگیری عمیق، علم داده و علوم کامپیوتر برای هر فردی که در حوزه فناوری فعالیت میکند، ضروری است. این حوزهها به طور تنگاتنگی با یکدیگر مرتبط هستند و درک ساختار سلسلهمراتبی آنها میتواند به توسعه مهارتها و دانش در این زمینه کمک کند.
پرسش و پاسخهای متداول
۱. تفاوت بین یادگیری ماشین و یادگیری عمیق چیست؟
یادگیری ماشین به توسعه الگوریتمهایی میپردازد که از دادهها یاد میگیرند، در حالی که یادگیری عمیق زیرمجموعهای از یادگیری ماشین است که از شبکههای عصبی با لایههای متعدد برای مدلسازی استفاده میکند.
۲. آیا علم داده بخشی از هوش مصنوعی است؟
علم داده حوزهای مستقل است که با هوش مصنوعی و یادگیری ماشین همپوشانی دارد، اما تمرکز اصلی آن بر تحلیل و استخراج دانش از دادهها است.
۳. چگونه میتوانم وارد حوزه یادگیری ماشین شوم؟
شروع با یادگیری مفاهیم پایهای آمار، برنامهنویسی (مانند Python) و مطالعه الگوریتمهای یادگیری ماشین میتواند مفید باشد. دورههای آنلاین و منابع آموزشی متعددی در این زمینه وجود دارد.
۴. کاربردهای اصلی یادگیری عمیق چیست؟
یادگیری عمیق در حوزههایی مانند تشخیص تصویر، پردازش زبان طبیعی، ترجمه ماشینی و تشخیص گفتار کاربردهای گستردهای دارد.
۵. آیا برای یادگیری هوش مصنوعی باید حتماً علوم کامپیوتر خوانده باشم؟
خیر، اما داشتن دانش پایهای در برنامهنویسی و ریاضیات میتواند یادگیری مفاهیم هوش مصنوعی را تسهیل کند.
فلسفه هوش مصنوعی: از آزمون تورینگ تا اتاق چینی
هوش مصنوعی (Artificial Intelligence) تنها یک فناوری نیست؛ بلکه دریچهای به سوی پرسشهای عمیق فلسفی درباره ذهن، آگاهی و درک است. از زمان معرفی آزمون تورینگ تا بحثهای پیرامون اتاق چینی، فیلسوفان و دانشمندان به دنبال درک ماهیت واقعی هوش مصنوعی بودهاند. در این مقاله، به بررسی این مفاهیم و تأثیر آنها بر درک ما از هوش مصنوعی میپردازیم.


آزمون تورینگ: آیا ماشینها میتوانند فکر کنند؟
آلن تورینگ، ریاضیدان برجسته بریتانیایی، در سال ۱۹۵۰ مقالهای با عنوان “ماشینهای محاسباتی و هوش” منتشر کرد. در این مقاله، او آزمونی به نام “بازی تقلید” یا همان آزمون تورینگ را معرفی کرد. در این آزمون، یک قاضی انسانی با دو شرکتکننده (یکی انسان و دیگری ماشین) از طریق نوشتار ارتباط برقرار میکند. اگر قاضی نتواند تشخیص دهد کدام شرکتکننده ماشین است، ماشین آزمون را گذرانده است.
هدف تورینگ از این آزمون، پاسخ به سؤال “آیا ماشینها میتوانند فکر کنند؟” بود. او معتقد بود که اگر ماشین بتواند رفتار انسانی را بهطور مؤثر تقلید کند، میتوان آن را هوشمند دانست.


اتاق چینی: تقلید کافی است!
جان سرل، فیلسوف آمریکایی، در سال ۱۹۸۰ آزمایش فکری “اتاق چینی” را معرفی کرد تا به نقد آزمون تورینگ بپردازد. در این آزمایش، فردی که زبان چینی نمیداند در اتاقی قرار دارد و با استفاده از دستورالعملهایی، به سؤالات چینی پاسخ میدهد. اگرچه پاسخها صحیح به نظر میرسند، اما فرد داخل اتاق هیچ درکی از زبان چینی ندارد.
سرل با این آزمایش نشان داد که صرف تقلید رفتار هوشمندانه به معنای درک واقعی نیست. او استدلال کرد که ماشینها ممکن است رفتار هوشمندانهای از خود نشان دهند، اما این به معنای داشتن ذهن یا آگاهی نیست.
هوش مصنوعی قوی و ضعیف: تفاوت در درک و عملکرد
در بحثهای فلسفی، دو نوع هوش مصنوعی مطرح میشود:
- هوش مصنوعی ضعیف (Weak AI): سیستمهایی که رفتار هوشمندانه را تقلید میکنند بدون اینکه درک واقعی داشته باشند.
- هوش مصنوعی قوی (Strong AI): سیستمهایی که نهتنها رفتار هوشمندانه دارند، بلکه دارای درک و آگاهی واقعی هستند.
بیشتر سیستمهای هوش مصنوعی امروزی، مانند دستیارهای صوتی و سیستمهای توصیهگر، در دسته هوش مصنوعی ضعیف قرار میگیرند. تحقق هوش مصنوعی قوی هنوز در حد نظریه و پژوهشهای اولیه است.
هوش مصنوعی عمومی و محدود: گستره تواناییها
هوش مصنوعی را میتوان از نظر گستره تواناییها به دو دسته تقسیم کرد:
- هوش مصنوعی محدود (Narrow AI): سیستمهایی که برای انجام وظایف خاصی طراحی شدهاند، مانند تشخیص چهره یا ترجمه زبان.
- هوش مصنوعی عمومی (General AI): سیستمهایی که قادر به انجام هر وظیفه فکری انسانی هستند.
در حال حاضر، بیشتر پیشرفتها در حوزه هوش مصنوعی محدود بوده است. تحقق هوش مصنوعی عمومی چالشهای فنی و فلسفی بسیاری دارد.
جدول مقایسهای: هوش مصنوعی قوی و ضعیف
| ویژگیها | هوش مصنوعی ضعیف | هوش مصنوعی قوی |
|---|---|---|
| درک واقعی | ندارد | دارد |
| تقلید رفتار انسانی | دارد | دارد |
| آگاهی و ذهن | ندارد | دارد |
| مثالها | دستیارهای صوتی | هوش مصنوعی عمومی (نظری) |
جمعبندی
فلسفه هوش مصنوعی به ما کمک میکند تا درک عمیقتری از ماهیت هوش، آگاهی و درک در ماشینها داشته باشیم. آزمون تورینگ و اتاق چینی دو دیدگاه متفاوت درباره تواناییهای ماشینها ارائه میدهند. در حالی که آزمون تورینگ بر تقلید رفتار انسانی تمرکز دارد، اتاق چینی بر اهمیت درک واقعی تأکید میکند. با پیشرفت فناوری، این پرسشها اهمیت بیشتری پیدا میکنند و نیاز به بررسیهای فلسفی و اخلاقی بیشتری دارند.
پرسش و پاسخ
- آیا گذراندن آزمون تورینگ به معنای داشتن آگاهی است؟
- خیر، گذراندن آزمون تورینگ نشاندهنده توانایی تقلید رفتار انسانی است، نه لزوماً داشتن آگاهی یا درک واقعی.
- تفاوت اصلی بین هوش مصنوعی قوی و ضعیف چیست؟
- هوش مصنوعی ضعیف رفتار هوشمندانه را تقلید میکند بدون درک واقعی، در حالی که هوش مصنوعی قوی دارای درک و آگاهی واقعی است.
- آیا هوش مصنوعی عمومی در حال حاضر وجود دارد؟
- خیر، هوش مصنوعی عمومی هنوز در مرحله نظریه و پژوهش است و تحقق آن چالشهای بسیاری دارد.
- اتاق چینی چه نقدی بر آزمون تورینگ وارد میکند؟
- اتاق چینی نشان میدهد که تقلید رفتار هوشمندانه لزوماً به معنای درک واقعی نیست و ماشینها ممکن است بدون درک، پاسخهای مناسب ارائه دهند.
- چرا درک فلسفی از هوش مصنوعی مهم است؟
- درک فلسفی به ما کمک میکند تا محدودیتها و تواناییهای واقعی ماشینها را بشناسیم و از سوءتفاهمها جلوگیری کنیم.
حل مسئله با هوش مصنوعی؛ از الگوریتمهای جستوجو تا بازیهای فکری
حل مسئله یکی از بنیادیترین تواناییهای هوش مصنوعی است. بسیاری از چالشهایی که سیستمهای هوشمند با آن مواجه میشوند، از جستجوی ساده مسیر در نقشه گرفته تا برنامهریزی پیچیده در بازیهای رایانهای و خودروهای خودران، در قالب مسئلهای قابل حل توسط الگوریتمهای جستجو و برنامهریزی مطرح میشوند. در این مقاله، با نگاهی دقیق به مفاهیم پایهای «جستجو» و «حل مسئله» در هوش مصنوعی، از یک معمای کلاسیک و سرگرمکننده شروع میکنیم و سپس به مفاهیم پیشرفتهتر میپردازیم.
ساختار حل مسئله در هوش مصنوعی
تعریف مسئله و هدف
پیش از آنکه یک سیستم هوشمند بتواند به حل مسئله بپردازد، باید ابتدا تعریف روشنی از مسئله، انتخابهای ممکن، و پیامدهای هر انتخاب داشته باشیم. همچنین، باید مشخص کنیم چه زمانی مسئله «حل شده» تلقی میشود.
مثال کاربردی: از هتل تا رستوران
تصور کنید در شهری ناآشنا هستید و میخواهید از محل اقامتتان با حملونقل عمومی به رستورانی بروید. نخستین کاری که میکنید چیست؟ احتمالاً گوشی هوشمند خود را بیرون میآورید، مقصد را وارد میکنید و مسیر پیشنهادی را دنبال میکنید. این یک مثال واقعی از مسئله جستجو در محیط استاتیک است که دقیقاً مشابه کاری است که یک خودروی خودران انجام میدهد.
دو دستهبندی رایج در مسائل جستجو
۱. مسائل جستجو و برنامهریزی در محیطهای ایستا با یک عامل (Agent)
در این نوع مسائل، تنها یک عامل هوشمند (مثلاً ربات) در محیط فعالیت میکند. سیستم باید با در نظر گرفتن وضعیت محیط، تصمیمگیری کند که کدام دنباله از اقدامات، آن را به هدف نزدیکتر میکند.
۲. بازیها با حضور دو عامل رقابتی
در اینگونه مسائل، عامل دوم (مثلاً یک رقیب یا دشمن در بازی شطرنج) نیز فعالانه تلاش میکند شما را از رسیدن به هدف بازدارد. در اینجا، پیشبینی و واکنش به اقدامات عامل دیگر نیز وارد بازی میشود.


معمای کلاسیک: عبور مرغ از رودخانه
برای درک بهتر مفاهیم جستجو، بیایید به یک معمای کلاسیک و سرگرمکننده بپردازیم.
مسئله چیست؟
یک ربات با یک قایق پارویی باید سه شیء را از یک سمت رودخانه (سمت نزدیک) به سمت دیگر (سمت دور) منتقل کند. این سه شیء عبارتاند از:
- یک روباه
- یک مرغ
- یک کیسه غذای مرغ
اما دو محدودیت مهم وجود دارد:
- اگر روباه تنها با مرغ بماند، آن را میخورد.
- اگر مرغ تنها با غذای مرغ بماند، آن را میخورد.
ظرفیت قایق: ربات تنها کسی است که میتواند قایق را حرکت دهد، و قایق تنها میتواند ربات و حداکثر دو شیء را همزمان حمل کند.
هدف: ربات باید تمام سه شیء (روباه، مرغ، خوراک مرغ) را به سلامت به سمت دور رودخانه منتقل کند.
نکته: این نسخه از معما نسبت به نسخههای دیگر سادهتر است، زیرا قایق میتواند دو شیء را همزمان حمل کند. نسخههای دشوارتر (که قایق تنها یک شیء را حمل میکند) را میتوانید بعداً به عنوان تمرین حل کنید.
مدلسازی مسئله بهصورت وضعیت (State)
برای حل این معما، ابتدا باید تمام موقعیتهای ممکن (حالتها) را مشخص کنیم. در این معما، چهار چیز جابهجا میشوند:
- ربات
- روباه
- مرغ
- خوراک مرغ
چون ربات تنها کسی است که میتواند قایق را حرکت دهد، ربات و قایق همیشه در یک سمت رودخانه هستند. بنابراین، ما فقط موقعیت ربات، روباه، مرغ و خوراک مرغ را در نظر میگیریم. هر یک از این چهار چیز میتواند در یکی از دو مکان باشد:
- N (Near side): سمت نزدیک
- F (Far side): سمت دور
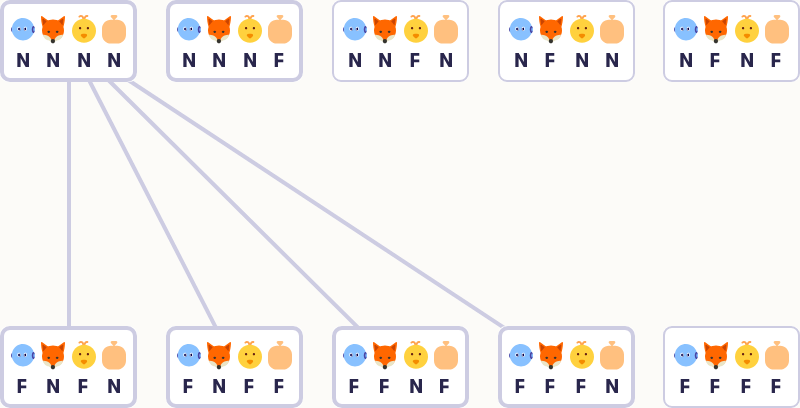
با توجه به اینکه هر کدام از این چهار چیز (ربات، روباه، مرغ، خوراک مرغ) میتوانند در یکی از دو حالت (N یا F) باشند، در مجموع ۱۶ حالت ممکن وجود دارد (۲ به توان ۴). این حالتها را در جدول زیر نمایش میدهیم:
جدول حالتهای معمای عبور مرغ
| حالت | ربات | روباه | مرغ | خوراک مرغ |
|---|---|---|---|---|
| NNNN | سمت نزدیک | سمت نزدیک | سمت نزدیک | سمت نزدیک |
| NNNF | سمت نزدیک | سمت نزدیک | سمت نزدیک | سمت دور |
| NNFN | سمت نزدیک | سمت نزدیک | سمت دور | سمت نزدیک |
| NNFF | سمت نزدیک | سمت نزدیک | سمت دور | سمت دور |
| NFNN | سمت نزدیک | سمت دور | سمت نزدیک | سمت نزدیک |
| NFNF | سمت نزدیک | سمت دور | سمت نزدیک | سمت دور |
| NFFN | سمت نزدیک | سمت دور | سمت دور | سمت نزدیک |
| NFFF | سمت نزدیک | سمت دور | سمت دور | سمت دور |
| FNNN | سمت دور | سمت نزدیک | سمت نزدیک | سمت نزدیک |
| FNNF | سمت دور | سمت نزدیک | سمت نزدیک | سمت دور |
| FNFN | سمت دور | سمت نزدیک | سمت دور | سمت نزدیک |
| FNFF | سمت دور | سمت نزدیک | سمت دور | سمت دور |
| FFNN | سمت دور | سمت دور | سمت نزدیک | سمت نزدیک |
| FFNF | سمت دور | سمت دور | سمت نزدیک | سمت دور |
| FFFN | سمت دور | سمت دور | سمت دور | سمت نزدیک |
| FFFF | سمت دور | سمت دور | سمت دور | سمت دور |
توضیح جدول:
- هر حالت با یک کد چهار حرفی (مثل NNNN یا FFFF) نشان داده شده است.
- حرف اول موقعیت ربات، حرف دوم موقعیت روباه، حرف سوم موقعیت مرغ و حرف چهارم موقعیت خوراک مرغ را نشان میدهد.
- حالت اولیه: NNNN (همه چیز در سمت نزدیک است).
- حالت هدف: FFFF (همه چیز در سمت دور است).
توضیح معمای عبور
حالتهای ممنوعه
برخی از این ۱۶ حالت به دلیل شرایط معما غیرمجاز هستند، زیرا اگر ربات حضور نداشته باشد، روباه مرغ را میخورد یا مرغ خوراک مرغ را میخورد. حالتهای ممنوعه عبارتاند از:
- روباه و مرغ بدون ربات در یک سمت باشند:
- NFFN: ربات در سمت نزدیک، روباه و مرغ در سمت دور (روباه مرغ را میخورد).
- NFFF: ربات در سمت نزدیک، روباه و مرغ در سمت دور (روباه مرغ را میخورد).
- FNNN: ربات در سمت دور، روباه و مرغ در سمت نزدیک (روباه مرغ را میخورد).
- FNNF: ربات در سمت دور، روباه و مرغ در سمت نزدیک (روباه مرغ را میخورد).
- مرغ و خوراک مرغ بدون ربات در یک سمت باشند:
- NNFF: ربات در سمت نزدیک، مرغ و خوراک مرغ در سمت دور (مرغ خوراک را میخورد).
- FFNN: ربات در سمت دور، مرغ و خوراک مرغ در سمت نزدیک (مرغ خوراک را میخورد).
بنابراین، این ۶ حالت (NFFN، NFFF، FNNN، FNNF، NNFF، FFNN) غیرمجاز هستند و ما با ۱۰ حالت مجاز باقی میمانیم:
جدول حالتهای مجاز
| حالت | ربات | روباه | مرغ | خوراک مرغ |
|---|---|---|---|---|
| NNNN | سمت نزدیک | سمت نزدیک | سمت نزدیک | سمت نزدیک |
| NNNF | سمت نزدیک | سمت نزدیک | سمت نزدیک | سمت دور |
| NNFN | سمت نزدیک | سمت نزدیک | سمت دور | سمت نزدیک |
| NFNN | سمت نزدیک | سمت دور | سمت نزدیک | سمت نزدیک |
| NFNF | سمت نزدیک | سمت دور | سمت نزدیک | سمت دور |
| FNFN | سمت دور | سمت نزدیک | سمت دور | سمت نزدیک |
| FNFF | سمت دور | سمت نزدیک | سمت دور | سمت دور |
| FFNF | سمت دور | سمت دور | سمت نزدیک | سمت دور |
| FFFN | سمت دور | سمت دور | سمت دور | سمت نزدیک |
| FFFF | سمت دور | سمت دور | سمت دور | سمت دور |
انتقال بین حالتها
حالا که حالتهای مجاز را شناسایی کردیم، باید بررسی کنیم که ربات چگونه میتواند از یک حالت به حالت دیگر منتقل شود. هر انتقال به این معناست که ربات با قایق از یک سمت رودخانه به سمت دیگر حرکت میکند و میتواند حداکثر دو شیء (روباه، مرغ یا خوراک مرغ) را با خود ببرد.
قوانین انتقال:
- ربات همیشه با قایق حرکت میکند، بنابراین حرف اول کد حالت (موقعیت ربات) در هر انتقال از N به F یا از F به N تغییر میکند.
- ربات میتواند ۰، ۱ یا ۲ شیء را با خود ببرد.
- انتقالها متقارن هستند: اگر ربات بتواند از حالت NNNN به FNFN برود، میتواند از FNFN به NNNN برگردد.
برای درک بهتر، حالتها را به دو گروه تقسیم میکنیم:
- حالتهایی که با N شروع میشوند (ربات در سمت نزدیک).
- حالتهایی که با F شروع میشوند (ربات در سمت دور).

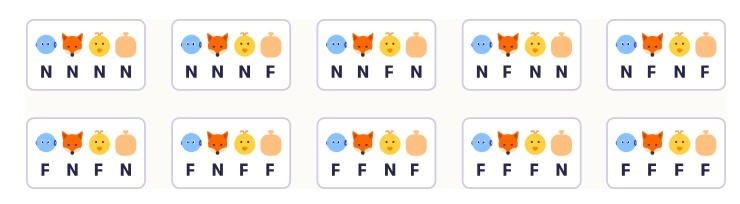
نمونه انتقالها:
از حالت اولیه NNNN (همه در سمت نزدیک):
- ربات میتواند مرغ و روباه را ببرد → به حالت FNFN میرسد.
- ربات میتواند مرغ و خوراک مرغ را ببرد → به حالت FNFF میرسد.
- ربات میتواند روباه و خوراک مرغ را ببرد → به حالت FFNF میرسد.
- ربات میتواند روباه و مرغ را ببرد → به حالت FFFN میرسد.
به همین ترتیب، میتوان تمام انتقالهای ممکن را برای هر حالت محاسبه کرد. برای سادهسازی، این انتقالها را میتوان بهصورت یک نمودار (گراف) نمایش داد، که در آن هر حالت یک گره (Node) و هر انتقال یک یال (Edge) است.
یافتن مسیر حل

اکنون که حالتها و انتقالهای مجاز را مشخص کردیم، هدف این است که مسیری از حالت اولیه (NNNN) به حالت هدف (FFFF) پیدا کنیم، بهطوریکه هیچیک از حالتهای ممنوعه رخ ندهد. یکی از مسیرهای ممکن به شرح زیر است:

- از NNNN به FFFN:
- ربات روباه و مرغ را به سمت دور میبرد.
- حالت: ربات (F)، روباه (F)، مرغ (F)، خوراک مرغ (N).
- از FFFN به NFNN:
- ربات مرغ را به سمت نزدیک برمیگرداند.
- حالت: ربات (N)، روباه (F)، مرغ (N)، خوراک مرغ (N).
- از NFNN به FFFF:
- ربات مرغ و خوراک مرغ را به سمت دور میبرد.
- حالت: ربات (F)، روباه (F)، مرغ (F)، خوراک مرغ (F).
جدول مسیر حل
| گام | حالت | اقدام ربات |
|---|---|---|
| ۱ | NNNN | ربات روباه و مرغ را به سمت دور میبرد |
| ۲ | FFFN | ربات مرغ را به سمت نزدیک برمیگرداند |
| ۳ | NFNN | ربات مرغ و خوراک مرغ را به سمت دور میبرد |
| ۴ | FFFF | هدف達成 شد! |
مفاهیم کلیدی در حل مسئله
برای حل این معما بهصورت سیستماتیک، از مفاهیم زیر استفاده کردیم:
- فضای حالت (State Space):
- مجموعه تمام موقعیتهای ممکن در مسئله.
- در این معما، فضای حالت شامل ۱۰ حالت مجاز (از NNNN تا FFFF) است.
- مثال دیگر: اگر بخواهید از نقطه A به B در یک شهر بروید، فضای حالت میتواند شامل تمام مختصات (x,y) یا آدرسهای خیابان باشد.
- انتقالها (Transitions):
- حرکت مستقیم از یک حالت به حالت دیگر با یک اقدام.
- مثال: از NNNN به FNFN با بردن روباه و مرغ.
- مسیر (Path) مجموعهای از چند انتقال است (مثل NNNN → FFFN → NFNN → FFFF).
- هزینهها (Costs):
- انتقالها ممکن است هزینههای متفاوتی داشته باشند (مثل مسافت، زمان یا انرژی).
- در این معما، فرض کردیم همه انتقالها هزینه یکسانی دارند (مثلاً یک واحد).
- در مسائل واقعی، ممکن است بخواهیم هزینه را بر اساس زمان یا مسافت محاسبه کنیم.
چرا این روش مهم است؟
شاید بتوانید این معما را با حدس و آزمایش حل کنید، اما برای مسائل پیچیدهتر (مثلاً با صدها یا میلیونها حالت)، رویکرد سیستماتیک ما بسیار کارآمد است. با تعریف فضای حالت و انتقالها، میتوانیم حل مسئله را به یک برنامه کامپیوتری واگذار کنیم تا مسیر بهینه را پیدا کند.
جمعبندی
معمای عبور مرغ یک مثال ساده اما قدرتمند برای یادگیری حل مسئله به روش سیستماتیک است. ما:
- تمام حالتهای ممکن را شناسایی کردیم.
- حالتهای ممنوعه را حذف کردیم.
- انتقالهای مجاز را مشخص کردیم.
- مسیری از حالت اولیه (NNNN) به حالت هدف (FFFF) پیدا کردیم.
این روش نهتنها برای این معما، بلکه برای مسائل پیچیدهتر در برنامهریزی، هوش مصنوعی و بهینهسازی نیز قابل استفاده است. اگر علاقهمندید، میتوانید نسخه سختتر معما (که قایق فقط یک شیء را حمل میکند) را به عنوان تمرین امتحان کنید!
این فرآیند، پایهی بسیاری از سامانههای هوشمند مدرن مانند خودروهای خودران، دستیارهای دیجیتال، و رباتهای صنعتی است.
در واقع، هوش مصنوعی با اتکا به چنین رویکردهایی، میتواند در مواجهه با مسائل پیچیده، راهکارهای مؤثر و سریع ارائه دهد.
پرسشهای متداول (FAQ)
۱. آیا همه مسائل هوش مصنوعی بهصورت مسئله جستجو مدلپذیر هستند؟
خیر، اما بسیاری از مسائل، خصوصاً آنهایی که شامل تصمیمگیری مرحلهای هستند، میتوانند بهصورت یک فضای وضعیت و مسئله جستجو مدل شوند.
۲. تفاوت بین برنامهریزی (Planning) و جستجو در چیست؟
جستجو به دنبال یافتن مسیر در یک فضای وضعیت است، درحالیکه برنامهریزی شامل انتخاب دنبالهای از اقدامات با در نظر گرفتن محدودیتها و منابع است.
۳. در چه مواردی از الگوریتمهای جستجو مانند A* یا BFS استفاده میشود؟
در مسائلی مثل مسیریابی، حل پازلها، و برنامهریزی برای عاملهای هوشمند، این الگوریتمها کاربرد دارند.
۴. چگونه میتوان مسائل پیچیدهتر را با این روش حل کرد؟
با تعریف دقیقتر وضعیتها، ایجاد مدل انتزاعی از محیط، و استفاده از الگوریتمهای پیشرفتهتر مانند جستجوی آگاهانه، میتوان مسائل پیچیده را حل کرد.
۵. آیا این روشها در رباتهای واقعی هم بهکار میروند؟
بله، بسیاری از رباتهای خودران، هواپیماهای بدون سرنشین، و حتی سامانههای توصیهگر از همین مفاهیم در سطحی انتزاعی استفاده میکنند.
فصل دوم: حل مسئله با استفاده از هوش مصنوعی
میانپردهای تاریخی: شروع از مفهوم جستوجو
۱. آغاز اندیشههای هوش مصنوعی
- پیش از رایانهها نیز انسانها به ایده تفکر و استدلال خودکار اندیشیدهاند.
- آلن تورینگ یکی از نخستین متفکرانی بود که درباره هوش مصنوعی فکر کرد. او با معرفی ماشین تورینگ، نشان داد که هر چیزی که قابل محاسبه باشد، میتواند خودکارسازی شود.
- این نظریه اساس رایانههای برنامهپذیر را ایجاد کرد؛ یعنی بهجای ساخت دستگاه خاص برای هر وظیفه، میتوان یک رایانه عمومی ساخت که بسته به برنامه، وظایف مختلفی انجام دهد.
۲. کاربرد عملی در جنگ جهانی دوم
- تورینگ در طراحی رایانههای ابتدایی که برای شکستن رمزنگاری آلمانها استفاده میشدند نقش داشت.
- این تلاشها زمینهساز توسعه واقعی رایانههای برنامهپذیر شد.
۳. ابداع واژه «هوش مصنوعی»
- جان مککارتی (۱۹۲۷-۲۰۱۱) که اغلب بهعنوان پدر هوش مصنوعی شناخته میشود، واژه «Artificial Intelligence» را در کنفرانس دارتموث (۱۹۵۶) معرفی کرد.
- بیانیه مهم او در این کنفرانس: “هر جنبهای از یادگیری یا هر ویژگی دیگری از هوش را میتوان آنقدر دقیق توصیف کرد که بتوان آن را در قالب برنامهای برای ماشین پیادهسازی نمود.”
- این گزاره هنوز هم بهعنوان «حدس» باقی مانده، اما زیربنای تفکر درباره هوش مصنوعی است.
۴. چرا بازیها و جستوجو در مرکز تحقیقات هوش مصنوعی قرار گرفتند؟
- با پیشرفت سختافزارها در دهه ۵۰ میلادی، امکان اجرای الگوریتمهای واقعی هوش مصنوعی فراهم شد.
- بازیها مثل شطرنج، چکرز و اخیراً گو، حوزههای مناسبی برای آزمایش الگوریتمها بودند زیرا:
- محیطی محدود و فرمالیزهشده داشتند.
- هدفمحور بودند و نتایج واضح داشتند.
- الگوریتمهای جستوجو مثل مینیمکس و هرس آلفا-بتا در دهه ۶۰ توسعه یافتند و هنوز پایهای برای سیستمهای بازی هستند.


هوش مصنوعی و بازیها: نگاهی عمیق به الگوریتم مینیماکس و کاربردهای آن
در دنیای هوش مصنوعی، حل مسائل پیچیده مانند بازیهای استراتژیک، یکی از جذابترین حوزههای تحقیقاتی است. بازیهای دو نفره با اطلاعات کامل، مانند شطرنج و دوز (تیکتکتو)، نمونههای کلاسیکی هستند که هوش مصنوعی را به چالش میکشند. این مقاله که برای مجله «هوش مصنوعی سیمرغ» تهیه شده است، به بررسی چگونگی استفاده از هوش مصنوعی در حل بازیها با تمرکز بر الگوریتم مینیماکس میپردازد. با ما همراه شوید تا ببینیم چگونه این الگوریتم، تصمیمگیری استراتژیک را در بازیهای رقابتی شبیهسازی میکند.
درخت بازی: قلب تحلیل استراتژیک در هوش مصنوعی
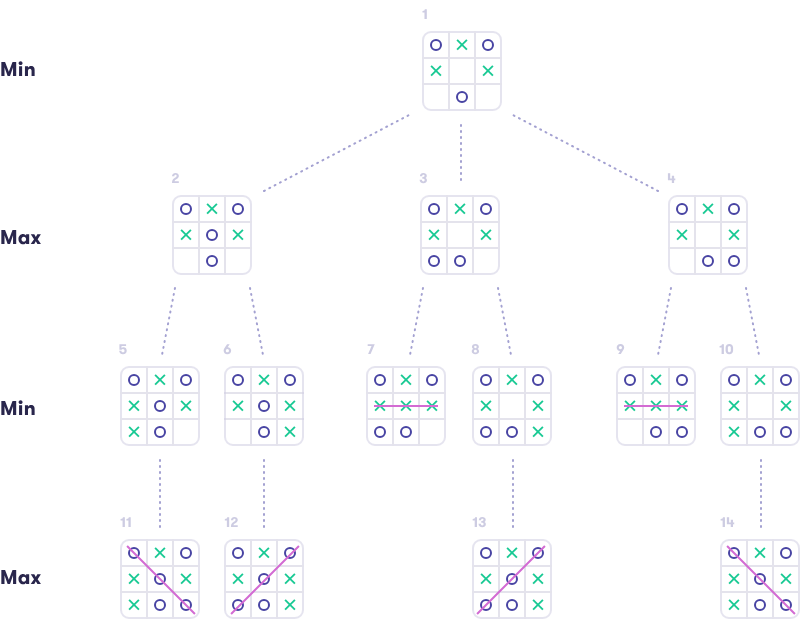
مفهوم درخت بازی
در هوش مصنوعی، بازیهای دو نفره با اطلاعات کامل با استفاده از ساختاری به نام «درخت بازی» مدلسازی میشوند. در این ساختار، هر گره نشاندهنده یک حالت خاص از بازی است. گره ریشه، حالت اولیه بازی (مثلاً تخته خالی در دوز) را نشان میدهد. هر سطح از درخت به نوبت یکی از بازیکنان اختصاص دارد و گرههای فرزند، حالتهای ممکن پس از حرکت یک بازیکن را نشان میدهند. این ساختار تا رسیدن به حالتهای پایانی بازی، یعنی جایی که یکی از بازیکنان برنده میشود یا بازی مساوی تمام میشود، ادامه مییابد.
کاربرد درخت بازی در دوز
برای مثال، در بازی دوز، هر گره در درخت بازی نشاندهنده یک تخته با ترکیب خاصی از علامتهای X و O است. فرض کنید بازیکن اول (Max) با X و بازیکن دوم (Min) با O بازی میکند. هر سطح از درخت به نوبت یکی از این بازیکنان اختصاص دارد و گرههای فرزند، نتایج ممکن از حرکتهای آنها را نشان میدهند. جدول زیر نمونهای از یک درخت بازی ساده را نشان میدهد:
| گره | حالت تخته | بازیکن | ارزش (Value) |
|---|---|---|---|
| ۱ | تخته با ۳ خانه خالی | Min | -۱ |
| ۲ | تخته پس از حرکت Min | Max | -۱ |
| ۳ | تخته پس از حرکت Max | Min | +۱ |
این جدول نشان میدهد که چگونه ارزش هر گره بر اساس نتیجه نهایی بازی تعیین میشود.
الگوریتم مینیماکس: استراتژی بهینه در بازیها
مفهوم مینیماکس
الگوریتم مینیماکس یکی از روشهای کلاسیک در هوش مصنوعی برای یافتن حرکت بهینه در بازیهای دو نفره با اطلاعات کامل و مجموع صفر است. در این بازیها، برد یک بازیکن به معنای باخت بازیکن دیگر است. هدف بازیکن Max (مثلاً بازیکن X) بیشینه کردن ارزش نتیجه بازی و هدف بازیکن Min (بازیکن O) کمینه کردن آن است.
چگونه مینیماکس کار میکند؟
الگوریتم مینیماکس با بررسی تمام حالتهای ممکن در درخت بازی کار میکند:
- ارزشگذاری گرههای پایانی: به گرههایی که بازی در آنها به پایان میرسد (مانند برد X، برد O یا تساوی) ارزشهای +۱، -۱ یا ۰ اختصاص داده میشود.
- انتخاب بهینه در گرههای داخلی: در گرههای Max، الگوریتم گره فرزندی را انتخاب میکند که بیشترین ارزش را دارد. در گرههای Min، گره با کمترین ارزش انتخاب میشود.
- بازگشت به ریشه: این فرآیند از گرههای پایانی به سمت ریشه ادامه مییابد تا ارزش ریشه و حرکت بهینه مشخص شود.
مثال عملی
فرض کنید در بازی دوز، تخته به حالتی رسیده که Min (بازیکن O) باید حرکت کند و سه خانه خالی وجود دارد. درخت بازی نشان میدهد که اگر Min در خانه وسط O بگذارد، میتواند برد خود را تضمین کند. مینیماکس این حرکت را بهعنوان بهینهترین انتخاب شناسایی میکند.

چالشهای درختهای بزرگ و راهحلهای هوشمند
مشکل درختهای بزرگ
در بازیهای پیچیدهتر مانند شطرنج یا گو، درخت بازی بسیار بزرگ است. برای مثال، در شطرنج، میانگین تعداد حرکتهای ممکن در هر گره (فاکتور انشعاب) حدود ۳۵ است. بررسی تمام حالتها تا عمق ۱۰ حرکت، نیازمند ارزیابی بیش از ۲.۷ کادریلیون گره است! این حجم محاسباتی برای الگوریتم مینیماکس ساده غیرممکن است.
راهحل: تابع ارزیابی هوریستیک
برای مدیریت درختهای بزرگ، از تابعهای ارزیابی هوریستیک استفاده میشود. این توابع ارزش تقریبی یک حالت بازی را بدون نیاز به بررسی تمام گرههای پایانی تخمین میزنند. برای مثال، در شطرنج، تابع هوریستیک ممکن است ارزش مهرهها را بر اساس نوع آنها (وزیر = 9، رخ = 5، اسب = 3) و موقعیت استراتژیک آنها (مانند کنترل مرکز تخته) محاسبه کند.
مینیماکس با عمق محدود
در نسخهای از مینیماکس که با عمق محدود کار میکند، الگوریتم تنها تا عمق مشخصی از درخت را بررسی کرده و سپس تابع هوریستیک را برای تخمین ارزش گرهها به کار میبرد. این روش در موفقیتهایی مانند پیروزی دیپ بلو بر گری کاسپاروف در سال ۱۹۹۷ نقش کلیدی داشت.
محدودیتها و گامهای بعدی
محدودیتهای جستوجوی ساده
اگرچه مینیماکس در بازیهای ساده مانند دوز عملکردی عالی دارد، در مسائل دنیای واقعی که تعداد حالتها بسیار زیاد است یا نتایج حرکات غیرقطعی هستند، کارایی محدودی دارد. برای مثال، بازیهایی مانند پوکر که اطلاعات مخفی دارند یا بازیهایی مانند تختهنرد که به شانس وابستهاند، به رویکردهای پیچیدهتری نیاز دارند.
گام بعدی: احتمال و عدم قطعیت
برای حل مسائل پیچیدهتر، باید مفاهیم احتمال و عدم قطعیت را به الگوریتمها اضافه کنیم. این موضوع در حوزههای پیشرفتهتر هوش مصنوعی، مانند یادگیری تقویتی و مدلهای احتمالی، بررسی میشود.
جمعبندی
الگوریتم مینیماکس و مفهوم درخت بازی، ابزارهای قدرتمندی برای حل مسائل بازیهای استراتژیک در هوش مصنوعی هستند. این الگوریتم با شبیهسازی تصمیمگیری استراتژیک، حرکتهای بهینه را در بازیهای دو نفره با اطلاعات کامل پیدا میکند. با این حال، در بازیهای پیچیدهتر، استفاده از توابع هوریستیک و روشهای پیشرفتهتر ضروری است. درک این مفاهیم، گام مهمی در یادگیری هوش مصنوعی و کاربردهای آن در دنیای واقعی است.
پرسشهای متداول
- درخت بازی چیست و چرا در هوش مصنوعی مهم است؟
درخت بازی ساختاری است که تمام حالتهای ممکن یک بازی را نشان میدهد. این ساختار به هوش مصنوعی کمک میکند تا با بررسی حرکتهای ممکن، استراتژی بهینه را پیدا کند. - الگوریتم مینیماکس چه نوع بازیهایی را میتواند حل کند؟
مینیماکس برای بازیهای دو نفره با اطلاعات کامل و مجموع صفر (مانند شطرنج و دوز) مناسب است، اما در بازیهایی با اطلاعات مخفی یا شانس، نیاز به اصلاح دارد. - چرا در بازیهای پیچیده مانند شطرنج نمیتوان تمام درخت بازی را بررسی کرد؟
به دلیل فاکتور انشعاب بالا (تعداد زیاد حرکتهای ممکن در هر حالت)، درخت بازی بسیار بزرگ میشود و بررسی کامل آن غیرممکن است. - تابع هوریستیک چه نقشی در مینیماکس دارد؟
تابع هوریستیک ارزش تقریبی حالتهای غیرپایانی را تخمین میزند و به الگوریتم اجازه میدهد بدون بررسی کل درخت، تصمیمگیری کند. - آیا مینیماکس در مسائل دنیای واقعی کاربرد دارد؟
مینیماکس در مسائل با حالتهای محدود و قطعی کاربرد دارد، اما برای مسائل پیچیدهتر، نیاز به ترکیب با روشهای دیگر مانند یادگیری ماشین است
هوش مصنوعی در دنیای واقعی: قدرت مدیریت عدم قطعیت
هوش مصنوعی مدرن به دلیل تواناییاش در مدیریت عدم قطعیت، گامهای بلندی در حل مسائل دنیای واقعی برداشته است. برخلاف روشهای قدیمیتر دهههای ۱۹۶۰ تا ۱۹۸۰ که عمدتاً بر مسائل ساده و قطعی تمرکز داشتند، تکنیکهای امروزی با استفاده از احتمال و مدلهای آماری، میتوانند پیچیدگیهای دنیای واقعی را بهتر مدیریت کنند. این مقاله، که برای مجله «هوش مصنوعی سیمرغ» تهیه شده است، به بررسی مفاهیم کلیدی احتمال، قانون بیز، و طبقهبندی بیز ساده میپردازد. با ما همراه شوید تا ببینیم چگونه این ابزارها هوش مصنوعی را به دنیای واقعی متصل میکنند.
مفاهیم پایه: شانس و احتمال
احتمال چیست؟
احتمال، ابزاری ریاضی برای سنجش عدم قطعیت است. در هوش مصنوعی، احتمال به ما کمک میکند تا پیشبینیهای دقیقتری در شرایطی که اطلاعات کامل نیست، انجام دهیم. برای مثال، در تشخیص پزشکی، احتمال میتواند نشان دهد که با مشاهده علائم خاص، چقدر احتمال دارد بیمار به بیماری خاصی مبتلا باشد.
شانس در مقابل احتمال
شانس (Odds) نسبت احتمال وقوع یک رویداد به عدم وقوع آن است. برای مثال، اگر احتمال باران ۰.۸ باشد، شانس باران ۰.۸ به ۰.۲ یا ۴ به ۱ است. جدول زیر تفاوت این دو مفهوم را نشان میدهد:
| مفهوم | تعریف | مثال (باران) |
|---|---|---|
| احتمال | نسبت رویدادهای مطلوب به کل رویدادها | ۰.۸ (۸۰%) |
| شانس | نسبت احتمال وقوع به عدم وقوع | ۴:۱ |
کاربرد در هوش مصنوعی
در مسائل دنیای واقعی، مانند پیشبینی آبوهوا یا تشخیص هرزنامه (اسپم)، احتمال به هوش مصنوعی کمک میکند تا با دادههای ناقص یا نویزدار کار کند. این پایهای برای الگوریتمهای پیشرفتهتر مانند یادگیری ماشین است.
احتمال و شانس: کلید مدیریت عدم قطعیت در هوش مصنوعی
در دنیای واقعی، برخلاف بازیهای سادهای مانند شطرنج که اطلاعات کامل در دسترس است، عدم قطعیت بخش جداییناپذیر مسائل است. از خودروهای خودران که با دادههای ناقص حسگرها کار میکنند تا پیشبینی آبوهوا، هوش مصنوعی مدرن با استفاده از مفاهیم احتمال و شانس، این عدم قطعیتها را مدیریت میکند. این مقاله، که برای مجله «هوش مصنوعی سیمرغ» نوشته شده است، به بررسی نقش احتمال و شانس در هوش مصنوعی و کاربرد آنها در مسائل دنیای واقعی میپردازد. با ما همراه شوید تا ببینیم چگونه این ابزارها به هوش مصنوعی کمک میکنند تا با پیچیدگیهای دنیای واقعی کنار بیاید.
احتمال: پایهای برای استدلال در عدم قطعیت
احتمال چیست؟
احتمال، ابزاری ریاضی است که میزان وقوع یک رویداد را در شرایط عدم قطعیت اندازهگیری میکند. در هوش مصنوعی، احتمال به سیستمها امکان میدهد تا با دادههای ناقص یا پرنویز (دارای خطا) تصمیمگیری کنند. برای مثال، در یک خودروی خودران، حسگرها ممکن است دادههای متناقضی ارائه دهند (یکی نشاندهنده انحراف مسیر به چپ و دیگری به راست). احتمال به خودرو کمک میکند تا با وزندهی به این دادهها، تصمیم درستی بگیرد.
چرا احتمال مهم است؟
برخلاف روشهای قدیمیتر هوش مصنوعی در دهههای ۱۹۶۰ تا ۱۹۸۰ که بر اطلاعات قطعی متکی بودند، روشهای مدرن با استفاده از احتمال، توانایی مدیریت سناریوهای پیچیده را دارند. این ویژگی در کاربردهایی مانند تشخیص پزشکی، فیلتر هرزنامه، یا پیشبینی رفتار کاربران کلیدی است.
مثالهای روزمره
احتمال در زندگی روزمره نیز کاربرد دارد. جدول زیر چند نمونه را نشان میدهد:
| سناریو | احتمال تقریبی | توضیح |
|---|---|---|
| بارش باران امروز | ۸۰% | پیشبینی آبوهوا |
| برد در لاتاری | ۰.۰۰۰۱% | بسیار بعید |
| تصادف با سرعت غیرمجاز | ۵% | ریسک رانندگی |
این جدول نشان میدهد که چگونه احتمال، ریسکها و فرصتها را در زندگی روزمره کمیسازی میکند.
شانس: نمایشی ساده برای عدم قطعیت
شانس چیست؟
شانس (Odds) نسبت احتمال وقوع یک رویداد به عدم وقوع آن است. برای مثال، شانس ۳:۱ به این معناست که به ازای هر سه مورد وقوع یک رویداد (مثلاً باران)، یک مورد عدم وقوع (آفتابی) وجود دارد. این مفهوم در هوش مصنوعی برای بهروزرسانی باورها با اطلاعات جدید بسیار مفید است.
تفاوت شانس و احتمال
احتمال، کسری از کل رویدادهای ممکن است (مثلاً ۰.۷۵ یا ۷۵%)، اما شانس به صورت نسبت بیان میشود (مثلاً ۳:۱). برای تبدیل شانس به احتمال، از فرمول زیر استفاده میشود:
P = x / (x + y)
که در آن x و y اعداد شانس هستند (مثلاً برای ۳:۱، احتمال = 3 / (۳ + ۱) = 0.۷۵).
چرا شانس بهتر است؟
استفاده از شانس و فرکانسهای طبیعی (مانند «۳ روز بارانی از ۴ روز») در مقایسه با درصد یا کسر، برای انسانها قابلفهمتر است و خطای محاسباتی را کاهش میدهد. برای مثال، شانس ۱:۵ (یک برد در مقابل پنج باخت) به معنای نیاز به ۶ بازی برای یک برد بهطور متوسط است، در حالی که احتمال ۲۰% به معنای نیاز به ۵ بازی برای یک برد است.
مثال کاربردی
فرض کنید شانس باران در هلسینکی ۲۰۶:۱۵۹ باشد. احتمال باران برابر است با:
۲۰۶ / (۲۰۶ + ۱۵۹) = 206 / ۳۶۵ ≈ ۰.۵۶۴ یا ۵۶.۴%.
اهمیت کمیسازی عدم قطعیت
چرا کمیسازی مهم است؟
کمیسازی عدم قطعیت به ما امکان میدهد تا درباره ریسکها و فرصتها بهصورت منطقی بحث کنیم. برای مثال، در تصمیمگیری درباره واکسنها، احتمال عوارض جانبی در مقابل مزایای آنها سنجیده میشود. بدون کمیسازی، ممکن است ترس از ناشناختهها مانع تصمیمگیری منطقی شود.
کاربرد در هوش مصنوعی
در هوش مصنوعی، کمیسازی عدم قطعیت در کاربردهایی مانند تشخیص پزشکی (تعیین احتمال بیماری بر اساس علائم) یا تشخیص هرزنامه (شناسایی ایمیلهای مشکوک) حیاتی است. این رویکرد به سیستمها امکان میدهد تا با دادههای ناقص، تصمیمات بهینه بگیرند.
مثال: پیشبینی آبوهوا
فرض کنید پیشبینی آبوهوا احتمال ۹۰% برای باران را اعلام کند، اما روز آفتابی باشد. آیا این پیشبینی اشتباه است؟ خیر، زیرا احتمال قطعیت نیست و یک مشاهده نمیتواند درستی آن را تأیید یا رد کند. اما اگر در طولانیمدت، باران تنها در ۶۰% روزهای با پیشبینی ۸۰% رخ دهد، میتوان گفت پیشبینی نادرست بوده است.
تمرین: تبدیل شانس به احتمال
برای درک بهتر، بیایید چند شانس را به احتمال تبدیل کنیم:
- شانس ۱:۴۶ برای سهتایی در پوکر
احتمال = 1 / (۱ + ۴۶) = 1/۴۷ ≈ ۰.۰۲۱۳ یا ۲/۴۷ (بهصورت کسر). - شانس ۲۰۶:۱۵۹ برای باران در هلسینکی
احتمال = 206 / (۲۰۶ + ۱۵۹) = 206/۳۶۵ ≈ ۰.۵۶۴ یا ۵۶/۴% (بهصورت درصد). - شانس ۲۳:۳۴۲ برای باران در سندیگو
احتمال = 23 / (۲۳ + ۳۴۲) = 23/۳۶۵ ≈ ۰.۰۶۳ یا ۶/۳% (بهصورت درصد).
این تمرینها نشان میدهند که چگونه شانس بهعنوان ابزاری ساده، درک احتمال را آسانتر میکند.
جمعبندی
احتمال و شانس ابزارهای کلیدی در هوش مصنوعی مدرن هستند که امکان مدیریت عدم قطعیت را فراهم میکنند. از خودروهای خودران که با دادههای پرنویز حسگرها کار میکنند تا تشخیص پزشکی و پیشبینی آبوهوا، این مفاهیم به هوش مصنوعی کمک میکنند تا تصمیمات منطقی در دنیای پیچیده واقعی بگیرد. درک این ابزارها، گام مهمی برای فهم چگونگی عملکرد هوش مصنوعی در کاربردهای روزمره است.
پرسشهای متداول
- چرا احتمال در هوش مصنوعی مهم است؟
احتمال به هوش مصنوعی کمک میکند تا با دادههای ناقص یا پرنویز، مانند خروجی حسگرها، تصمیمگیری کند. - تفاوت شانس و احتمال چیست؟
احتمال کسری از رویدادهای مطلوب به کل است، در حالی که شانس نسبت وقوع به عدم وقوع یک رویداد است. - چرا شانس در هوش مصنوعی استفاده میشود؟
شانس بهروزرسانی باورها با اطلاعات جدید را آسانتر میکند و برای انسانها قابلفهمتر است. - آیا یک پیشبینی احتمالی اشتباه با یک مشاهده رد میشود؟
خیر، درستی پیشبینیهای احتمالی نیاز به بررسی طولانیمدت و دادههای متعدد دارد. - کمیسازی عدم قطعیت چه اهمیتی دارد؟
کمیسازی امکان بحث منطقی درباره ریسکها و فرصتها را فراهم میکند و از تصمیمگیریهای غیرمنطقی جلوگیری میکند
قانون بیز: فرمولی ساده با تأثیری عمیق
قانون بیز چیست؟
قانون بیز روشی برای بهروزرسانی باورها با استفاده از اطلاعات جدید است. در سادهترین شکل خود، این قانون با استفاده از شانس (Odds) بیان میشود:
شانس پسین = نسبت احتمال (Likelihood Ratio) × شانس پیشین
- شانس پیشین (Prior Odds): نسبت احتمال وقوع یک رویداد به عدم وقوع آن، قبل از دریافت اطلاعات جدید.
- نسبت احتمال: نسبت احتمال مشاهده شواهد در صورت وقوع رویداد به احتمال مشاهده همان شواهد در صورت عدم وقوع رویداد.
- شانس پسین (Posterior Odds): شانس بهروزرسانیشده پس از دریافت اطلاعات جدید.
مثال ساده: پیشبینی باران
فرض کنید در هلسینکی، شانس باران ۲۰۶:۱۵۹ است (بر اساس ۲۰۶ روز بارانی و ۱۵۹ روز غیربارانی در سال). اگر صبح ابری باشد، احتمال ابر در روزهای بارانی ۹/۱۰ و در روزهای غیربارانی ۱/۱۰ است. نسبت احتمال برابر است با:
(۹/۱۰) / (۱/۱۰) = 9
با استفاده از قانون بیز:
شانس پسین = 9 × (۲۰۶:۱۵۹) = 1854:۱۵۹
این محاسبه نشان میدهد که با مشاهده آسمان ابری، شانس باران بهطور قابلتوجهی افزایش مییابد.
جدول محاسبات
| پارامتر | مقدار | توضیح |
|---|---|---|
| شانس پیشین | ۲۰۶:۱۵۹ | شانس باران قبل از مشاهده ابر |
| نسبت احتمال | ۹ | نسبت احتمال ابر در روزهای بارانی به غیربارانی |
| شانس پسین | ۱۸۵۴:۱۵۹ | شانس باران پس از مشاهده ابر |
کاربرد قانون بیز: تشخیص پزشکی

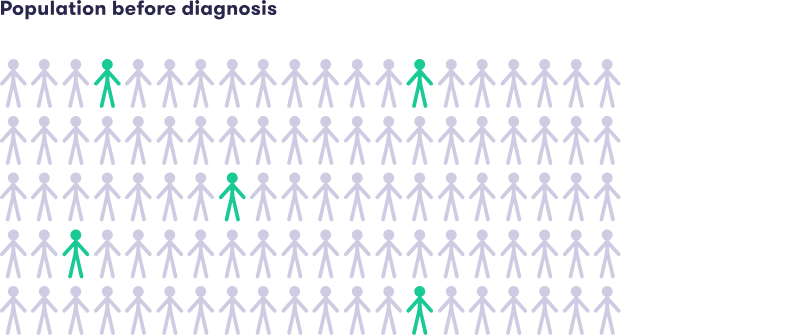
مثال: غربالگری سرطان پستان
یکی از کاربردهای کلاسیک قانون بیز، در تشخیص پزشکی است. فرض کنید ۵ نفر از هر ۱۰۰ زن به سرطان پستان مبتلا هستند (احتمال پیشین = 5/۱۰۰). تست ماموگرافی در ۸۰% موارد سرطان را درست تشخیص میدهد (حساسیت = 80%)، اما در ۱۰% موارد برای افراد سالم نتیجه مثبت کاذب میدهد (ویژگی = 90%).
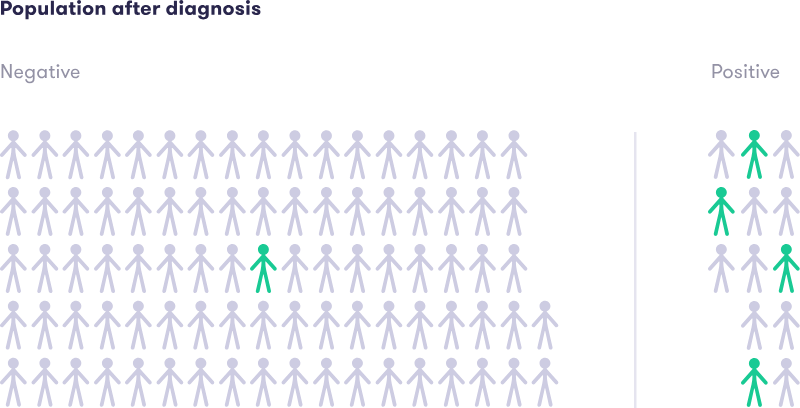
محاسبه شانس پیشین
شانس پیشین سرطان = 5:۹۵ (۵ مبتلا به سرطان در مقابل ۹۵ غیرمبتلا).
محاسبه نسبت احتمال
- احتمال نتیجه مثبت در صورت ابتلا (حساسیت): ۸۰/۱۰۰ = 0.۸
- احتمال نتیجه مثبت در صورت عدم ابتلا (مثبت کاذب): ۱۰/۱۰۰ = 0.۱
نسبت احتمال = 0.۸ / ۰.۱ = 8
محاسبه شانس پسین
شانس پسین = 8 × (۵:۹۵) = 40:۹۵
این نتیجه نشان میدهد که حتی با نتیجه مثبت تست، احتمال ابتلا به سرطان همچنان کمتر از ۵۰% است، که نشاندهنده خطای رایج «غفلت از نرخ پایه» (Base-Rate Fallacy) در قضاوتهای شهودی است.
جدول خلاصه
| پارامتر | مقدار | توضیح |
|---|---|---|
| شانس پیشین | ۵:۹۵ | شانس ابتلا به سرطان قبل از تست |
| نسبت احتمال | ۸ | نسبت نتیجه مثبت در مبتلا به غیرمبتلا |
| شانس پسین | ۴۰:۹۵ | شانس ابتلا پس از نتیجه مثبت |
چرا قانون بیز مهم است؟
مدیریت شواهد متناقض
قانون بیز به هوش مصنوعی امکان میدهد تا شواهد متناقض (مانند دادههای نویزدار حسگرها در خودروهای خودران) را ترکیب کرده و تصمیمات منطقی بگیرد. این ویژگی در کاربردهایی مانند تشخیص هرزنامه، پیشبینی بازار، و حتی قضاوت در دادگاهها حیاتی است.
اجتناب از خطاهای شهودی
بدون قانون بیز، افراد اغلب به دلیل غفلت از نرخ پایه، قضاوتهای نادرستی میکنند. برای مثال، در غربالگری سرطان، ممکن است به اشتباه فرض کنند که نتیجه مثبت تست به معنای احتمال بالای ابتلا است، در حالی که شانس واقعی بسیار کمتر است.
تمرینهای قانون بیز
تمرین ۱: پیشبینی باران در هلسینکی
با شانس پیشین ۲۰۶:۱۵۹ و نسبت احتمال ۹، شانس پسین باران پس از مشاهده ابر برابر است با:
۱۸۵۴:۱۵۹
تمرین ۲: غربالگری سرطان پستان
با شانس پیشین ۵:۹۵ و نسبت احتمال ۸، شانس پسین ابتلا به سرطان پس از نتیجه مثبت تست برابر است با:
۴۰:۹۵
این تمرینها نشان میدهند که چگونه قانون بیز، با یک ضرب ساده، اطلاعات جدید را به باورهای قبلی اضافه میکند.
جمعبندی
قانون بیز ابزاری ساده اما قدرتمند است که به هوش مصنوعی امکان میدهد تا با ترکیب شواهد متناقض، تصمیمات دقیقتری بگیرد. این قانون در حوزههایی مانند تشخیص پزشکی، پیشبینی آبوهوا، و تحلیل دادهها نقش کلیدی دارد. با درک قانون بیز، میتوانیم نهتنها در هوش مصنوعی، بلکه در زندگی روزمره نیز از قضاوتهای شهودی نادرست اجتناب کنیم و تصمیمات منطقیتری بگیریم.
پرسشهای متداول
- قانون بیز چیست و چرا مهم است؟
قانون بیز روشی برای بهروزرسانی باورها با اطلاعات جدید است و در مدیریت عدم قطعیت در هوش مصنوعی کاربرد دارد. - نسبت احتمال چیست؟
نسبت احتمال، نسبت احتمال مشاهده یک شواهد در صورت وقوع رویداد به احتمال آن در صورت عدم وقوع است. - چرا افراد در قضاوتهای احتمالی اشتباه میکنند؟
به دلیل غفلت از نرخ پایه، افراد اغلب احتمال وقوع یک رویداد را بیش از حد تخمین میزنند. - قانون بیز در چه حوزههایی کاربرد دارد؟
این قانون در پزشکی، حقوق، علوم داده، و حتی پیشبینیهای روزمره مانند آبوهوا استفاده میشود. - آیا قانون بیز پیچیده است؟
خیر، در شکل شانس، قانون بیز تنها یک ضرب ساده است، اما نتایج آن بسیار قدرتمند هستند
طبقهبندی بیزساده: ابزاری کارآمد برای هوش مصنوعی در دنیای واقعی
مقدمه
طبقهبندی بیز ساده یکی از کاربردیترین ابزارهای هوش مصنوعی است که با استفاده از قانون بیز، امکان دستهبندی دادهها را فراهم میکند. این روش، با وجود سادگی، در مسائل واقعی مانند فیلتر هرزنامه یا تحلیل متون، عملکردی چشمگیر دارد. این مقاله، که برای مجله «هوش مصنوعی سیمرغ» نوشته شده است، به بررسی مفهوم طبقهبندی بیزساده، نحوه کارکرد آن، و کاربردش در فیلترهای هرزنامه میپردازد. با ما همراه شوید تا ببینیم چگونه این روش ساده، مسائل پیچیده دنیای واقعی را حل میکند.
طبقهبندیکننده بیز ساده: اصول و بنیادی
طبقهبندیکننده بیز ساده چیست؟
طبقهبندیکننده بیز ساده (Naive Bayes Classifier) یک الگوریتم یادگیری ماشین است که از قانون بیز برای دستهبندی دادهها به کلاسهای مختلف (مانند هرزنامه یا غیرهرزنامه) استفاده میکند. این روش فرض میکند که ویژگیهای داده (مانند کلمات در یک متن) بهصورت شرطی مستقل از یکدیگر هستند. این فرض، هرچند سادهانگارانه است، اما در بسیاری از موارد نتایج قابلاعتمادی تولید میکند.
چرا ساده؟
فرض استقلال ویژگیها (مانند عدم وابستگی کلمات در یک ایمیل) باعث میشود این روش «ساده» نامیده شود. این فرض، پیچیدگیهای واقعی مانند ترتیب کلمات را نادیده میگیرد، اما به دلیل سرعت و کارایی بالا، همچنان بسیار محبوب است.
کاربردهای واقعی
یکی از شناختهشدهترین کاربردهای بیزساده، فیلترهای هرزنامه است. این فیلترها ایمیلها را به دو دسته «هرزنامه» (Spam) و «غیرهرزنامه» (Ham) تقسیم میکنند. ویژگیهای مورد بررسی معمولاً کلمات موجود در ایمیل هستند، و الگوریتم با تحلیل دادههای آموزشی، احتمال تعلق هر ایمیل به یک کلاس را محاسبه میکند.
جدول ویژگیها
جدول زیر نمونهای از دادههای آموزشی برای فیلتر هرزنامه را نشان میدهد:
| کلمه | تعداد در هرزنامه | تعداد در غیرهرزنامه | نسبت احتمال (Likelihood Ratio) |
|---|---|---|---|
| میلیون | ۱۵۶ | ۹۸ | ۵.۱ |
| دلار | ۲۹ | ۱۱۹ | ۰.۸ |
| کلیک تبلیغ | ۵۱ | ۰ | ۵۳.۲ |
| کنفرانس | ۰ | ۱۲ | ۰.۳ |
| کل کلمات | ۹۵۷۹۱ | ۳۰۶۴۳۸ | – |
نحوه کار طبقهبندیکننده بیز ساده
مراحل الگوریتم
- تعیین شانس پیشین: شانس اولیه برای هر کلاس (مثلاً ۱:۱ برای هرزنامه در مقابل غیرهرزنامه) مشخص میشود.
- محاسبه نسبتهای احتمال: برای هر ویژگی (مثلاً کلمه)، احتمال وقوع آن در هر کلاس محاسبه شده و نسبت احتمال به دست میآید.
- بهروزرسانی شانسها: با استفاده از قانون بیز، شانس پیشین با نسبتهای احتمال هر ویژگی ضرب میشود تا شانس پسین به دست آید.
- تصمیمگیری: کلاسی با بالاترین شانس پسین انتخاب میشود.
مشکل صفرها
اگر یک کلمه (مثلاً «کلیک تبلیغ») در غیرهرزنامهها صفر بار ظاهر شود، احتمال صفر میتواند محاسبات را مختل کند. برای حل این مشکل، از یک مقدار حداقل (مثلاً ۱/۱۰۰۰۰۰) بهعنوان احتمال پیشفرض استفاده میشود.
مثال: فیلتر هرزنامه با یک کلمه
فرض کنید ایمیلی تنها شامل کلمه «میلیون» است. با شانس پیشین ۱:۱ و نسبت احتمال ۵.۱ (از جدول بالا):
شانس پسین = 5.۱ × ۱:۱ = 5.۱:۱ ≈ ۵.۱
این نتیجه نشان میدهد که ایمیل به احتمال زیاد هرزنامه است.
مثال پیشرفته: فیلتر هرزنامه با چند کلمه
سناریو
ایمیلی با کلمات «میلیون»، «دلار»، «کلیک تبلیغ»، و «کنفرانس» را در نظر بگیرید. با استفاده از شانس پیشین ۱:۱ و نسبتهای احتمال جدول بالا:
- کلمه «میلیون»: نسبت احتمال = 5.۱
- کلمه «دلار»: نسبت احتمال = 0.۸
- کلمه «کلیک تبلیغ»: نسبت احتمال = 53.۲
- کلمه «کنفرانس»: نسبت احتمال = 0.۳
محاسبه شانس پسین
شانس پسین = 1 × ۵.۱ × ۰.۸ × ۵۳.۲ × ۰.۳ = 651.۱۶۸:۱
این نتیجه نشان میدهد که ایمیل به احتمال بسیار بالا هرزنامه است، زیرا شانس پسین بسیار بیشتر از ۱ است.
جدول محاسبات
| کلمه | نسبت احتمال | شانس پسین (انباشته) |
|---|---|---|
| میلیون | ۵.۱ | ۵.۱:۱ |
| دلار | ۰.۸ | ۴.۰۸:۱ |
| کلیک تبلیغ | ۵۳.۲ | ۲۱۷.۰۵۶:۱ |
| کنفرانس | ۰.۳ | ۶۵۱.۱۶۸:۱ |
چرا بیز ساده مؤثر است؟
مزایای بیز ساده عبارتند از:
- سرعت بالا: محاسبات ساده و سریع هستند، حتی با دادههای بزرگ.
- نیاز به داده کم: با دادههای آموزشی محدود نیز عملکرد خوبی دارد.
- کارایی در مسائل متنی: در تحلیل متن، مانند فیلتر هرزنامه یا تحلیل احساسات، بسیار موفق است.
محدودیتها
فرض استقلال ویژگیها گاهی غیرواقعی است. برای مثال، در یک ایمیل، کلمات «رایگان» و «تخفیف» ممکن است به هم وابسته باشند، که بیز ساده این وابستگی را نادیده میگیرد. با این حال، همانطور که جورج باکس، آماردان معروف، گفته است: «همه مدلها اشتباهاند، اما برخی مفیدند.»
جمعبندی
طبقهبندی بیزساده، با وجود سادگی، ابزاری قدرتمند برای حل مسائل دنیای واقعی مانند فیلتر هرزنامه است. این روش با استفاده از قانون بیز و فرض استقلال ویژگیها، امکان دستهبندی سریع و دقیق دادهها را فراهم میکند. درک این الگوریتم، گامی کلیدی در فهم چگونگی مدیریت عدم قطعیت در هوش مصنوعی است و کاربردهای آن در حوزههای مختلف، از تحلیل متن تا تشخیص پزشکی، همچنان در حال گسترش است.
پرسشهای متداول
- طبقهبندی بیز ساده چیست؟
بیز ساده یک الگوریتم یادگیری ماشین است که با استفاده از قانون بیز، دادهها را به کلاسهای مختلف (مانند هرزنامه یا غیرهرزنامه) دستهبندی میکند. - چرا این روش «ساده» نامیده میشود؟
به دلیل فرض استقلال شرطی ویژگیها، که پیچیدگیهای واقعی مانند وابستگی بین کلمات را نادیده میگیرد. - بیز ساده در چه کاربردهایی موفق است؟
این روش در تحلیل متون، مانند فیلتر هرزنامه، تحلیل احساسات، و تشخیص پزشکی، عملکرد خوبی دارد. - چگونه مشکل صفرها در بیز ساده حل میشود؟
با اختصاص یک مقدار حداقل (مانند ۱/۱۰۰۰۰۰) به احتمالهایی که صفر هستند، از خطاهای محاسباتی جلوگیری میشود. - آیا الگوریتم بیز ساده همیشه دقیق است؟
خیر، فرض استقلال ویژگیها ممکن است دقت را در برخی موارد کاهش دهد، اما این روش همچنان در بسیاری از کاربردها مفید است
منبع: elementsofai.com
برای مشاهده مقالات بیشتر همراه ما در بزرگترین و تخصصی ترین مجله هوش مصنوعی ایران بمانید.
فصل ۴: یادگیری ماشین(قلب تپنده هوش مصنوعی مدرن)
یادگیری ماشین (Machine Learning) یکی از ستونهای اصلی هوش مصنوعی است که به سیستمها امکان میدهد از دادهها یاد بگیرند و بدون برنامهریزی صریح، عملکرد خود را بهبود ببخشند. همانطور که انسانها با تجربه عاقلتر میشوند، ماشینها نیز با یادگیری از دادهها هوشمندتر میشوند. این مقاله، که برای مجله «هوش مصنوعی سیمرغ» نوشته شده است، به بررسی انواع یادگیری ماشین، طبقهبندیکننده نزدیکترین همسایه، و رگرسیون میپردازد. با ما همراه شوید تا ببینیم چگونه یادگیری ماشین، هوش مصنوعی را به دنیای واقعی متصل میکند.


این فصل بخشهای زیر را در بر میگیرد:
۱. انواع یادگیری ماشین
۲. طبقهبندیکننده نزدیکترین همسایه
۳. رگرسیون: پیشبینی مقادیر پیوسته
انواع یادگیری ماشین: سفری به دنیای هوش مصنوعی دادهمحور
یادگیری ماشین (Machine Learning) به سیستمها امکان داده تا از دادهها الگوهایی استخراج کنند و بدون نیاز به قوانین دستی، تصمیمگیری کنند. یکی از مثالهای کلاسیک در این حوزه، شناسایی ارقام دستنویس است که از مجموعه داده معروف MNIST استفاده میکند. این مقاله، که برای مجله «هوش مصنوعی سیمرغ» نوشته شده است، به بررسی انواع یادگیری ماشین و کاربردهای آنها با تمرکز بر مجموعه داده MNIST میپردازد. با ما همراه شوید تا ببینیم چگونه یادگیری ماشین، مسائل پیچیده دنیای واقعی را حل میکند.
مجموعه داده MNIST: دروازهای به یادگیری ماشین
MNIST چیست؟
مجموعه داده MNIST (Modified National Institute of Standards and Technology) شامل تصاویر سیاهوسفید ارقام دستنویس (۰ تا ۹) است که بهعنوان یکی از معروفترین مجموعههای داده در یادگیری ماشین شناخته میشود. هر تصویر با برچسب صحیح خود (رقمی که نویسنده قصد نوشتن آن را داشته) همراه است، اگرچه گاهی تشخیص برچسب صحیح دشوار است (مثلاً آیا یک تصویر واقعاً عدد ۷ است یا ۴؟).
چرا MNIST مهم است؟
این مجموعه داده به دلیل سادگی و در عین حال چالشبرانگیز بودن، بهعنوان یک معیار استاندارد برای آزمایش الگوریتمهای یادگیری ماشین استفاده میشود. هدف این است که الگوریتمی طراحی شود که بتواند بهصورت خودکار، برچسب صحیح (۰ تا ۹) را برای هر تصویر پیشبینی کند.
چالشهای روشهای سنتی
در گذشته، سیستمهای مبتنی بر قوانین دستی (مانند سیستمهای خبره دهه ۱۹۸۰) برای شناسایی ارقام استفاده میشدند. برای مثال، قوانینی مانند «اگر پیکسلهای سیاه یک حلقه تشکیل دهند، عدد ۰ است» یا «اگر پیکسلها یک خط عمودی باشند، عدد ۱ است» تعریف میشدند. اما این روشها به دلیل پیچیدگی تعریف قوانین دقیق و تنوع زیاد در دستخطها، ناکارآمد بودند.
جدول مشکلات روشهای سنتی
| روش | مشکل | مثال |
|---|---|---|
| قوانین دستی | نیاز به تعریف دقیق و پیچیده | «حلقه» یا «خط» دقیقاً چیست؟ |
| استثناها | نیاز به قوانین متعدد برای استثناها | دستخطهای نامنظم |
| مقیاسپذیری | دشواری در تعمیم به دادههای جدید | تنوع در سبکهای نوشتاری |
انواع یادگیری ماشین: سه رویکرد اصلی
یادگیری ماشین به سه دسته اصلی تقسیم میشود که هر یک برای حل نوع خاصی از مسائل طراحی شدهاند:


۱. یادگیری نظارتشده (Supervised Learning)
در این روش، دادههای آموزشی شامل ورودیها و برچسبهای صحیح (خروجیها) هستند. هدف، یادگیری مدلی است که بتواند برچسبهای صحیح را برای دادههای جدید پیشبینی کند.
- مثال: شناسایی نوع تابلوی راهنمایی (مثلاً تابلوی سرعت یا توقف) از تصویر یا تشخیص رقم دستنویس در MNIST.
- کاربردها: تشخیص هرزنامه، پیشبینی قیمت خانه، شناسایی حسابهای جعلی در شبکههای اجتماعی.
۲. یادگیری بدون نظارت (Unsupervised Learning)
در این روش، دادهها فاقد برچسب هستند و هدف، کشف ساختار یا الگوهای پنهان در دادههاست.
- مثال: خوشهبندی مشتریان یک فروشگاه بر اساس رفتار خرید یا کاهش ابعاد دادهها برای تجسم.
- کاربردها: گروهبندی مشتریان، تجسم دادهها، مدلسازی مولد (مانند تولید تصاویر مصنوعی با شبکههای مولد تخاصمی یا GANs).
۳. یادگیری تقویتی (Reinforcement Learning)
در این روش، یک عامل (Agent) از طریق آزمون و خطا و دریافت پاداش یا جریمه یاد میگیرد.
- مثال: آموزش یک ربات برای راه رفتن یا یک سیستم برای بازی شطرنج.
- کاربردها: رباتیک، بازیهای استراتژیک، بهینهسازی سیستمهای خودکار.
جدول مقایسه انواع یادگیری ماشین
| نوع یادگیری | دادههای مورد نیاز | هدف | مثال |
|---|---|---|---|
| نظارتشده | دادههای برچسبدار | پیشبینی برچسب | تشخیص رقم دستنویس |
| بدون نظارت | دادههای بدون برچسب | کشف ساختار | خوشهبندی مشتریان |
| تقویتی | پاداش/جریمه | بهینهسازی رفتار | آموزش ربات |
یادگیری نظارتشده: انسانها به ماشینها آموزش میدهند
چگونه کار میکند؟
در یادگیری نظارتشده، یک مجموعه داده آموزشی شامل ورودیها (مانند تصاویر ارقام) و برچسبهای صحیح (مانند ۰ تا ۹) به الگوریتم داده میشود. الگوریتم از این دادهها برای یادگیری مدلی استفاده میکند که بتواند برچسبهای صحیح را برای دادههای جدید پیشبینی کند.
طبقهبندی و رگرسیون
- طبقهبندی: پیشبینی یک کلاس گسسته (مانند تشخیص رقم در MNIST یا شناسایی تابلوی راهنمایی).
- رگرسیون: پیشبینی یک مقدار پیوسته (مانند قیمت خانه بر اساس متراژ و موقعیت).
مثال رگرسیون
فرض کنید دادههایی از فروش آپارتمانها داریم:
| متراژ (مترمربع) | تعداد اتاق | قیمت (میلیون تومان) |
|---|---|---|
| ۱۰۰ | ۲ | ۵۰۰ |
| ۱۵۰ | ۳ | ۷۰۰ |
| ۲۰۰ | ۴ | ۹۰۰ |
یک مدل رگرسیون خطی میتواند رابطهای بین متراژ و قیمت پیدا کند (مثلاً قیمت = 4 × متراژ + ۱۰۰).
چالشهای یادگیری ماشین: بیشبرازش
بیشبرازش (Overfitting) چیست؟
بیشبرازش زمانی رخ میدهد که مدل بیش از حد به دادههای آموزشی وابسته میشود و نمیتواند روی دادههای جدید (تست) عملکرد خوبی داشته باشد. این مشکل مانند یادگیری بیش از حد جزئیات یک درس بدون درک مفهوم کلی است.
چگونه از بیشبرازش جلوگیری کنیم؟
- تقسیم دادهها: دادهها به دو بخش آموزشی و آزمایشی تقسیم میشوند. مدل روی دادههای آموزشی ساخته میشود و روی دادههای آزمایشی ارزیابی میشود.
- انتخاب مدل مناسب: مدلهای بیش از حد انعطافپذیر (مانند شبکههای عصبی عمیق) ممکن است بیشبرازش شوند، مگر اینکه دادههای بسیار زیادی در دسترس باشد.
مثال بیشبرازش
فرض کنید مدلی برای پیشبینی موفقیت آهنگهای یک خواننده ساختهاید. اگر مدل شما قوانینی مانند «آهنگهای عاشقانه با کورس جذاب موفقاند، مگر اینکه به سوئد یا یوگا اشاره کنند» ایجاد کند، ممکن است به دادههای آموزشی بیش از حد وابسته شده و روی آهنگهای جدید عملکرد ضعیفی داشته باشد.
یادگیری بدون نظارت: کشف الگوهای پنهان
چگونه کار میکند؟
در یادگیری بدون نظارت، هیچ برچسب درستی وجود ندارد. الگوریتم سعی میکند ساختارهای پنهان در دادهها را کشف کند، مانند خوشهبندی یا تجسم.
مثال: خوشهبندی مشتریان
یک فروشگاه زنجیرهای میتواند دادههای خرید مشتریان را تحلیل کند و آنها را به گروههایی مانند «علاقهمندان به غذای سالم» یا «عاشقان پیتزا و نوشابه» تقسیم کند. الگوریتم خوشهبندی گروهها را شناسایی میکند، اما نامگذاری آنها به عهده کاربر است.
مدلسازی مولد
یادگیری بدون نظارت در مدلهای مولد، مانند شبکههای مولد تخاصمی (GANs)، نیز کاربرد دارد. این مدلها میتوانند دادههای جدیدی مانند تصاویر مصنوعی چهرههای انسانی تولید کنند.
جمعبندی
یادگیری ماشین با سه رویکرد نظارتشده، بدون نظارت، و تقویتی، ابزارهای قدرتمندی برای حل مسائل دنیای واقعی ارائه میدهد. از شناسایی ارقام دستنویس در MNIST تا خوشهبندی مشتریان یا آموزش رباتها، این روشها به هوش مصنوعی امکان میدهند تا از دادهها یاد بگیرد و تصمیمگیری کند. درک انواع یادگیری ماشین، گامی اساسی برای فهم کاربردهای گسترده هوش مصنوعی در زندگی روزمره است.
پرسشهای متداول
- چرا یادگیری ماشین برای هوش مصنوعی مهم است؟
یادگیری ماشین به سیستمها امکان میدهد از دادهها الگو استخراج کنند و بدون قوانین دستی، تصمیمگیری کنند. - تفاوت یادگیری نظارتشده و بدون نظارت چیست؟
یادگیری نظارتشده از دادههای برچسبدار برای پیشبینی استفاده میکند، در حالی که یادگیری بدون نظارت ساختارهای پنهان دادهها را کشف میکند. - چرا روشهای دستی برای شناسایی ارقام دستنویس ناکارآمد هستند؟
به دلیل تنوع زیاد در دستخطها و پیچیدگی تعریف قوانین دقیق، این روشها مقیاسپذیر نیستند. - بیشبرازش چیست و چگونه میتوان از آن جلوگیری کرد؟
بیشبرازش زمانی رخ میدهد که مدل بیش از حد به دادههای آموزشی وابسته میشود. تقسیم دادهها به آموزشی و آزمایشی و انتخاب مدل مناسب از آن جلوگیری میکند. - یادگیری تقویتی چه کاربردی دارد؟
این روش در سناریوهایی مانند رباتیک و بازیهای استراتژیک، جایی که عامل از پاداش و جریمه یاد میگیرد، کاربرد دارد.


طبقهبندیکننده نزدیکترین همسایه: ساده اما قدرتمند
مقدمه
طبقهبندیکننده نزدیکترین همسایه (K-Nearest Neighbors یا KNN) یکی از سادهترین و در عین حال مؤثرترین روشهای یادگیری ماشین است که با یافتن نمونههای مشابه در دادههای آموزشی، پیشبینی انجام میدهد. این روش در کاربردهایی مانند سیستمهای توصیهگر و تشخیص الگوها بسیار کاربردی است. این مقاله، که برای مجله «هوش مصنوعی سیمرغ» نوشته شده است، به بررسی اصول طبقهبندیکننده نزدیکترین همسایه، نحوه کارکرد آن، و کاربردهایش در دنیای واقعی میپردازد. با ما همراه شوید تا ببینیم چگونه این الگوریتم ساده، مسائل پیچیده را حل میکند.
طبقهبندیکننده نزدیکترین همسایه: اصول و مبانی
KNN چیست؟
طبقهبندیکننده نزدیکترین همسایه یک روش یادگیری نظارتشده است که یک نمونه جدید را با یافتن نزدیکترین نمونههای موجود در دادههای آموزشی طبقهبندی میکند. این الگوریتم بر اساس فرض سادهای کار میکند: نمونههایی که از نظر ویژگیها شبیه هم هستند، احتمالاً به یک کلاس تعلق دارند.
چگونه کار میکند؟
- انتخاب دادههای آموزشی: مجموعهای از دادهها با برچسبهای شناختهشده (مانند تصاویر ارقام دستنویس با برچسبهای ۰ تا ۹) در دسترس است.
- محاسبه فاصله: فاصله نمونه جدید با تمام نمونههای آموزشی محاسبه میشود (معمولاً با استفاده از فاصله اقلیدسی).
- انتخاب نزدیکترین همسایه: نزدیکترین نمونه (یا نمونهها در صورت استفاده از K>1) انتخاب شده و برچسب آن به نمونه جدید اختصاص مییابد.
مثال: تشخیص ارقام دستنویس
در مجموعه داده MNIST، برای شناسایی یک رقم دستنویس، KNN پیکسلهای تصویر جدید را با تصاویر آموزشی مقایسه میکند. اگر نزدیکترین تصویر آموزشی به عدد ۷ تعلق داشته باشد، تصویر جدید بهعنوان ۷ طبقهبندی میشود.
جدول نمونه دادههای MNIST
| تصویر | برچسب | ویژگیها (پیکسلها) |
|---|---|---|
| تصویر ۱ | ۷ | [۰, ۲۵۵, ۱۲۸, …] |
| تصویر ۲ | ۴ | [۲۵۵, ۰, ۶۴, …] |
| تصویر ۳ | ۷ | [۰, ۲۰۰, ۱۰۰, …] |
تعریف «نزدیکترین» در KNN
معیار فاصله
در KNN، مفهوم «نزدیکی» با استفاده از معیارهای فاصله مانند فاصله اقلیدسی تعریف میشود. فاصله اقلیدسی، فاصله مستقیم بین دو نقطه در فضا است، مانند کشیدن یک نخ بین دو نقطه روی کاغذ.
چالشهای تعریف فاصله
- در مسائل غیرهندسی (مانند متن)، تعریف فاصله دشوار است. برای مثال، در تشخیص ارقام MNIST، میتوان تطابق پیکسل به پیکسل را بررسی کرد، اما این روش به جابجایی یا مقیاسبندی تصاویر حساس است.
- در MNIST، تصاویر از قبل متمرکز شدهاند تا این مشکل کاهش یابد.
مثال: معیار فاصله در متن
برای مقایسه دو سند متنی، میتوان تعداد کلمات مشترک یا معیارهایی مانند فاصله کسینوسی را استفاده کرد. انتخاب معیار فاصله باید متناسب با نوع داده باشد.


کاربرد KNN: سیستمهای توصیهگر
سیستمهای توصیهگر و فیلتر مشارکتی
KNN در سیستمهای توصیهگر، مانند پیشنهاد موسیقی یا محصولات، بسیار کاربرد دارد. ایده اصلی این است که کاربران با رفتار مشابه در گذشته، احتمالاً در آینده نیز رفتار مشابهی خواهند داشت.
مثال: پیشنهاد موسیقی
فرض کنید در یک سرویس موسیقی، کاربری به آهنگهای دیسکوی دهه ۱۹۸۰ گوش داده است. سیستم KNN کاربرانی را که الگوی مشابهی دارند پیدا کرده و آهنگهای مورد علاقه آنها را به کاربر پیشنهاد میدهد.
تمرین: پیشبینی خرید مشتری
دادههای زیر خریدهای اخیر شش کاربر را نشان میدهد:
| کاربر | تاریخچه خرید | خرید اخیر |
|---|---|---|
| سانی | دستکش بوکس، موبی دیک، هدفون، عینک آفتابی | دانه قهوه |
| یونای | تیشرت، دانه قهوه، قهوهساز، دانه قهوه | دانه قهوه |
| یانینا | عینک آفتابی، کتانی، تیشرت، کتانی | جوراب پشمی |
| هنریک | ۲۰۰۱: ادیسه فضایی، هدفون، تیشرت، دستکش بوکس | دمپایی |
| ویله | تیشرت، دمپایی، عینک آفتابی، موبی دیک | ضدآفتاب |
| تیمو | موبی دیک، دانه قهوه، ۲۰۰۱: ادیسه فضایی، هدفون | دانه قهوه |
وظیفه: پیشبینی خرید بعدی کاربر تراویس که تاریخچه خریدش شامل چای سبز، تیشرت، عینک آفتابی، و دمپایی است.
- محاسبه شباهت: شباهت تراویس با هر کاربر با شمارش اقلام مشترک در تاریخچه خرید محاسبه میشود (خرید اخیر در نظر گرفته نمیشود).
- سانی: ۲ (تیشرت، عینک آفتابی)
- یونای: ۱ (تیشرت)
- یانینا: ۲ (تیشرت، عینک آفتابی)
- هنریک: ۲ (تیشرت، دمپایی)
- ویله: ۳ (تیشرت، عینک آفتابی، دمپایی)
- تیمو: ۰
- انتخاب نزدیکترین همسایه: ویله با شباهت ۳ نزدیکترین است.
- پیشبینی: خرید اخیر ویله (ضدآفتاب) بهعنوان خرید بعدی تراویس پیشبینی میشود.
نتیجه
- نزدیکترین کاربر: ویله
- پیشبینی خرید: ضدآفتاب
چالشها: حبابهای فیلتر
حباب فیلتر چیست؟
سیستمهای توصیهگر مبتنی بر KNN ممکن است کاربران را در «حبابهای فیلتر» قرار دهند، جایی که تنها محتوای مطابق با علایق گذشته آنها پیشنهاد میشود. این میتواند تنوع اطلاعات دریافتی را محدود کند.
چرا حبابهای فیلتر مضرند؟
- محدود شدن دیدگاهها: کاربران ممکن است فقط محتوای همراستا با باورهایشان ببینند، که میتواند تعصبات را تقویت کند.
- کاهش تنوع: در اخبار یا شبکههای اجتماعی، این پدیده ممکن است به قطبیسازی اجتماعی منجر شود.
راهحلهای پیشنهادی
- تنوع در پیشنهادات: سیستم میتواند بهصورت تصادفی محتوای خارج از علایق کاربر را پیشنهاد دهد.
- وزندهی به تنوع: الگوریتم میتواند معیاری برای تنوع محتوا در نظر بگیرد تا کاربران با دیدگاههای جدید آشنا شوند.
- شفافیت: به کاربران اطلاع داده شود که چرا محتوا پیشنهاد شده و امکان انتخاب گزینههای متنوعتر فراهم شود.
جمعبندی
طبقهبندیکننده نزدیکترین همسایه با سادگی و انعطافپذیری خود، ابزاری قدرتمند برای حل مسائل طبقهبندی و پیشنهاد در دنیای واقعی است. از تشخیص ارقام دستنویس تا پیشنهاد محصولات، این روش با یافتن شباهتها، تصمیمگیری میکند. با این حال، چالشهایی مانند حبابهای فیلتر نشاندهنده نیاز به طراحی هوشمندانهتر سیستمها هستند. درک KNN گامی مهم در فهم یادگیری ماشین و کاربردهای آن است.
پرسشهای متداول
- طبقهبندیکننده نزدیکترین همسایه چیست؟
KNN یک الگوریتم یادگیری نظارتشده است که نمونه جدید را بر اساس شباهت به نمونههای آموزشی طبقهبندی میکند. - چگونه فاصله در KNN محاسبه میشود؟
معمولاً از فاصله اقلیدسی استفاده میشود، اما معیار فاصله باید متناسب با نوع داده انتخاب شود. - KNN در چه کاربردهایی استفاده میشود؟
در سیستمهای توصیهگر، تشخیص الگو، و تحلیل دادههای متنی مانند تشخیص هرزنامه کاربرد دارد. - حبابهای فیلتر چیستند و چرا مشکلسازند؟
حبابهای فیلتر کاربران را به محتوای مشابه علایق گذشته محدود میکنند و ممکن است تنوع اطلاعات و دیدگاهها را کاهش دهند. - چگونه میتوان از حبابهای فیلتر جلوگیری کرد؟
با افزودن تنوع در پیشنهادات، وزندهی به محتوای جدید، و افزایش شفافیت در سیستمهای توصیهگر
فصل پنجم:شبکههای عصبی(انقلابی در هوش مصنوعی مدرن)
شبکههای عصبی و یادگیری عمیق (Deep Learning) از پیشرفتهترین ابزارهای هوش مصنوعی هستند که در حوزههایی مانند پردازش زبان طبیعی و تصویر، تحولات چشمگیری ایجاد کردهاند. این فناوریها با الهام از مغز انسان، به سیستمها امکان میدهند تا الگوهای پیچیده را از دادههای عظیم استخراج کنند. این مقاله، که برای مجله «هوش مصنوعی سیمرغ» نوشته شده است، به بررسی اصول شبکههای عصبی، نحوه ساخت آنها، و تکنیکهای پیشرفته مرتبط میپردازد. با ما همراه شوید تا ببینیم چگونه شبکههای عصبی، هوش مصنوعی را به سطح جدیدی بردهاند.
اصول شبکههای عصبی
شبکه عصبی چیست؟
شبکه عصبی، چه زیستی (مانند مغز انسان) و چه مصنوعی (شبیهسازیشده در کامپیوتر)، از تعداد زیادی واحد ساده به نام نورون تشکیل شده است که با دریافت و ارسال سیگنالها به یکدیگر، اطلاعات را پردازش میکنند. شبکههای عصبی مصنوعی با الهام از مغز طراحی شدهاند، اما معمولاً سادهتر هستند و برای حل مسائل هوش مصنوعی بهینه شدهاند.
یادگیری عمیق چیست؟
یادگیری عمیق شاخهای از یادگیری ماشین است که از شبکههای عصبی با چندین لایه (لایههای عمیق) استفاده میکند. این لایهها امکان یادگیری ساختارهای پیچیده را بدون نیاز به حجم غیرواقعی داده فراهم میکنند.
اجزای نورون
هر نورون در یک شبکه عصبی شامل اجزای زیر است:
- دندریتها (Dendrites): ورودیهای نورون که سیگنالها را دریافت میکنند.
- بدنه سلولی (Cell Body): بخش اصلی نورون که سیگنالهای ورودی را پردازش میکند.
- آکسون (Axon): خروجی نورون که سیگنال را به نورونهای دیگر منتقل میکند.
- سیناپس (Synapse): محل اتصال آکسون یک نورون به دندریت نورون دیگر.
جدول اجزای نورون
| جزء | نقش |
|---|---|
| دندریت | دریافت سیگنالهای ورودی |
| بدنه سلولی | پردازش سیگنالها |
| آکسون | ارسال سیگنال خروجی |
| سیناپس | اتصال بین نورونها |
چرا شبکههای عصبی مهماند؟
شبکههای عصبی به دلیل تواناییشان در پردازش دادههای پیچیده و استخراج الگوهای غیرخطی، در حوزههایی مانند تشخیص تصویر، پردازش زبان، و حتی رباتیک تحول ایجاد کردهاند. برخلاف روشهای منطقمحور که بر قوانین صریح تکیه دارند، شبکههای عصبی با شبیهسازی پردازشهای سطح پایینتر، به هوشی «ناشی از داده» دست مییابند.
چرا شبکههای عصبی مصنوعی توسعه مییابند؟
هدف دوگانه
- علوم اعصاب (Neuroscience): شبکههای عصبی مصنوعی برای مدلسازی مغز و درک عملکردهایی مانند حافظه و یادگیری استفاده میشوند. پروژههایی مانند «پروژه مغز انسان» و «ابتکار مغز» به دنبال شبیهسازی دقیقتر مغز برای درمان بیماریهایی مانند صرع یا آلزایمر هستند.
- هوش مصنوعی: هدف اصلی، ساخت سیستمهای هوشمندی است که از مغز الهام گرفتهاند، اما لزوماً آن را شبیهسازی نمیکنند. این سیستمها برای حل مسائلی مانند تشخیص گفتار یا تصویر بهینه شدهاند.
رابطهای مغز و کامپیوتر
یکی از کاربردهای آینده شبکههای عصبی، رابطهای مغز و کامپیوتر (BCIs) است که امکان کنترل دستگاهها با ذهن یا حتی انتقال اطلاعات به مغز را فراهم میکنند. اگرچه این فناوریها هنوز در مراحل اولیه هستند، اما پتانسیل تغییر زندگی افراد مبتلا به اختلالات عصبی را دارند.
مثال: تشخیص تصویر
شبکههای عصبی در تشخیص تصویر، مانند شناسایی اشیا در عکسها یا ارقام دستنویس در مجموعه داده MNIST، عملکرد فوقالعادهای دارند. این توانایی به دلیل ساختار لایهای و پردازش موازی آنهاست.
ویژگیهای منحصربهفرد شبکههای عصبی
ویژگی ۱: پردازش موازی
برخلاف کامپیوترهای سنتی که اطلاعات را بهصورت ترتیبی در واحد پردازش مرکزی (CPU) پردازش میکنند، شبکههای عصبی از تعداد زیادی نورون تشکیل شدهاند که بهصورت موازی اطلاعات را پردازش میکنند. این ویژگی باعث میشود شبکههای عصبی برای مسائل پیچیده مانند پردازش تصویر مناسب باشند.
ویژگی ۲: ادغام حافظه و پردازش
در کامپیوترهای سنتی، حافظه و پردازش از هم جدا هستند. اما در شبکههای عصبی، نورونها هم اطلاعات را ذخیره میکنند (بهصورت کوتاهمدت با فعال شدن یا نشدن، و بلندمدت با وزنهای سیناپسی) و هم آنها را پردازش میکنند. این ساختار، نیاز به انتقال مداوم دادهها بین حافظه و پردازشگر را حذف میکند.
پردازش موازی و سختافزار
شبکههای عصبی برای بهرهوری حداکثری به سختافزارهای خاصی مانند واحدهای پردازش گرافیکی (GPUs) نیاز دارند که قادر به پردازش موازی هستند. این سختافزارها، یادگیری عمیق را در مقیاس بزرگ ممکن کردهاند.
جدول مقایسه کامپیوتر سنتی و شبکه عصبی
| ویژگی | کامپیوتر سنتی | شبکه عصبی |
|---|---|---|
| پردازش | ترتیبی (CPU) | موازی (نورونها) |
| ذخیرهسازی | حافظه جدا | ادغام در نورونها و وزنها |
| کاربرد | محاسبات عمومی | مسائل پیچیده دادهمحور |
جمعبندی
شبکههای عصبی و یادگیری عمیق، با الهام از مغز انسان، انقلابی در هوش مصنوعی ایجاد کردهاند. این فناوریها با پردازش موازی و توانایی یادگیری از دادههای عظیم، در حوزههایی مانند پردازش تصویر و زبان طبیعی موفقیتهای چشمگیری کسب کردهاند. درک اصول شبکههای عصبی، از نورونها تا پردازش موازی، گامی کلیدی برای فهم چگونگی عملکرد هوش مصنوعی مدرن است.
پرسشهای متداول
- شبکه عصبی چیست؟
شبکه عصبی مجموعهای از نورونهای مصنوعی است که با دریافت و پردازش سیگنالها، الگوهای پیچیده را از دادهها استخراج میکند. - یادگیری عمیق چه تفاوتی با یادگیری ماشین سنتی دارد؟
یادگیری عمیق از شبکههای عصبی با چندین لایه استفاده میکند که قادر به یادگیری الگوهای پیچیدهتر بدون نیاز به دادههای عظیم هستند. - چرا شبکههای عصبی برای پردازش تصویر مناسباند؟
به دلیل توانایی پردازش موازی و استخراج الگوهای غیرخطی از دادههای پیچیده مانند تصاویر. - رابطهای مغز و کامپیوتر چیستند؟
فناوریهایی که امکان ارتباط مستقیم بین مغز و کامپیوتر را فراهم میکنند، مانند کنترل دستگاهها با ذهن. - چگونه شبکههای عصبی از مغز انسان الهام گرفتهاند؟
شبکههای عصبی با شبیهسازی نورونها و اتصالات سیناپسی، از ساختار مغز الهام میگیرند، اما سادهتر و برای هوش مصنوعی بهینه شدهاند
ساخت شبکههای عصبی: از نورونهای ساده تا سیستمهای پیچیده
شبکههای عصبی مصنوعی از واحدهای سادهای به نام نورونها تشکیل شدهاند که با ترکیب وزنها، ورودیها و توابع فعالسازی، میتوانند مسائل پیچیدهای مانند تشخیص تصویر یا پیشبینی را حل کنند. این مقاله، که برای مجله «هوش مصنوعی سیمرغ» نوشته شده است، به بررسی نحوه ساخت شبکههای عصبی، از پردازش ورودیها تا یادگیری وزنها، و کاربرد آنها در مسائل واقعی میپردازد. با ما همراه شوید تا ببینیم چگونه این ساختارهای ساده به سیستمهای هوشمند تبدیل میشوند.
نورونها: واحدهای پایه شبکههای عصبی
نورون مصنوعی چگونه کار میکند؟
نورون مصنوعی مشابه رگرسیون خطی و لجستیک عمل میکند. ورودیها با وزنها ضرب شده، جمع میشوند و از یک تابع فعالسازی عبور میکنند تا خروجی تولید شود.
اجزای اصلی نورون
- ورودیها (Inputs): مقادیر عددی که نورون دریافت میکند (مانند پیکسلهای تصویر).
- وزنها (Weights): پارامترهایی که اهمیت هر ورودی را تعیین میکنند.
- ترم قطع (Intercept): یک مقدار ثابت که به ترکیب خطی اضافه میشود.
- تابع فعالسازی (Activation Function): تابعی که ترکیب خطی را به خروجی تبدیل میکند.
ترکیب خطی
ترکیب خطی به صورت زیر محاسبه میشود:
ترکیب خطی = قطع + (وزن₁ × ورودی₁) + (وزن₂ × ورودی₂) + …
مثال: محاسبه ترکیب خطی
فرض کنید:
ترکیب خطی = 10.۰ + ۵.۴ × ۸ + (-۱۰.۲) × ۵ + (-۰.۱) × ۲۲ + ۱۰۱.۴ × (-۵) + ۰.۰ × ۲ + ۱۲.۰ × (-۳) = -۵۴۳.۰
- ترم قطع: ۱۰.۰
- ورودیها: ۸، ۵، ۲۲، -۵، ۲، -۳
- وزنها: ۵.۴، -۱۰.۲، -۰.۱، ۱۰۱.۴، ۰.۰، ۱۲.۰
تمرین ۲۱: پاسخها
- ترم قطع:
پاسخ: ب) ۱۰.۰ - ورودیها:
پاسخ: الف) ۸, ۵, ۲۲, -۵, ۲, -۳ - کدام ورودی کمترین تغییر را برای افزایش خروجی نیاز دارد؟
وزن چهارم (۱۰۱.۴) بزرگترین مقدار مطلق را دارد، بنابراین تغییر در ورودی چهارم (-۵) بیشترین تأثیر را دارد. برای افزایش خروجی، باید ورودیای تغییر کند که وزن مثبت بالایی دارد (وزن اول = 5.۴ یا وزن ششم = 12.۰). وزن ششم بزرگتر است، بنابراین:
پاسخ: دی) ششم - اگر ورودی پنجم یک واحد افزایش یابد، چه اتفاقی میافتد؟
وزن ورودی پنجم ۰.۰ است، بنابراین تغییر آن تأثیری ندارد.
پاسخ: الف) هیچچیز
توابع فعالسازی: قلب تصمیمگیری نورون
تابع فعالسازی چیست؟
پس از محاسبه ترکیب خطی، نورون آن را از یک تابع فعالسازی عبور میدهد تا خروجی تولید کند. این تابع تعیین میکند که نورون چگونه به ورودیها واکنش نشان دهد.
انواع توابع فعالسازی
- تابع هویت (Identity): خروجی برابر ترکیب خطی است (مشابه رگرسیون خطی).
- تابع پله (Step): اگر ترکیب خطی مثبت باشد، خروجی ۱ و اگر منفی باشد، خروجی ۰ است.
- تابع سیگموید (Sigmoid): نسخه نرمتری از تابع پله که خروجی بین ۰ و ۱ تولید میکند.
مقایسه توابع فعالسازی
| تابع | رفتار | کاربرد |
|---|---|---|
| هویت | خروجی = ورودی | مشابه رگرسیون خطی، کمتر در شبکههای عصبی |
| پله | خروجی باینری (۰ یا ۱) | مناسب برای طبقهبندی ساده |
| سیگموید | خروجی پیوسته (۰ تا ۱) | مناسب برای احتمالها |
تمرین ۲۲: پاسخها
با توجه به نمودارهای توابع فعالسازی:
- بالاترین خروجی برای ورودی ۵:
- سیگموید: ~۱
- پله: ۱
- هویت: ۵
پاسخ: هویت
- پایینترین خروجی برای ورودی -۵:
- سیگموید: ~۰
- پله: ۰
- هویت: -۵
پاسخ: هویت
- بالاترین خروجی برای ورودی -۲.۵:
- سیگموید: ~۰.۰۷۵
- پله: ۰
- هویت: -۲.۵
پاسخ: سیگموید
پرسپترون: مادر شبکههای عصبی مصنوعی
پرسپترون چیست؟
پرسپترون یک نورون ساده با تابع فعالسازی پله است که برای مسائل طبقهبندی باینری استفاده میشود. این مدل توسط فرانک روزنبلات در سال ۱۹۵۷ معرفی شد و بهعنوان پایه شبکههای عصبی مدرن شناخته میشود.
الگوریتم پرسپترون
الگوریتم پرسپترون وزنها را با استفاده از دادههای آموزشی بهروزرسانی میکند. هر زمان که طبقهبندی نادرست باشد، وزنها تنظیم میشوند تا خطا کاهش یابد. این روش مشابه طبقهبندیکننده نزدیکترین همسایه در سادگی است.
هیجان بیش از حد در هوش مصنوعی
پس از معرفی پرسپترون، ادعاهای اغراقآمیزی درباره تواناییهای آن مطرح شد. برای مثال، مقالهای در نیویورک تایمز در سال ۱۹۵۸ ادعا کرد که پرسپترون قادر به راه رفتن، صحبت کردن، و حتی خودآگاهی خواهد بود. این هیجان منجر به انتظارات غیرواقعی و در نهایت «زمستان هوش مصنوعی» در دهه ۱۹۶۰ شد.
درسهای تاریخی
مطالعه تاریخ پرسپترون، مانند مقاله «مطالعه جامعهشناختی جنجال پرسپترونها» (۱۹۹۶)، نشان میدهد که چگونه هیجان بیش از حد میتواند به ناامیدی منجر شود. این درس برای امروز نیز مهم است، بهویژه با ادعاهای مشابه درباره یادگیری عمیق و پروژههایی مانند «پروژه مغز انسان».
ساخت شبکه: ترکیب نورونها
معماری شبکه
شبکههای عصبی از لایههای نورون تشکیل شدهاند:
- لایه ورودی: ورودیها (مانند پیکسلهای تصویر) را دریافت میکند.
- لایههای مخفی: خروجیهای لایههای قبلی را پردازش میکنند و الگوهای پیچیده را استخراج میکنند.
- لایه خروجی: خروجی نهایی شبکه (مانند کلاس یا پیشبینی) را تولید میکند.
پرسپترون چندلایه (MLP)
پرسپترون چندلایه شبکهای با چندین لایه نورون است. یادگیری وزنها در این شبکهها پیچیدهتر از پرسپترون تکلایه است و با الگوریتم پسانتشار (Backpropagation) انجام میشود که در دهه ۱۹۸۰ احیای شبکههای عصبی را رقم زد.
پسانتشار
پسانتشار حساسیت خروجی شبکه به هر وزن را محاسبه کرده و وزنها را برای کاهش خطا بهروزرسانی میکند. این روش ریشه در کارهای اولیهای مانند پایاننامه سپو لیناینما در دانشگاه هلسینکی (۱۹۷۰) دارد که تمایز خودکار را معرفی کرد.
مثال: طبقهبندی صلیب و دایره
مسئله
هدف، طبقهبندی تصاویر ۵×۵ پیکسلی است که صلیب یا دایره را نشان میدهند. پیکسلهای رنگی ۱ و پیکسلهای سفید ۰ هستند.
ورودیها
تصویر صلیب: [۱,۰,۰,۰,۱,۰,۱,۰,۱,۰,۰,۰,۱,۰,۰,۰,۱,۰,۱,۰,۱,۰,۰,۰,۱]
تصویر دایره: [۰,۰,۱,۰,۰,۰,۱,۰,۱,۰,۱,۰,۰,۰,۱,۰,۱,۰,۱,۰,۰,۰,۱,۰,۰]
مدل
از یک نورون با ۲۵ وزن و تابع فعالسازی پله استفاده میکنیم. اگر ترکیب خطی مثبت باشد، خروجی ۱ (دایره) و اگر منفی باشد، خروجی ۰ (صلیب) است.
تنظیم وزنها
اگر تمام وزنها ۱ باشند:
- صلیب: ۹ (۹ پیکسل رنگی) → خروجی ۱ (نادرست)
- دایره: ۸ (۸ پیکسل رنگی) → خروجی ۱ (درست)
برای بهبود، وزن پیکسل مرکزی (پیکسل ۱۳) را -۱ و وزن پیکسلهای میانی اضلاع را ۱ قرار میدهیم:
- صلیب: -۱ (فقط پیکسل مرکزی فعال) → خروجی ۰ (درست)
- دایره: ۴ (چهار پیکسل میانی اضلاع) → خروجی ۱ (درست)
طبقهبندی چهرههای خندان
مسئله
هدف، طبقهبندی تصاویر چهرههای خندان و غمگین با استفاده از یک نورون ساده است. با تنظیم وزنها (۱ یا -۱ برای هر پیکسل)، میتوان خوشحال یا غمگین بودن را پیشبینی کرد.
چالش
طبقهبندی کامل همه چهرهها با یک نورون ساده غیرممکن است، زیرا این مدل برای مسائل پیچیده بیش از حد ساده است. برخی وزنها ممکن است چهرههای خندان را بهتر و برخی چهرههای غمگین را بهتر طبقهبندی کنند.
درس کلیدی
محدودیتهای مدلهای ساده نشاندهنده نیاز به شبکههای پیچیدهتر با لایههای مخفی و توابع فعالسازی پیشرفته است.
جمعبندی
شبکههای عصبی از نورونهای سادهای تشکیل شدهاند که با ترکیب وزنها، ورودیها، و توابع فعالسازی، میتوانند مسائل پیچیده را حل کنند. از پرسپترون تکلایه تا شبکههای چندلایه با پسانتشار، این فناوریها پایه هوش مصنوعی مدرن هستند. درک نحوه ساخت شبکههای عصبی، از محاسبات ساده تا معماریهای لایهای، گامی اساسی برای فهم یادگیری عمیق و کاربردهای آن است.
پرسشهای متداول
- نورون مصنوعی چگونه کار میکند؟
نورون ورودیها را با وزنها ضرب کرده، جمع میکند و از تابع فعالسازی عبور میدهد تا خروجی تولید کند. - چرا تابع هویت در شبکههای عصبی کم استفاده میشود؟
زیرا مشابه رگرسیون خطی است و ویژگیهای غیرخطی شبکههای عصبی را فراهم نمیکند. - پرسپترون چیست؟
یک نورون ساده با تابع فعالسازی پله که برای طبقهبندی باینری استفاده میشود. - پسانتشار چه نقشی در شبکههای عصبی دارد؟
پسانتشار وزنها را با محاسبه حساسیت خروجی به هر وزن بهروزرسانی میکند تا خطا کاهش یابد. - چرا یک نورون ساده نمیتواند همه مسائل را حل کند؟
به دلیل محدودیت در مدلسازی روابط پیچیده، که نیاز به شبکههای چندلایه و توابع فعالسازی پیشرفته دارد