


معرفی Gemma 3n: راهنمای جامع توسعهدهندگان
به گزارش مجله هوش مصنوعی سیمرغ، نخستین نسخه از مدل Gemma در اوایل سال گذشته میلادی معرفی شد و در مدت زمانی کوتاه، به اکوسیستمی پویـا و پررونق با بیش از ۱۶۰ میلیون بار دانلود دست یافت. این زیستبوم هوش مصنوعی شامل مجموعهای از مدلهای تخصصی است که در حوزههایی چون ایمنی، سلامت و پزشکی بهکار گرفته شدهاند. با این حال، آنچه در این میان برجستهتر جلوه میکند، خلاقیت و نوآوریهای چشمگیر جامعه توسعهدهندگان است — از نمونههایی چون Roboflow در بینایی ماشین سازمانی گرفته تا نسخههای قدرتمند ژاپنی که توسط مؤسسه علوم توکیو طراحی و توسعه یافتهاند. این تلاشهای جمعی، مسیر پیش روی ما را در تکامل این فناوری هموار کردهاند.
اکنون و در ادامهی این دستاوردها، نسخهی کامل Gemma 3n بهطور رسمی منتشر شده است. اگرچه پیشنمایش ماه گذشته تنها نگاهی مقدماتی به توانمندیهای آن ارائه میداد، امروز تمامی ظرفیتهای این معماری مبتنی بر موبایل در دسترس قرار گرفته است. Gemma 3n با تمرکز ویژه بر نیازهای جامعه توسعهدهندگان طراحی شده و با ابزارهایی محبوب مانند Hugging Face Transformers، llama.cpp، Google AI Edge، Ollama، MLX و بسیاری دیگر سازگار است. این مدل امکان آن را فراهم میسازد تا بهآسانی برای کاربردهای خاص و در سطح دستگاههای محلی (on-device) سفارشیسازی و استقرار یابد.
در ادامه این نوشتار، به بررسی دقیق نوآوریهای فنی مدل Gemma 3n خواهیم پرداخت، نتایج بنچمارکهای جدید آن را مرور میکنیم، و مسیر آغازین ساخت و توسعه بر بستر این مدل را بهطور گامبهگام ترسیم خواهیم کرد.
نوآوریهای برجسته در Gemma 3n
Gemma 3n یک پیشرفت بزرگ در هوش مصنوعی لبه (on-device AI) محسوب میشود و قابلیتهای قدرتمند چندوجهی (multimodal) را با عملکردی که پیش از این تنها در مدلهای پیشرو مبتنی بر ابر سال گذشته مشاهده میشد، به دستگاههای لبه میآورد.
- طراحی چندوجهی بومی: Gemma 3n بهطور بومی از ورودیهای تصویر، صوت، ویدئو و متن، و همچنین خروجیهای متنی پشتیبانی میکند.
- بهینهسازی برای دستگاههای لبه: مدلهای Gemma 3n با تمرکز بر بهرهوری طراحی شدهاند و در دو اندازه بر اساس پارامترهای مؤثر موجود هستند: E2B و E4B. در حالی که تعداد پارامترهای خام آنها بهترتیب ۵ میلیارد و ۸ میلیارد است، نوآوریهای معماری به آنها اجازه میدهد با مصرف حافظهای مشابه مدلهای سنتی ۲ میلیارد و ۴ میلیارد پارامتری عمل کنند و تنها به ۲ گیگابایت (برای E2B) و ۳ گیگابایت (برای E4B) حافظه نیاز داشته باشند.
- معماری پیشگامانه: در قلب Gemma 3n، مؤلفههای نوینی نظیر معماری MatFormer برای انعطافپذیری محاسباتی، تعبیهسازیهای هر لایه (Per Layer Embeddings – PLE) برای بهرهوری حافظه، LAuReL و AltUp برای بهرهوری معماری، و کدگذارهای جدید صوتی و بینایی مبتنی بر MobileNet-v5 بهینهسازی شده برای موارد استفاده روی دستگاه، قرار دارند.
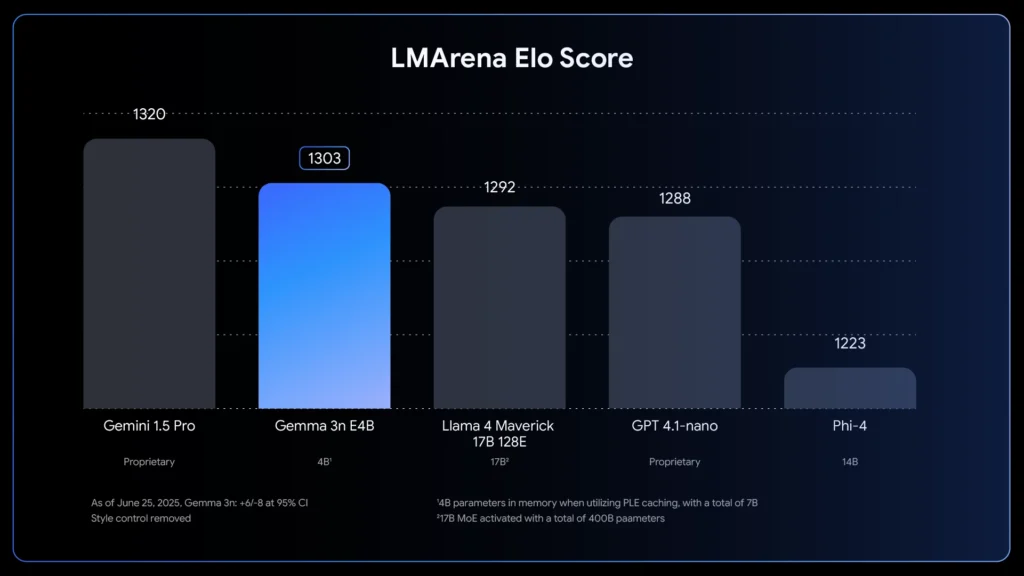
- کیفیت بهبودیافته: Gemma 3n بهبودهای کیفیتی چشمگیری را در چندزبانی بودن (پشتیبانی از ۱۴۰ زبان برای فهم متن و ۳۵ زبان برای فهم چندوجهی)، ریاضیات، کدنویسی و استدلال ارائه میدهد. نسخه E4B امتیاز LMArena بیش از ۱۳۰۰ را کسب کرده و بدین ترتیب اولین مدلی با کمتر از ۱۰ میلیارد پارامتر است که به این بنچمارک دست یافته است. نمودار LM Arena Elo Score، عملکرد Gemma 3n E4B را با امتیاز ۱۳۰۳ نشان میدهد، که آن را در رتبهای بالاتر از Llama 4 Maverick (1292) و GPT 4.1-nano (1288) و Phi-4 (1223) قرار میدهد، و تنها Gemini 1.5 Pro با ۱۳۲۰ امتیاز بالاتر از آن است.

MatFormer: یک مدل، اندازههای متنوع
هسته اصلی Gemma 3n، معماری MatFormer (Matryoshka Transformer) است؛ یک ترنسفورمر تو در تو و نوین که برای استنتاج الاستیک طراحی شده است. این مفهوم را میتوان مانند عروسکهای ماتروشکا تصور کرد: یک مدل بزرگتر حاوی نسخههای کوچکتر و کاملاً کاربردی از خود است. این رویکرد، ایده یادگیری بازنمایی ماتروشکا را از صرفاً تعبیهسازیها به تمامی مؤلفههای ترنسفورمر گسترش میدهد.


در طول آموزش مدل E4B با پارامترهای مؤثر ۴ میلیارد، یک زیرمدل E2B با پارامترهای مؤثر ۲ میلیارد بهطور همزمان در آن بهینهسازی میشود. این قابلیتها دو ویژگی قدرتمند و مورد استفاده را برای توسعهدهندگان فراهم میآورد:
- مدلهای از پیش استخراج شده: توسعهدهندگان میتوانند بهطور مستقیم مدل اصلی E4B را برای دستیابی به بالاترین قابلیتها یا زیرمدل مستقل E2B را که از پیش استخراج شده و تا ۲ برابر سرعت استنتاج سریعتر ارائه میدهد، دانلود و استفاده کنند.
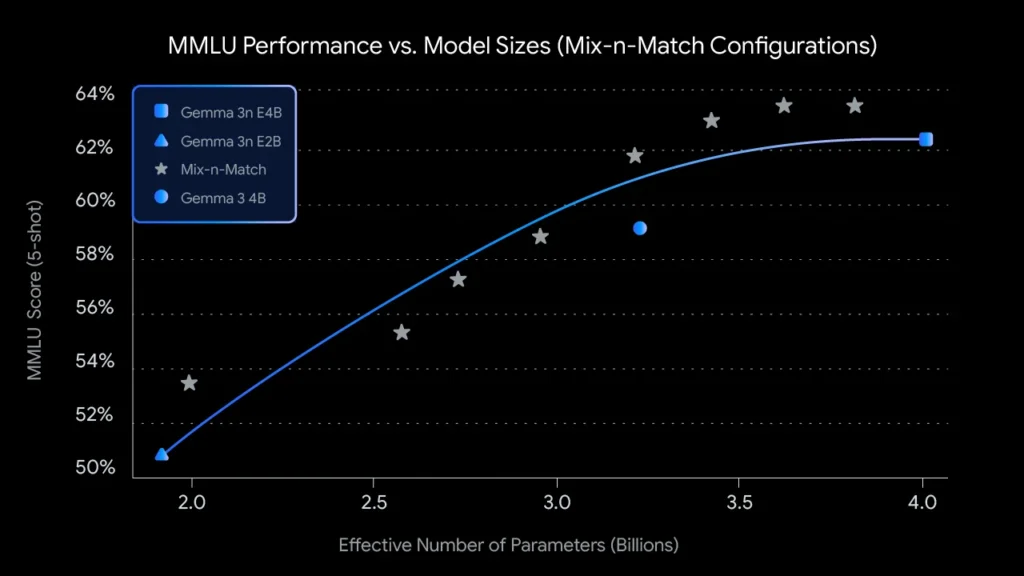
- اندازههای سفارشی با Mix-n-Match: برای کنترل دقیقتر متناسب با محدودیتهای سختافزاری خاص، میتوان طیفی از مدلهای با اندازههای سفارشی بین E2B و E4B را با استفاده از روشی به نام Mix-n-Match ایجاد کرد. این تکنیک به شما امکان میدهد پارامترهای مدل E4B را بهطور دقیق برش دهید، عمدتاً با تنظیم ابعاد پنهان شبکه پیشخور در هر لایه (از ۸۱۹۲ به ۱۶۳۸۴) و بهطور انتخابی از برخی لایهها صرفنظر کنید. ابزار MatFormer Lab نیز منتشر شده است که نشان میدهد چگونه میتوان این مدلهای بهینه را که با ارزیابی تنظیمات مختلف بر روی بنچمارکهایی مانند MMLU شناسایی شدهاند، بازیابی کرد.
تعبیهسازیهای هر لایه (PLE): افزایش بهرهوری حافظه
مدلهای Gemma 3n شامل تعبیهسازیهای هر لایه (PLE) هستند. این نوآوری برای استقرار روی دستگاه مناسب است، زیرا کیفیت مدل را بهطور چشمگیری بهبود میبخشد بدون آنکه میزان حافظه پرسرعت مورد نیاز بر روی شتابدهنده دستگاه (GPU/TPU) افزایش یابد. در حالی که مدلهای Gemma 3n E2B و E4B بهترتیب دارای ۵ میلیارد و ۸ میلیارد پارامتر هستند ، PLE امکان بارگذاری و محاسبه کارآمد بخش قابل توجهی از این پارامترها (تعبیهسازیهای مرتبط با هر لایه) را بر روی CPU فراهم میآورد. این بدین معنی است که تنها وزنهای اصلی ترنسفورمر (حدود ۲ میلیارد برای E2B و ۴ میلیارد برای E4B) نیاز به قرار گرفتن در حافظه شتابدهنده (VRAM) که معمولاً محدودتر است، دارند. با استفاده از تعبیهسازیهای هر لایه، میتوانید از Gemma 3n E2B با تنها حدود ۲ میلیارد پارامتر بارگذاری شده در شتابدهنده خود استفاده کنید.
اشتراکگذاری KV Cache: پردازش سریعتر متون طولانی
پردازش ورودیهای طولانی، مانند دنبالههای حاصل از جریانهای صوتی و تصویری، برای بسیاری از کاربردهای پیشرفته چندوجهی روی دستگاه ضروری است. Gemma 3n قابلیت اشتراکگذاری KV Cache را معرفی میکند، که برای تسریع قابل توجه زمان تا اولین توکن در کاربردهای پاسخگویی جریانی طراحی شده است. اشتراکگذاری KV Cache نحوه مدیریت مدل در مرحله اولیه پردازش ورودی (که اغلب فاز “prefill” نامیده میشود) را بهینهسازی میکند. کلیدها و مقادیر لایههای میانی از توجه محلی و جهانی مستقیماً با تمامی لایههای بالایی به اشتراک گذاشته میشوند و عملکرد prefill را در مقایسه با Gemma 3 4B دو برابر بهبود میبخشند. این بدان معنی است که مدل میتواند دنبالههای پرامت طولانی را بسیار سریعتر از قبل دریافت و درک کند.
درک صوتی: معرفی تبدیل گفتار به متن و ترجمه
Gemma 3n از یک کدگذار صوتی پیشرفته مبتنی بر مدل گفتار جهانی (Universal Speech Model – USM) استفاده میکند. این کدگذار برای هر ۱۶۰ میلیثانیه از صدا یک توکن تولید میکند (تقریباً ۶ توکن در ثانیه)، که سپس بهعنوان ورودی به مدل زبان ادغام میشود و بازنمایی دقیقی از زمینه صوتی ارائه میدهد. این قابلیت صوتی یکپارچه، ویژگیهای کلیدی را برای توسعه روی دستگاه فراهم میآورد، از جمله:
- تشخیص خودکار گفتار (ASR): امکان تبدیل با کیفیت گفتار به متن را مستقیماً روی دستگاه فراهم میسازد.
- ترجمه خودکار گفتار (AST): زبان گفتاری را به متن در زبان دیگر ترجمه میکند.نتایج AST بهویژه برای ترجمه بین انگلیسی و اسپانیایی، فرانسوی، ایتالیایی و پرتغالی بسیار قوی است، که پتانسیل بالایی را برای توسعهدهندگانی که کاربردهایی را در این زبانها هدف قرار میدهند، ارائه میدهد. برای کارهایی مانند ترجمه گفتار، استفاده از روش Chain-of-Thought میتواند نتایج را بهطور قابل توجهی بهبود بخشد.
MobileNet-V5: کدگذار بینایی پیشرفته و با قابلیتهای هنری
در کنار قابلیتهای صوتی یکپارچه، Gemma 3n از یک کدگذار بینایی جدید و بسیار کارآمد، MobileNet-V5-300M، بهره میبرد که عملکردی در سطح هنری برای کارهای چندوجهی روی دستگاههای لبه ارائه میدهد. MobileNet-V5 که برای انعطافپذیری و قدرت در سختافزارهای محدود طراحی شده است، ویژگیهای زیر را در اختیار توسعهدهندگان قرار میدهد:
- رزولوشنهای ورودی چندگانه: بهطور بومی از رزولوشنهای ۲۵۶×۲۵۶، ۵۱۲×۵۱۲، و ۷۶۸×۷۶۸ پیکسل پشتیبانی میکند، که به شما امکان میدهد بین عملکرد و جزئیات برای کاربردهای خاص خود تعادل برقرار کنید.
- درک بصری گسترده: با آموزش بر روی مجموعه دادههای چندوجهی گسترده، در طیف وسیعی از وظایف درک تصویر و ویدئو عالی عمل میکند.
- توان عملیاتی بالا: تا ۶۰ فریم در ثانیه را بر روی یک Google Pixel پردازش میکند، که امکان تحلیل ویدئوی بلادرنگ روی دستگاه و تجربیات تعاملی را فراهم میآورد.
این سطح از عملکرد با نوآوریهای معماری متعدد، از جمله مبنای پیشرفتهای از بلوکهای MobileNet-V4، معماری بهطور قابل توجهی مقیاسبندی شده، و یک آداپتور Multi-Scale Fusion VLM نوین، حاصل شده است. MobileNet-V5-300M بهطور قابل ملاحظهای از SoVIT پایه در Gemma 3 پیشی میگیرد و بر روی یک Google Pixel Edge TPU، با کوانتیزاسیون ۱۳ برابر و بدون کوانتیزاسیون ۶.۵ برابر سرعت بیشتری را ارائه میدهد، به ۴۶ درصد پارامتر کمتر نیاز دارد و دارای ردپای حافظه ۴ برابر کوچکتر است، در حالی که دقت بسیار بالاتری را در وظایف بینایی-زبان فراهم میآورد.
ساخت با جامعه توسعهدهندگان
در دسترس قرار دادن Gemma 3n از روز اول یک اولویت بوده است. همکاری با بسیاری از توسعهدهندگان برجسته متنباز برای اطمینان از پشتیبانی گسترده در ابزارها و پلتفرمهای محبوب، از جمله مشارکت تیمهای AMD، Axolotl، Docker، Hugging Face، llama.cpp، LMStudio، MLX، NVIDIA، Ollama، RedHat، SGLang، Unsloth و vLLM، مایه افتخار است. با این حال، این اکوسیستم تنها آغاز راه است؛ قدرت واقعی این فناوری در چیزی است که توسعهدهندگان با آن خواهند ساخت. به همین دلیل، “چالش تأثیر Gemma 3n” راهاندازی شده است. مأموریت این چالش، استفاده از قابلیتهای منحصر به فرد روی دستگاه، آفلاین و چندوجهی Gemma 3n برای ساخت محصولی جهت بهبود جهان است. با ۱۵۰,۰۰۰ دلار جایزه، به دنبال یک داستان ویدئویی جذاب و یک دمو “شگفتانگیز” هستیم که تأثیر واقعی در جهان را نشان دهد.
شروع به کار با Gemma 3n
برای کاوش در پتانسیل Gemma 3n، میتوانید:
- مستقیماً آزمایش کنید: از Google AI Studio برای امتحان Gemma 3n با چند کلیک ساده استفاده کنید. مدلهای Gemma را میتوان مستقیماً از AI Studio به Cloud Run نیز استقرار داد.
- با ابزارهای محبوب AI روی دستگاه بسازید: Google AI Edge Gallery/LiteRT-LLM، Ollama، MLX، llama.cpp، Docker، transformers.js و موارد دیگر.
- از ابزارهای توسعه مورد علاقه خود استفاده کنید: از ابزارها و چارچوبهای مورد علاقه خود از جمله Hugging Face Transformers و TRL، NVIDIA NeMo Framework، Unsloth و LMStudio بهره ببرید.
- به روش خود استقرار دهید: Gemma 3n گزینههای استقرار متعددی از جمله Google GenAI API، Vertex AI، SGLang، vLLM و NVIDIA API Catalog را ارائه میدهد.
