شرکت OpenAI با رونمایی از مدل GPT-5.2، تعریف جدیدی از «کار حرفهای» (Professional Knowledge Work) ارائه کرده است. این مدل که به عنوان پیشرفتهترین مدل مرزی (Frontier Model) معرفی شده، نه تنها در پردازش متن، بلکه در مدیریت پروژههای پیچیده، کدنویسی و تحلیلهای طولانیمدت، استانداردهای جهانی را جابهجا کرده است.
OpenAI در تاریخ ۱۱ دسامبر ۲۰۲۵ از GPT-5.2 رونمایی کرد؛ مدلی که نهتنها یک ارتقای عددی نسبت به نسخههای قبلی نیست، بلکه یک جهش واقعی در «کار حرفهای مبتنی بر هوش مصنوعی» به حساب میآید. طبق گزارش OpenAI، کاربران سازمانی ChatGPT بهطور میانگین روزانه بین ۴۰ تا ۶۰ دقیقه در زمان خود صرفهجویی میکنند و کاربران حرفهای حتی بیش از ۱۰ ساعت در هفته بهرهوری بیشتری دارند.
GPT-5.2 با تمرکز ویژه بر وظایف اقتصادی ارزشمند، استدلال بلندمدت، کدنویسی عاملمحور (Agentic Coding)، تحلیل اسناد حجیم و درک پیشرفته تصویر طراحی شده است.
بر اساس گزارشها، کاربران سازمانی ChatGPT هماکنون روزانه ۴۰ تا ۶۰ دقیقه در وقت خود صرفهجویی میکنند و این رقم برای کاربران حرفهای به بیش از ۱۰ ساعت در هفته میرسد. GPT-5.2 طراحی شده تا این ارزش اقتصادی را با قابلیتهای برتر در ساخت اکسل، پاورپوینت، کدنویسی و درک تصاویر به حداکثر برساند.
خانواده سه گانه GPT-5.2: کدام مدل مناسب شماست؟
OpenAI در این بروزرسانی، مدل را در سه سطح مختلف برای نیازهای متفاوت عرضه کرده است:
GPT-5.2 Instant: مدل سریع و اقتصادی برای کارهای روزمره، نوشتن فنی و ترجمه. این مدل جایگزین نسخههای سبک قبلی شده و توضیحات شفافتری ارائه میدهد.
GPT-5.2 Thinking: مدل استاندارد برای «کار عمیق». این مدل در استدلالهای چندمرحلهای، کدنویسی و مدیریت ایجنتها تخصص دارد.
GPT-5.2 Pro: هوشمندترین و گرانترین نسخه. این مدل برای پاسخ به سختترین سوالات علمی و ریاضی طراحی شده و توسعهدهندگان میتوانند سطح استدلال (Reasoning Effort) آن را روی حالت جدید xhigh تنظیم کنند.
انواع مدل های GPT-5.2
تحلیل عملکرد و بنچمارکها (بر اساس گزارش فنی)
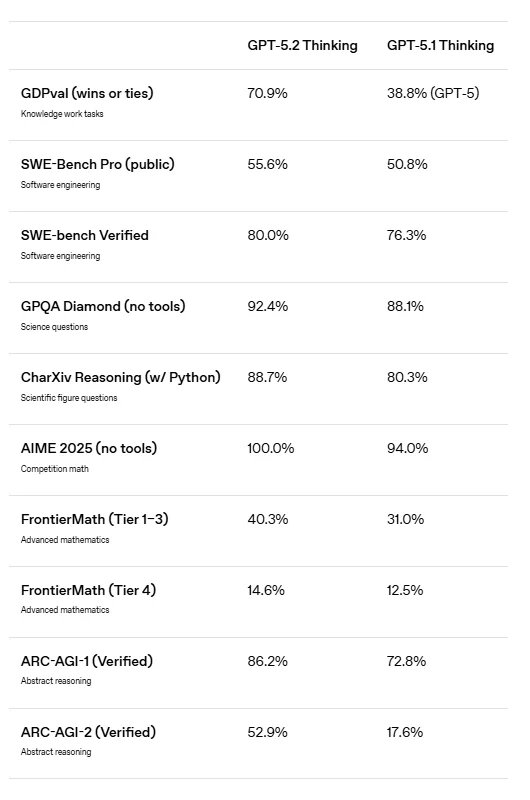
مدل GPT-5.2 در تمامی آزمونهای معتبر، رقبای خود و حتی متخصصان انسانی را پشت سر گذاشته است.
۱. تسلط بر وظایف شغلی (GDPval)
در بنچمارک GDPval که وظایف ۴۴ شغل واقعی (از حسابداری تا مدیریت فروش) را شبیهسازی میکند:
GPT-5.2 Thinking در ۷۰.۹٪ موارد همسطح یا بهتر از انسان عمل کرده است.
GPT-5.2 Pro به رکورد ۷۴.۱٪ دست یافته است.
مقایسه: این عدد برای مدل GPT-5 تنها ۳۸.۸٪ بود.
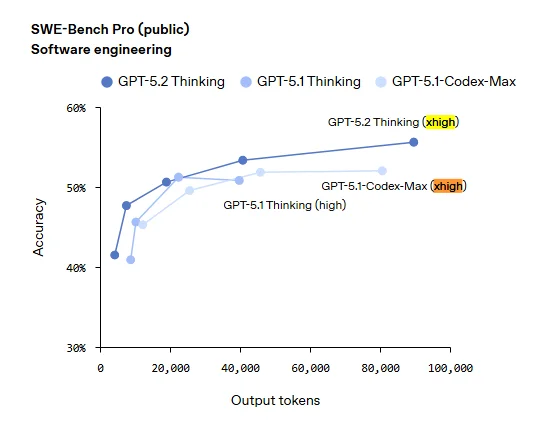
۲. تحولی در کدنویسی و مهندسی نرمافزار
مدیرعامل پلتفرم کدنویسی Windsurf این مدل را «بزرگترین جهش در کدنویسی ایجنتی» نامیده است.
SWE-bench Verified: امتیاز ۸۰.۰٪ (در برابر ۷۶.۳٪ نسخه قبلی).
Tau2-bench Telecom: امتیاز حیرتانگیز ۹۸.۷٪ در استفاده از ابزارها برای پشتیبانی مشتری.
شرکتهایی مانند JetBrains، Cognition و Triple Whale گزارش دادهاند که این مدل در دیباگ کردن و بررسی کد (Code Review) عملکردی بینظیر دارد.
۳. ریاضیات و علوم پیشرفته (Science & Math)
GPQA Diamond: امتیاز ۹۳.۲٪ برای نسخه Pro در سوالات سطح دکتری.
FrontierMath: حل ۴۰.۳٪ از مسائل ریاضی فوقتخصصی (Tier 1-3) که مدلهای قبلی در آن ناتوان بودند.
AIME 2025: حل ۱۰۰٪ مسائل ریاضی مسابقات.
قابلیتهای نوین: دیدن، شنیدن و یادآوری
بینایی ماشین و درک رابط کاربری (Vision)
مدل جدید در درک تصاویر فنی جهش داشته است. در بنچمارک ScreenSpot-Pro که توانایی درک اسکرینشاتهای نرمافزاری را میسنجد، امتیاز مدل از ۶۴.۲٪ به ۸۶.۳٪ رسیده است. این یعنی GPT-5.2 میتواند دقیقاً بفهمد دکمهها و منوها در یک نرمافزار کجا قرار دارند و چگونه باید با آنها تعامل کرد.
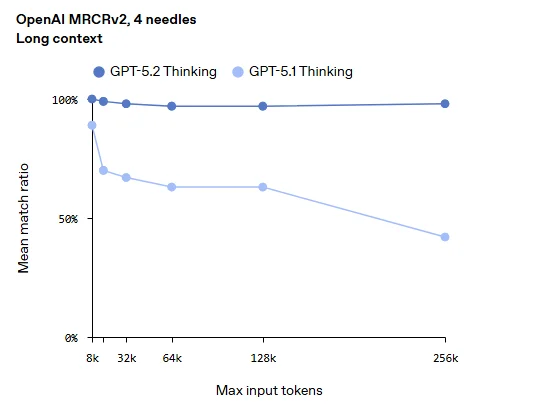
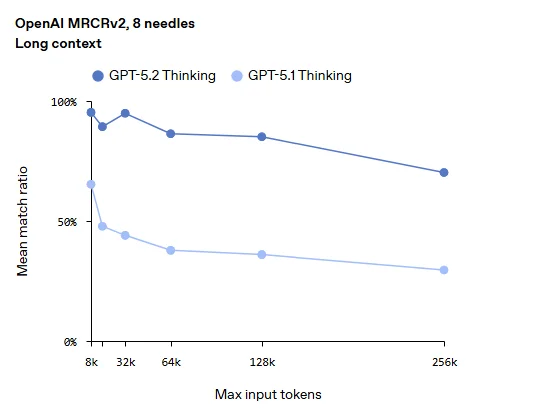
اسناد با اطلاعات زیاد(Long Context) تا ۲۵۶ هزار توکن
در تستهای “سوزن در انبار کاه” (MRCRv2)، مدل Thinking در بازه ۲۵۶ هزار توکن (معادل صدها صفحه متن)، دقت بازیابی اطلاعات را به ۷۷٪ تا ۱۰۰٪ (بسته به نوع تست) رسانده است که بسیار بالاتر از دقت ۲۹.۶ درصدی مدلهای قبلی در این حجم از داده است.
ایمنی و سلامت روان (Safety)
OpenAI تمرکز ویژهای روی کاهش خطرات داشته است. طبق جدول ارزیابی سلامت روان:
شاخص ایمنی در خودآزاری (Self-harm): ارتقا به ۰.۹۶۳.
شاخص ایمنی در سلامت روان (Mental Health): جهش چشمگیر از ۰.۶۸۴ (در نسخه ۵.۱) به ۰.۹۱۵ در GPT-5.2 Thinking.
همچنین سیستم جدید «پیشبینی سن» برای محافظت از کاربران زیر ۱۸ سال فعال شده است.
قیمتگذاری و API (برای توسعهدهندگان)
قیمتهای API نشاندهنده استراتژی OpenAI برای تشویق به استفاده از حافظه طولانی (Caching) است:
مدل
قیمت ورودی (Input) / 1M
قیمت ورودی کش شده
قیمت خروجی (Output) / 1M
gpt-5.2
۱.۷۵ دلار
۰.۱۷۵ دلار (۹۰٪ تخفیف)
۱۴.۰۰ دلار
gpt-5.2-pro
۲۱.۰۰ دلار
–
۱۶۸.۰۰ دلار
gpt-5.1
۱.۲۵ دلار
۰.۱۲۵ دلار
۱۰.۰۰ دلار
نکته مهم: استفاده از ورودیهای کش شده (Cached Input) هزینه را تا ۹۰٪ کاهش میدهد که برای ایجنتهای طولانیمدت بسیار حیاتی است.
اکوسیستم شرکا (Partners)
این مدل تنها یک ابزار چت نیست؛ بلکه موتوری است که توسط غولهای فناوری تست و تایید شده است. لیست شرکایی که از GPT-5.2 استفاده میکنند شامل موارد زیر است:
مدیریت اسناد و پروژه: Notion, Box, Zoom
تجارت الکترونیک: Shopify, Triple Whale
کدنویسی و داده: Databricks, JetBrains, Cognition, Windsurf
حقوقی: Harvey
My flight from Paris to New York was delayed, and I missed my connection to Austin. My checked bag is also missing, and I need to spend the night in New York. I also require a special front-row seat for medical reasons. Can you help me?
مقایسه دو مدل GPT-5.1 و GPT-5.2
نتیجهگیری نهایی
GPT-5.2 یک بروزرسانی ساده نیست؛ بلکه تغییری بنیادین در نحوه تعامل ما با هوش مصنوعی است. برای کاربران عادی، نسخه Instant سرعت و دقت را به ارمغان میآورد و برای متخصصان، نسخه Thinking و Pro همانند استخدام یک دستیار فوقتخصص با هزینه ناچیز است. کاهش توهمات (Hallucinations) و افزایش قدرت استدلال، این مدل را به قابلاعتمادترین گزینه برای محیطهای تجاری و علمی تبدیل کرده است.