
راهنمای آسان ثبت نام ChatGPT: شاید در اوایل چتباتها تنها به عنوان یکسری ابزار نمایشی و لوکس به حساب میآمدند ، اما امروزه به مهمترین دستیار دیجیتال هر کاربر حرفهای و متخصص تبدیل شدهاند. از تولید محتوا و کدنویسی گرفته تا تحلیل داده، برنامهریزی روزانه و حتی مدیریت کسبوکار، همهچیز با هوش مصنوعی سادهتر شده است. شاید باور نکنید اما خود مدیران و سازندگان و حتی پرسنل شرکتهای بزرگ فناوری روزانه چندین ساعت از این ابزارها برای ارتقا بهرهوری خود استفاده میکنند.
اما یک سؤال مهم همچنان ذهن بسیاری را بخود مشغول نموده است:
چطور باید در این ابزارهای قدرتمند ثبتنام کنیم؟
و اصلاً کدام پلتفرمها بهتر و در دسترستر هستند؟
در این مطلب آموزشی، بهصورت مرحلهبهمرحله نحوه ثبتنام در مهترین و شناختهشدهترین چتبات آموزش داده خواهد شد؛
پردازش زبان طبیعی و مدلهای زبانی بزرگ؛ مبانی، مزایا و چالشها
مقدمه
پردازش زبان طبیعی (Natural Language Processing – NLP) شاخهای تخصصی از هوش مصنوعی است که به توسعه الگوریتمهایی میپردازد که بتوانند زبان انسان را تحلیل، تفسیر و تولید کنند. هدف اصلی NLP ایجاد امکان تعامل طبیعیتر میان انسان و ماشین است؛ تعاملی که همزمان مبتنی بر ساختارهای دستوری، معناشناختی و الگوهای آماری باشد. این حوزه مجموعه گستردهای از وظایف از جمله تحلیل احساسات، استخراج اطلاعات، خلاصهسازی، ترجمه ماشینی و پاسخگویی به پرسش را دربر میگیرد.
در سالهای اخیر، پیشرفتهای کلیدی در معماری شبکههای عصبی، بهویژه مدل ترنسفورمر، زمینهساز ظهور نسل جدیدی از سامانههای زبانی شده است که تحت عنوان مدلهای زبانی بزرگ (Large Language Models – LLMs) شناخته میشوند.
مدلهای زبانی بزرگ؟
مدلهای زبانی بزرگ مجموعهای از شبکههای عصبی عمیق هستند که با آموزش روی حجم عظیمی از دادههای متنی، توانایی یادگیری الگوهای زبانی پیچیده را بهدست میآورند. این مدلها، مانند GPT، Gemini، Claude یا Llama، میتوانند متن را با سطحی از دقت و روانی تولید کنند که بهطور قابل توجهی به زبان طبیعی انسان نزدیک است.
LLMها برخلاف سیستمهای سنتی NLP که برای هر وظیفه نیاز به آموزش جداگانه داشتند، قادرند دامنه گستردهای از فعالیتها را بدون نیاز به مهندسی اختصاصی یا دادههای برچسبخورده انجام دهند. این توانایی یکی از تحولات بنیادین در حوزه هوش مصنوعی محسوب میشود.
مزایای مدلهای زبانی بزرگ
۱. چندکاربردی بودن
یکی از مهمترین مزایای LLMها توانایی انجام همزمان وظایف مختلف است. این مدلها میتوانند متن تولید کنند، مکالمه انجام دهند، تحلیل اسناد ارائه دهند، کد بنویسند یا حتی نقش جستجوگر اطلاعات را ایفا کنند، بدون آنکه برای هر وظیفه آموزش مجدد ببینند.
۲. تولید متن با ساختار طبیعی
LLMها الگوهای پیچیده نحوی و معنایی را در مقیاس بسیار بزرگ فرا میگیرند، از اینرو خروجی آنها در بسیاری از موارد به گفتار یا نوشتار انسانی نزدیک است. این ویژگی سبب شده کاربرد آنها در تولید محتوا، تحلیل متون و ابزارهای تعاملی بهسرعت افزایش یابد.
۳. افزایش بهرهوری و سرعت
استفاده از LLMها در سازمانها، رسانهها و کسبوکارها بهطور چشمگیری سرعت انجام امور مرتبط با محتوا، تحلیل داده و پشتیبانی کاربران را افزایش داده است؛ بهویژه آنچه به اتوماسیون و کاهش زمان انجام کار بازمیگردد.
۴. توانایی یادگیری با مثالهای محدود
در بسیاری از موارد، تنها چند مثال یا حتی یک دستور متنی ساده کافی است تا مدل بتواند وظیفه جدیدی را اجرا کند. این قابلیت اصطلاحاً بهعنوان Few-shot یا Zero-shot Learning شناخته میشود و یکی از مهمترین مزیتهای LLMها نسبت به نسلهای قبلی مدلهای زبانی است.
چالشها و محدودیتهای مدلهای زبانی بزرگ
۱. تولید اطلاعات نادرست یا ساختگی
LLMها بر اساس احتمالات پیشبینی میکنند و نه بر اساس درک واقعی. همین موضوع گاهی منجر به تولید اطلاعات ناصحیح یا بازتولید دادههایی میشود که در متنهای آموزشی آنها وجود داشته است. این پدیده با عنوان توهم (Hallucination) شناخته میشود و یکی از چالشهای کلیدی در استفاده صنعتی از این مدلهاست.
۲. وابستگی به دادههای آموزشی
اگر دادههای آموزشی دارای سوگیری، خطا یا عدم تعادل باشند، مدل همان سوگیریها را بازتولید خواهد کرد. در نتیجه، کیفیت خروجی بهطور مستقیم وابسته به کیفیت و تنوع دادههای آموزشی است.
۳. هزینه محاسباتی بالا
آموزش و اجرای مدلهای بزرگ نیازمند منابع محاسباتی سنگین و زیرساخت قدرتمند است. هزینههای مربوط به پردازش ابری، سختافزارهای ویژه (GPU/TPU) و مصرف انرژی، استفاده گسترده از این مدلها را برای بسیاری از سازمانها دشوار میکند.
۴. محدودیت دانش بهروز
مدلهایی که بدون اتصال به منابع اطلاعاتی زنده کار میکنند، به دادههایی محدودند که تا زمان آموزش در اختیار مدل بوده است. این موضوع بهویژه در حوزههایی که بهسرعت تغییر میکنند، مانند اخبار، سیاست، فناوری و امور مالی، چالشبرانگیز است.
۵. حساسیت به نحوه ارائه دستور
خروجی مدلها نسبت به نحوه نگارش دستور یا پرامپت بسیار حساس است. تغییرات جزئی در بیان یک سؤال یا درخواست، میتواند منجر به خروجی کاملاً متفاوت شود. این موضوع نیازمند مهارت در تدوین پرامپت و تجربه عملی است.
ثبتنام
بخش اول راهنمای گام به گام ثبت نام: الزامات سهگانه؛ آمادگی پیش از ثبت نام
برای اینکه فرآیند ثبت نام شما با شکست مواجه نشود، ابتدا باید سه پیشنیاز کلیدی را آماده کنید. بیتوجهی به هر یک از این موارد، شما را دوباره به نقطه اول بازمیگرداند.
۱. ابزار تغییر IP معتبر (VPN/VPS)
سرویسهای OpenAI به شدت نسبت به IP کاربران حساس هستند. نیاز به یک VPN یا VPS یا تحریمگذر با کیفیت و با قابلیت ارائه آیپی ثابت از کشورهای غیرمحدود (مانند آمریکا، آلمان، هلند یا کانادا) دارید. اکیداً توصیه میشود از تغییر مکرر کشور خودداری کنید تا حساب کاربری شما به عنوان یک حساب مشکوک شناسایی نشود.
۲. ایمیل اختصاصی و جدید
از یک آدرس ایمیل (ترجیحاً جیمیل) استفاده کنید که تاکنون برای ثبت نام در هیچ سرویس وابسته به OpenAI استفاده نشده باشد. استفاده از ایمیلهای تمیز، فرآیند احراز هویت را تسهیل میکنند.
۳. کلید اصلی: شماره تلفن مجازی معتبر
در روزهای ابتدایی عرضه این مدلها داشتن شماره تلفن برای دریافت پیامک به چالشبرانگیزترین بخش ثبتنام تبدیل شده بود. از آنجا که شمارههای ایران پذیرفته نمیشدند، باید از سرویسهای معتبر ارائهدهنده شماره مجازی (Virtual Number) استفاده میکردیم. این شماره باید قابلیت دریافت پیامک (SMS) از اپراتور OpenAI را داشته میداشت. گرچه هزینه این شمارهها معمولاً بسیار پایین بود، اما برای دسترسی ضروری بودند. خوشبختانه مدتی است مدلها این فرایند را از روند احراز هویت حذف نموده و به ثبتنام با ایمیل اکتفا نمودهاند.
بخش دوم راهنمای گام به گام ثبت نام
پس از آمادهسازی الزامات سهگانه، زمان ثبت نام نهایی فرا رسیده است. این فرآیند را دقیقاً مطابق مراحل زیر طی کنید:
گام ۱: فعالسازی IP و شروع فرآیند
- VPN خود را روشن کنید و از اتصال آن به کشور انتخابی مطمئن شوید.
- به آدرس وبسایت رسمی
chat.openai.comمراجعه کرده و برای ثبتنام میبایست از بالای صفحه روی گزینه SignSign up for free را انتخاب کنید.

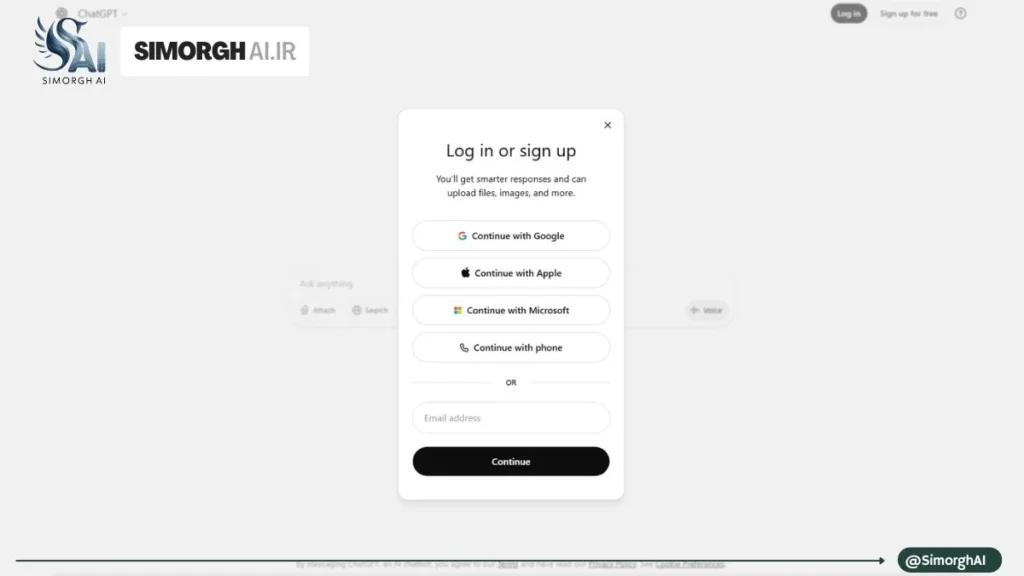
گام ۲: وارد کردن مشخصات اولیه و تأیید ایمیل
- در کادر پایین ایمیل جدید خود را وارد کرده و یک رمز عبور قوی انتخاب کنید.
- پس از کلیک بر روی “Continue”، یک ایمیل تأیید هویت از OpenAI به صندوق پستی شما ارسال میشود.
- وارد ایمیل شده و روی لینک “Verify email address” کلیک کنید تا به سایت برگردید.
- در مرحله بعد، نام و تاریخ تولد خود را وارد کنید (بهتر است سن بالای ۱۸ سال باشد!).
بخش سوم: حفظ حساب کاربری؛ نکات امنیتی حیاتی
دسترسی به ChatGPT به پایان نرسیده است. برای جلوگیری از مسدود شدن حساب که متأسفانه برای بسیاری از کاربران ایرانی رخ میدهد، نکات زیر را جدی بگیرید:
- ثبات جغرافیایی: همیشه برای ورود به حساب خود از IP همان کشوری که با آن ثبت نام کردهاید، استفاده کنید. تغییر مکرر کشور، زنگ خطر را برای OpenAI به صدا در میآورد.
- پرهیز از ورود اطلاعات داخل ایران: از وارد کردن هرگونه شماره تلفن یا آدرس ایران در بخش تنظیمات حساب کاربری خود پرهیز کنید. متاسفانه حسابهای داخل ایران بدلیل تحریمهای مغایر با حقوق بشر بسته میشوند.
- خروج امن: در صورت نیاز به استفاده از ابزارهای تغییر IP مختلف، حتماً قبل از تغییر، از حساب کاربری خود خارج (Log out) شوید.
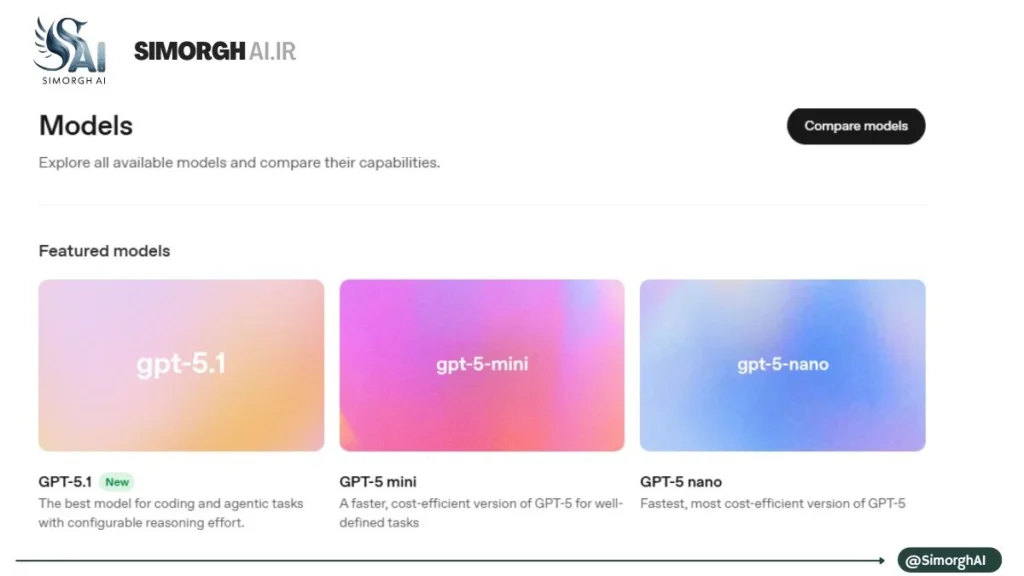
معرفی و تحلیل فنی مدلهای موجود چتجیپیتی (راهنمای انتخاب برای توسعهدهندگان و سازمانها)
در این گزارش مروری منظم و فنی بر مجموعه مدلهای مطرح ارائهشده در مستندات و فهرستهای عمومیِ ارائهدهندگان مطرح (با تمرکز بر فهرست مدلهای OpenAI که نمونهای نماینده است) ارائه میشود. هدف این متن، توضیح دستهبندیها، مزایا و محدودیتهای هر گروه مدل، و ارائه قواعد عملی برای انتخاب مدل مناسب براساس نیازهای واقعی محصول یا پروژه است. نکات فنی و توصیفی در متن تا حد امکان مبتنی بر منابع رسمی و گزارشهای موثق گردآوری شده است.
۱. ساختار کلی و دستهبندی مدلها
در فهرست رسمی مدلها معمولاً گروهبندیهایی مشاهده میشود که کمک میکند مدل مناسب براساس سطح توانایی، هزینه و کارکرد انتخاب شود:
- Featured / Frontier (مدلهای پرچمدار و پیشنهادی): مدلهایی با بالاترین سطح توانایی برای کارهای پیچیده و «reasoning» (استدلال) و همچنین کارهای عاملمحور (agentic).
- نسخههای کوچک و میانرده (mini / nano / pro): نسخههایی با هزینه و تأخیر کمتر که برای وظایف مشخص و متعارف مناسباند.
- Open-weight (مدلهای با وزن و کد منبع باز): مدلهایی که تحت مجوزهای باز منتشر شده و امکان اجرا و تغییر محلی را فراهم میکنند.
- مدلهای تخصصی (image, audio, video, embeddings, moderation): مدلهایی طراحیشده برای تولید تصویر، تبدیل گفتار به متن، تولید ویدئو سینکشده، تولید امبدینگ و غیره.
- مدلهای زمان-واقعی و صوتی: برای ورودی/خروجی صوتی و سناریوهای realtime کاربرد دارند.
- نسخههای مورد استفاده در محصولات چتبات (ChatGPT models): نسخههایی که بهصورت داخلی در محصولات گفتگو محور استفاده میشوند و لزوماً برای استفاده API پیشنهاد نمیشوند.
۲. نکته کلیدی درباره سری GPT-5.x (مثال: GPT-5.1)
نسل اخیر پرچمدارها (مثلاً GPT-5.1) بهصورت رسمی بهعنوان مدلهایی معرفی شدهاند که قابلیت «قابل پیکربندی بودن شدتِ استدلال» (configurable reasoning effort) را ارائه میدهند؛ بهعبارتی سیستم میتواند بین حالتهای «فکر سریع» و «فکر عمیق» انتخاب کند تا برای کارهای کدنویسی یا وظایف عاملمحور (agentic) نتیجه مطلوبتری بدهد. این خانواده همچنین نسخههای «mini» و «nano» را برای رسیدن به تعادل هزینه/سرعت عرضه میکند که برای وظایف معلوم و با حجم کمتر مناسبتر است. توصیه مرجع رسمی به استفاده از آخرین نسخه پرچمدار در بسیاری از کاربردهای پیچیده دیده میشود.
۳. مدلهای Open-weight و پیامدهای فنی و حقوقی
در گام مؤخر، عرضه مدلهای متن-محور با وزن باز (open-weight) که تحت مجوزهای باز مانند Apache 2.0 منتشر میشوند، تحول مهمی در اکوسیستم ایجاد کرده است. این مدلها امکان اجرا روی سختافزار محلی (از جمله GPUهای مصرفی یا حتی برخی تراشههای موبایل/سنسوری) و سفارشیسازی عمیق را فراهم میکنند؛ امتیازی که برای سازمانهایی که به حفظ حریم خصوصی، کاهش هزینههای ابری یا نیاز به تغییرات مدل روی دادههای خاص خود دارند، حیاتی است. همزمان، انتشار open-weight نیاز به توجه ویژه به ریسکهای سوءاستفاده و مسئولیتپذیری (safety) را افزایش میدهد و معمولاً با بستههای مستندسازی و ابزارهای سیاستگذاری همراه است.
۴. مدلهای تخصصی رسانه (تصویر، صدا، و ویدئو)
برای تولید تصویر و رسانه، مدلهایی مانند «GPT Image 1» یا راهکارهای اختصاصی تولید ویدئو با همگامسازی صوت (مثلاً Sora 2 / Sora 2 Pro در فهرست مدلها) معرفی شدهاند که هدفِ تولید محتوای غنی چندرسانهای را دنبال میکنند. این مدلها از منظر مهندسی به منابع پردازشی، فرایندهای پسپردازش و متادیتای تولید نیاز دارند و معمولاً هزینه و پیچیدگیِ فنی بالاتری نسبت به تولید متن دارند. هنگام انتخاب مدل رسانهای باید کیفیت خروجی، قابلیت کنترل (determinism / seedability)، مصرف منابع و پشتیبانی از سینک صوتی-تصویر را مد نظر قرار داد.
۵. معیارهای تصمیمگیری برای انتخاب مدل (چارچوب عملی)
برای انتخاب مدل مناسب، پیشنهاد میشود چارچوب تصمیمگیری زیر را دنبال کنید:
- هدف وظیفه (Use case): آیا نیاز به استدلال پیچیده و کدنویسی دارید یا فقط طبقهبندی، خلاصهسازی و استخراج اطلاعات؟ (کدنویسی/agentic → مدلهای Frontier مانند GPT-5.1؛ خلاصه/طبقهبندی → nano/mini).
- محدودیتهای تأخیر و هزینه: اگر نیاز به پاسخ سریع و ارزان دارید، نسخههای nano/mini یا مدلهای realtime-mini مناسباند.
- حجم متن و پنجرهی متنی (context window): برای اسناد بلند یا پیوستهای بزرگ، از مدلهایی با پنجرهٔ توکنی بزرگ استفاده کنید.
- مدالیتی (متن/تصویر/صدا/ویدئو): اگر ورودی یا خروجی چندرسانهای لازم دارید، مدل تخصصی مربوطه (image, audio, video) را انتخاب کنید.
- کنترلپذیری و قابلیت استدلال: برای کارهایی که خطا هزینه زیادی دارد (پزشکی، حقوقی، امنیت)، مدلهایی با قابلیت استدلال بهتر و سیستمهای ایمنسازی (safety system cards) یا ابزارهای sandboxing پیشنهاد میشوند.
- ملاحظات حفظ حریم خصوصی و اجرا محلی: اگر نمیخواهید دادهها از زیرساخت شما خارج شوند، انتخاب مدل open-weight و اجرا روی سرور/سختافزار محلی منطقی است.
۶. ملاحظات عملی و محدودیتها (خلاصه)
- توهم (hallucination): حتی در مدلهای پیشرفته احتمال تولید پاسخهای ناصحیح وجود دارد؛ برای کاربردهای حیاتی باید لایهٔ اعتبارسنجی خارجی طراحی شود.
- هزینه و مصرف انرژی: مدلهای پرقدرت هزینهٔ بالایی در هر درخواست یا در زمان استنتاج دارند؛ برای مقیاسپذیری باید استراتژیهای کشینگ، سرویسدهی آسنکرون یا لایهبندی مدلها در نظر گرفته شود.
- بحران بهروزرسانی دانش: مدلهایی که به منابع زنده متصل نیستند، بهروزرسانی منظمی نیاز دارند تا اطلاعاتشان منسوخ نشود.
- ریسکهای امنیتی و اخلاقی: انتشار کد/مدلهای باز و سرویسدهی مدلهای پرتوان ریسکهای جدیدی در حوزهٔ سوءاستفاده فراهم میکند که نیازمند سیاستهای عملیاتی و فنی است.
۷. پیشنهادات اجرایی برای تیمهای فنی و تحریریههای خبری
- برای نمونهسازی و توسعه اولیه: از نسخههای mini/nano یا مدلهای متن-محور open-weight (برای اجرا محلی) استفاده کنید تا هزینهٔ آزمایش کاهش یابد.
- برای محصول نهایی یا مأموریتهای حساس: مدل Frontier پرچمدار (مثلاً GPT-5.1 یا پیکربندی pro) را در محیط کنترلشده با لاگینگ، اعتبارسنجی خروجی و مکانیزمهای مدیریت ریسک پیاده کنید.
- ترکیب مدلها: بهجای تکیه صرف بر یک مدل، معماری چندلایه (مثلاً پیشپردازش با مدل سبک → استنتاج با مدل قوی → اعتبارسنجی با مدل تخصصی) هزینه را کاهش و اعتمادپذیری را افزایش میدهد.
- مستندسازی و شفافیت: برای هر تصمیم مهندسی دربارهٔ مدل (نسخه، تنظیمات reasoning، دسترسی شبکه) مستنداتی تهیه کنید تا پیگیری و بازبینی ممکن باشد.
تحلیل فنی و جامع مدل GPT-5.1 — نسل جدید معماری استدلالمحور OpenAI
مدل GPT-5.1 تازهترین و پیشرفتهترین مدل OpenAI در حوزه پردازش زبان و انجام وظایف استدلالی و عاملیتی (Agentic Tasks) است. این مدل نسخه ارتقاءیافته GPT-5 محسوب میشود و تمرکز اصلی آن بر بهبود توان استدلال، دقت در اجرای وظایف پیچیده، و عملکرد پایدار در پروژههای بزرگ است؛ بهویژه در سناریوهای کدنویسی، تحلیلهای لایهبهلایه و تصمیمگیری چندمرحلهای.
GPT-5.1 در دسته Frontier Models قرار دارد؛ یعنی مدلهایی که بهعنوان خطمقدم تواناییهای معماری LLM شناخته میشوند و برای بیشترین گسترهٔ کاربردهای سازمانی توصیه میشوند.
ویژگیهای کلیدی GPT-5.1
۱. تمرکز بر استدلال (Reasoning) با قابلیت تنظیم شدت
GPT-5.1 امکان انتخاب سطح استدلال را در اختیار توسعهدهنده قرار میدهد.
این قابلیت باعث میشود بتوان بین سرعت، هزینه و کیفیت توازن ایجاد کرد — موضوعی که برای پروژههای سازمانی و اپلیکیشنهای مقیاسپذیر اهمیت حیاتی دارد.
۲. سرعت بالا با هزینه بهینه
با وجود اینکه GPT-5.1 یک مدل بسیار توانمند است، سرعت پاسخدهی آن در سطح مدلهای سبکتر باقی مانده است.
- Input tokens: 1.۲۵ دلار به ازای هر 1M
- Cached input: تنها ۰.۱۲۵ دلار
- Output tokens: 10 دلار
ترکیب پشتیبانی از کش ورودی با توان استدلالی بالا، GPT-5.1 را برای اپلیکیشنهای تعاملی یا محصولات SaaS بهشدت بهصرفه میکند.
۳. پشتیبانی از ورودیهای چندوجهی
- متن: ورودی/خروجی
- تصویر: ورودی
- صوت و ویدئو: پشتیبانی نمیشود (برخلاف مدلهای خانواده 4o)
این مدل عمدتاً برای وظایف تحلیلی، پردازشی و محاسباتی طراحی شده، نه تولید صوت یا ویدئو.
۴. پنجرهٔ کانتکست گسترده
GPT-5.1 دارای:
- Context window: 400,000 tokens
- حداکثر خروجی: ۱۲۸,۰۰۰ tokens
این ظرفیت، اجرای پروژههایی مانند تحلیل کدهای چندماژولی، بررسی اسناد سازمانی، تحقیقات بلندمدت، و تولید گزارشهای حجیم را بدون نیاز به chunking ممکن میسازد.
۵. پشتیبانی گسترده از APIهای OpenAI
GPT-5.1 در اغلب نقاط ورودی/خروجی اکوسیستم OpenAI حضور دارد:
- Chat Completions
- Responses
- Realtime
- Assistants
- Batch
- Embeddings
- Image Generations
- Audio Speech
- Moderation
و غیره.
برای توسعهدهندگانی که بهدنبال ادغام مدل در محصولات هستند، این گستردگی یک مزیت مهم محسوب میشود.
کاربردهای ایدهآل GPT-5.1
GPT-5.1 بیشترین بهرهوری را در حوزههای زیر دارد:
۱. توسعه نرمافزار و Agent Development
- تولید کد قابلاجرا
- خطایابی پیشرفته
- تولید عاملهای خودمختار سازمانی
- تحلیل معماری نرمافزار
- Refactoring ماژولهای بزرگ
این مدل نسخهٔ Codex-محور نیز دارد (GPT-5.1 Codex) که برای توسعهدهندگان طراحی شده است.
۲. تصمیمگیری چندمرحلهای (Multi-step Reasoning)
برای پروژههایی که نیازمند تحلیل استنتاجی، برنامهریزی و تفکر لایهبهلایه هستند، GPT-5.1 بهترین گزینهٔ موجود از OpenAI است.
۳. تولید محتوای دقیق سازمانی
بهدلیل توان استدلالی بالا، مدل میتواند اسناد تحلیلی، گزارشهای سازمانی، پیشنهادهای فنی، و محتوای ساختیافته و دقیق تولید کند.
۴. کاربردهای API-محور با نیاز به سرعت بالا
با وجود قدرتمند بودن، GPT-5.1 هنوز سرعت مشابه مدلهای سبکتر را دارد.
این ویژگی باعث میشود برای اپلیکیشنهای دسته زیر مناسب باشد:
- چتباتهای پیشرفته
- سیستمهای تحلیل بلادرنگ
- اتوماسیونهای سازمانی
- ابزارهای پردازش داده
محدودیتها و نکات فنی
- قابل Fine-tune شدن نیست
برای آندسته از سازمانهایی که نیاز به مدل اختصاصی دارند، این محدودیت باید در نظر گرفته شود. - فقط متن و تصویر را پشتیبانی میکند
اگر نیاز به صوت، ویدئو یا پردازش چندوجهی کامل باشد، مدلهای خانواده 4o یا Sora مناسبتر هستند. - هزینه خروجی نسبت به مدلهای سبکتر بالاتر است
Output token قیمت قابلتوجهی دارد، بنابراین استفاده غیربهینه میتواند هزینه را افزایش دهد.
Rate Limits و Tierهای دسترسی
برای کاربران API، سقف مجاز در هر Tier اهمیت زیادی دارد.
| Tier | RPM | TPM | Batch Queue |
|---|---|---|---|
| ۱ | ۵۰۰ | ۵۰۰,۰۰۰ | ۱,۵۰۰,۰۰۰ |
| ۲ | ۵,۰۰۰ | ۱,۰۰۰,۰۰۰ | ۳,۰۰۰,۰۰۰ |
| ۳ | ۵,۰۰۰ | ۲,۰۰۰,۰۰۰ | 100M |
| ۴ | ۱۰,۰۰۰ | ۴,۰۰۰,۰۰۰ | 200M |
| ۵ | ۱۵,۰۰۰ | ۴۰,۰۰۰,۰۰۰ | 15B |
این مقادیر GPT-5.1 را برای پروژههای سازمانی بزرگ و سامانههایی که نیاز به پردازش حجیم دارند به گزینهای مناسب تبدیل میکند.
جمعبندی
GPT-5.1 نهتنها قدرتمندترین مدل استدلالمحور OpenAI محسوب میشود، بلکه ترکیب تعادل سرعت، توان استنتاجی، قابلیت تنظیم Reasoning، و پشتیبانی گسترده از APIهای سازمانی باعث شده این مدل به گزینهٔ اصلی شرکتها، تیمهای توسعه نرمافزار و پژوهشگران تبدیل شود.
اگر هدف یک محصول یا سرویس هوشمند است که نیازمند تحلیل دقیق، تولید پاسخ قابلاعتماد، و انعطاف در سطح استدلال باشد، GPT-5.1 در حال حاضر بهترین انتخاب در اکوسیستم OpenAI است.
منبع: اُپن ای آی