
 چیست؟ از صفر تا صد")
جدول محتواها
۱. مقدمه: چرا RAG؟ انقلابی در مدلهای زبانی بزرگ
مدلهای زبانی بزرگ (LLM) با قابلیتهای شگفتانگیز خود در تولید متن، به سرعت به یکی از تأثیرگذارترین فناوریهای هوش مصنوعی تبدیل شدهاند. با این حال، استفاده از این مدلها به تنهایی با چالشهای اساسی و قابل توجهی همراه است که مانع از کاربرد آنها در بسیاری از سناریوهای حساس و حوزهمحور میشود. این چالشها شامل ارائه پاسخهای نادرست و غیرواقعی (توهم)، محدودیت دانش به دلیل تاریخ آموزش، و عدم توانایی در دسترسی به اطلاعات خصوصی یا اختصاصی سازمانها است.۱
برای غلبه بر این محدودیتها، رویکردی نوآورانه به نام «تولیدمجهز به بازیابی» یا Retrieval-Augmented Generation (RAG) معرفی شد. RAG در اصل یک چارچوب هوش مصنوعی است که نقاط قوت مدلهای مبتنی بر بازیابی اطلاعات سنتی (مانند جستجو در پایگاههای داده) را با قابلیتهای تولیدی LLMها ترکیب میکند.۱ این رویکرد به عنوان یک پل ارتباطی عمل میکند که دانش ذخیرهشده در پایگاههای داده خارجی و قدرت تولید متن LLMها را به هم پیوند میدهد.۲ به زبان ساده، RAG فرآیند بهینهسازی خروجی یک مدل زبانی بزرگ است، به طوری که مدل قبل از تولید پاسخ، به یک پایگاه دانش معتبر خارج از دادههای آموزشی خود مراجعه میکند.
تاریخچه RAG به مقاله کلیدی سال ۲۰۲۰ با عنوان “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” نوشته پاتریک لوئیس و همکارانش در متا هوش مصنوعی بازمیگردد. این مقاله، RAG را به عنوان یک رویکرد جامع معرفی کرد که حافظه پارامتریک (LLM از پیشآموزشدیده) را با حافظه غیرپارامتریک (مانند یک پایگاه داده برداری از ویکیپدیا) ترکیب میکند تا خروجیهای دقیقتر و بهروزتری تولید کند.۶ این پژوهش یک تغییر پارادایم در معماری هوش مصنوعی مولد ایجاد کرد و مدلهای زبانی را از یک سیستم دانش ایستا و بسته به یک سیستم دانش پویا و باز تبدیل نمود.۸ این تحول، LLMها را از یک ابزار عمومی به یک راهحل قابل تنظیم و کاربردی برای محیطهای سازمانی تبدیل کرد. پیش از RAG، سازمانها برای معرفی اطلاعات اختصاصی خود به مدلها، مجبور بودند مدلهای پایه را مجدداً آموزش دهند (fine-tuning)، که فرآیندی بسیار پرهزینه، زمانبر و نیازمند منابع محاسباتی عظیم بود. RAG این مشکل را با ارائه یک راهکار مقرونبهصرفه حل کرد و به سازمانها اجازه داد تا از قدرت LLMها برای دادههای داخلی و بهروز خود استفاده کنند، بدون نیاز به سرمایهگذاریهای سنگین اولیه.۴ این ویژگی، RAG را به یک فناوری «دموکراتیزهکننده» تبدیل کرده است که هوش مصنوعی مولد را برای طیف وسیعتری از کسبوکارها قابل دسترس و کاربردی میسازد.
۲. معماری و اجزای اصلی RAG
سیستم RAG برای تولید یک پاسخ منسجم و دقیق، یک خط لوله پردازشی چندمرحلهای را دنبال میکند. این فرآیند پیچیده به طور کلی به دو فاز اصلی تقسیم میشود: فاز ایندکسسازی دادهها (Data Indexing) که در آن پایگاه دانش خارجی آمادهسازی میشود، و فاز بازیابی و تولید (Retrieval and Generation) که در آن پاسخ نهایی به پرسش کاربر ساخته میشود.
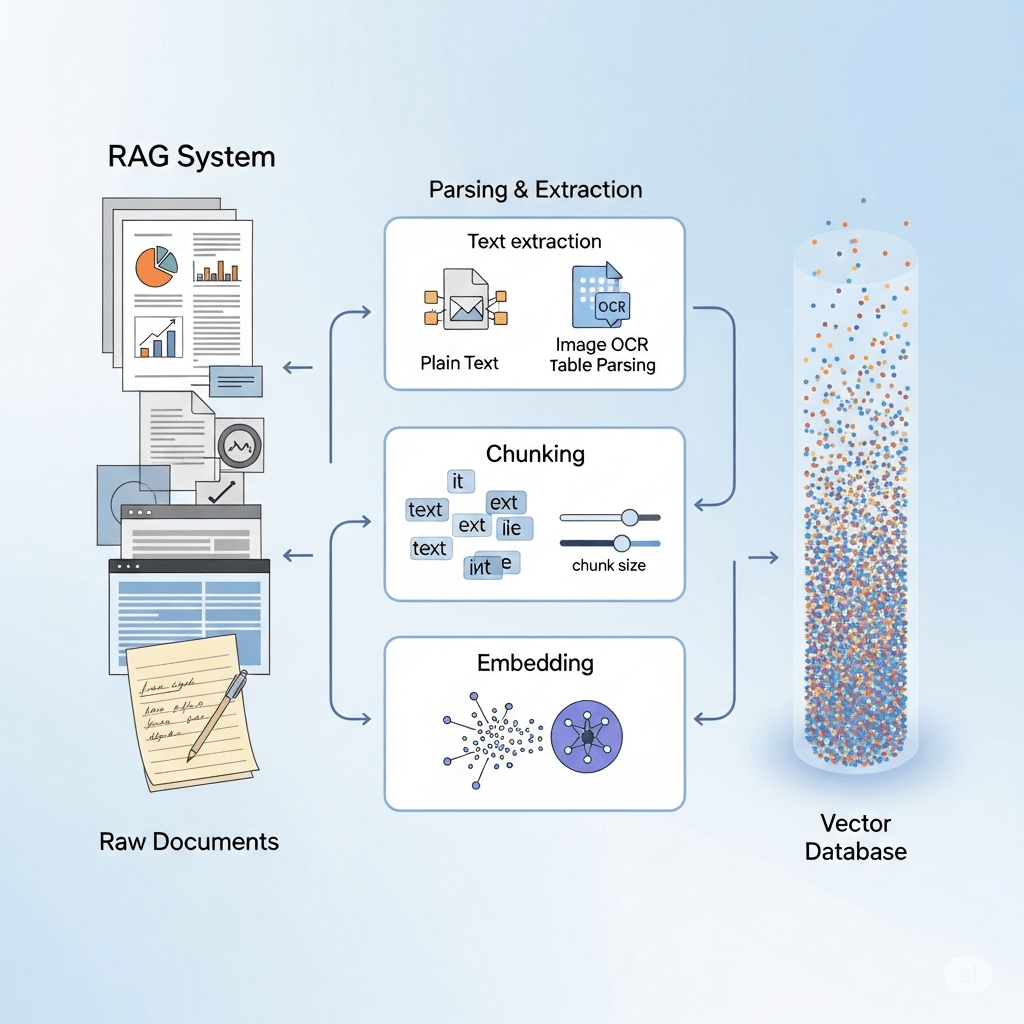
۲.۱. فاز ایندکسسازی: آمادهسازی پایگاه دانش
فاز ایندکسسازی که به عنوان مرحله اولیه و حیاتی در پیادهسازی RAG شناخته میشود، شامل چندین گام است که هدف آن تبدیل دادههای خام به یک فرمت قابل جستجو برای LLM است. این فرآیند از بارگذاری دادهها (Data Loading) آغاز میشود که در آن دادههای خام از منابع مختلف مانند پایگاههای داده، اسناد PDF، APIها، و صفحات وب جمعآوری میشوند.۴ پس از بارگذاری، دادهها وارد مرحله
استخراج و تبدیل (Extraction and Transformation) میشوند. در این گام، به ویژه برای دادههای بدون ساختار، متن طبیعی استخراج شده و به فرمتی سازگار تبدیل میشود تا برای پردازشهای بعدی آماده شود.۱۰
گام کلیدی بعدی، تقسیمبندی (Chunking) است. در این مرحله، اسناد یا متون بزرگ به قطعات (chunks) کوچکتر و قابل مدیریت تقسیم میشوند. این تقسیمبندی به دو دلیل حیاتی است: اولاً، بازیابی اطلاعات را دقیقتر میکند، زیرا به سیستم اجازه میدهد تا تنها بخشهای بسیار مرتبط از یک سند را شناسایی و به LLM ارسال کند. ثانیاً، از آنجایی که اکثر LLMها دارای پنجره متنی (context window) محدودی هستند، ارسال تنها قطعات مرتبط به کاهش هزینههای محاسباتی و زمانی کمک میکند.۵ در نهایت، هر قطعه متن با استفاده از یک
مدل جاسازی (Embedding Model) به یک نمایش عددی یا بردار تبدیل میشود. این بردارها در یک پایگاه داده برداری (Vector Database) ذخیره میشوند که به طور خاص برای جستجوی سریع بر اساس شباهت معنایی طراحی شدهاند.۴ این پایگاه دادهها، اساس عملکرد RAG را تشکیل میدهند.
۲.۲. فاز بازیابی و تولید: پاسخ به پرسش کاربر
این فاز، فرآیند اصلی پاسخدهی به پرسش کاربر را در بر میگیرد. با دریافت پرسش، سیستم RAG به دو جزء اصلی خود، یعنی بازیاب (Retriever) و تولیدکننده (Generator)، تکیه میکند.
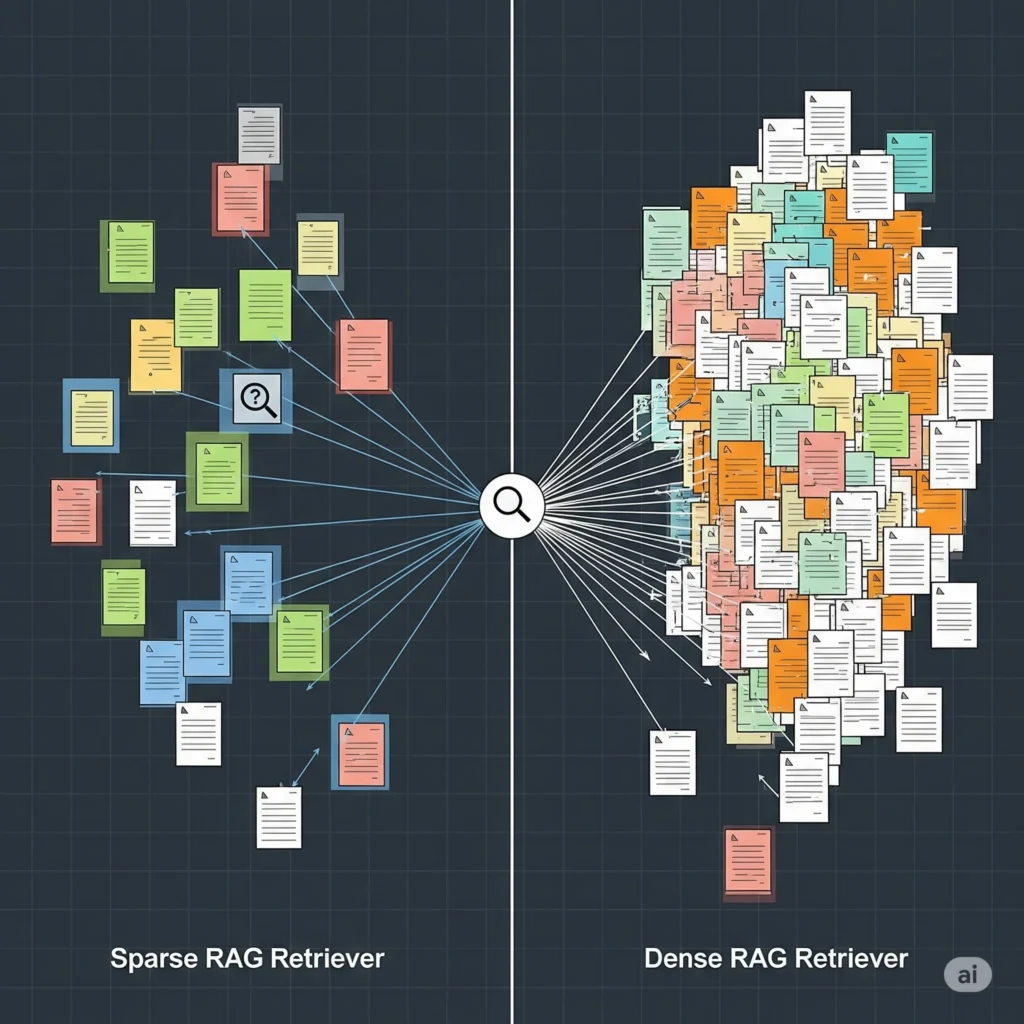
نقش بازیاب و انواع آن
بازیاب، مسئول یافتن مرتبطترین قطعات اطلاعاتی از پایگاه دانش در پاسخ به یک پرسش است.۱۲ عملکرد آن به عنوان موتور موفقیت سیستم RAG شناخته میشود؛ چرا که بدون یک بازیاب مؤثر، حتی پیشرفتهترین LLM نیز نمیتواند پاسخهای دقیق ارائه دهد.۱۳ به عنوان مثال، اگر بازیاب برای یک پرسش در مورد “فیزیک کوانتوم” یک “کتاب آشپزی” را بازیابی کند، پاسخ نهایی به طور حتم نادرست خواهد بود.۱۴
بازیابها به دو دسته اصلی تقسیم میشوند:
- بازیابهای پراکنده (Sparse Retrievers): این بازیابها بر تطابق لغوی و کلمات کلیدی متکی هستند.۱۳ الگوریتمهایی مانند TF-IDF (Term Frequency-Inverse Document Frequency) و BM25 از این دسته هستند.۱۳ این روشها ساده و قابل تفسیرند و برای دادههای حوزهمحور که تطابق دقیق واژهها حیاتی است، مؤثر عمل میکنند. با این حال، در درک مترادفها و شباهتهای معنایی (مانند درک رابطه بین “خودرو” و “اتومبیل”) با محدودیت روبرو هستند.۱۳
- بازیابهای متراکم (Dense Retrievers): این بازیابها از جاسازیها و شبکههای عصبی برای انجام تطابق معنایی استفاده میکنند. سیستمهایی مانند DPR (Dense Passage Retrieval) از نمونههای برجسته این دسته هستند.۱۳ بازیابهای متراکم با تبدیل پرسش و اسناد به بردارهای متراکم، قادرند شباهت معنایی را درک کنند و در مجموعههای داده بزرگ و متنوع عملکرد بهتری دارند. با این حال، پیادهسازی و آموزش آنها از نظر محاسباتی پرهزینه است.۱۳
انتخاب بین این دو نوع بازیاب یک تصمیم استراتژیک است که به ماهیت دادهها بستگی دارد. به عنوان مثال، در جستجوی اسناد حقوقی یا پزشکی که نیاز به دقت در اصطلاحات دارد، بازیابهای پراکنده ممکن است گزینهای مناسب باشند، در حالی که در چتباتهای خدمات مشتری که باید قصد کاربر را درک کنند، بازیابهای متراکم ضروریترند.۱۵ سیستمهای پیشرفتهتر اغلب از
جستجوی ترکیبی (Hybrid Search) استفاده میکنند که مزایای هر دو رویکرد معنایی و کلمه کلیدی را با هم ترکیب میکند.۱
نقش تولیدکننده و نسلسازی
پس از آنکه بازیاب، مرتبطترین اسناد را شناسایی کرد، نوبت به تولیدکننده میرسد.۱۲ تولیدکننده که معمولاً یک LLM است، پرسش اصلی کاربر و دادههای بازیابیشده را به عنوان ورودی دریافت میکند. این مدل با استفاده از مهارتهای تولیدی خود، پاسخی منسجم، دقیق و قابل فهم ایجاد میکند. این فرآیند به عنوان
نسلسازی مبتنی بر واقعیت (Grounded Generation) شناخته میشود، زیرا تضمین میکند که خروجی مدل کاملاً بر اساس حقایق موجود در اسناد بازیابیشده بنا شده است.۱ در این مرحله،
مهندسی پرامپت (Prompt Engineering) نقش حیاتی ایفا میکند؛ دادههای بازیابیشده به صورت دقیق به پرامپت کاربر اضافه میشود تا یک پرامپت «افزوده» ایجاد شود که به LLM کمک میکند پاسخ دقیقتری ارائه دهد.۴
جدول ۱: نمای شماتیک خط لوله RAG
| فاز ۱: ایندکسسازی (Indexing) | فاز ۲: بازیابی و تولید (Retrieval & Generation) |
| دادههای خام | ◀────────── |
| بارگذاری، تبدیل، تقسیمبندی | ◀────────── |
| جاسازی (Embedding) | ◀────────── |
| پایگاه داده برداری (Vector Database) | ◀────────── |
| ورودی کاربر | ▶────────── |
| بازیابی (Retrieval) | ▶────────── |
| افزودن (Augmentation) | ▶────────── |
| تولید (Generation) | ▶────────── |
| پاسخ نهایی | ▶────────── |
این خط لوله نشان میدهد که کیفیت خروجی RAG به طور مستقیم به کیفیت هر مرحله از این فرآیند وابسته است. یک مدل زبانی قدرتمند به تنهایی نمیتواند ضعف در مراحل ایندکسسازی یا بازیابی را جبران کند.
۳. مزایا و چالشهای RAG
RAG با ارائه یک راهکار کارآمد، مزایای متعددی را در مقابل روشهای سنتی تولید متن و مدلهای زبانی پایه به ارمغان میآورد. با این حال، پیادهسازی و نگهداری آن نیز با چالشهایی همراه است که باید به دقت مورد توجه قرار گیرد.
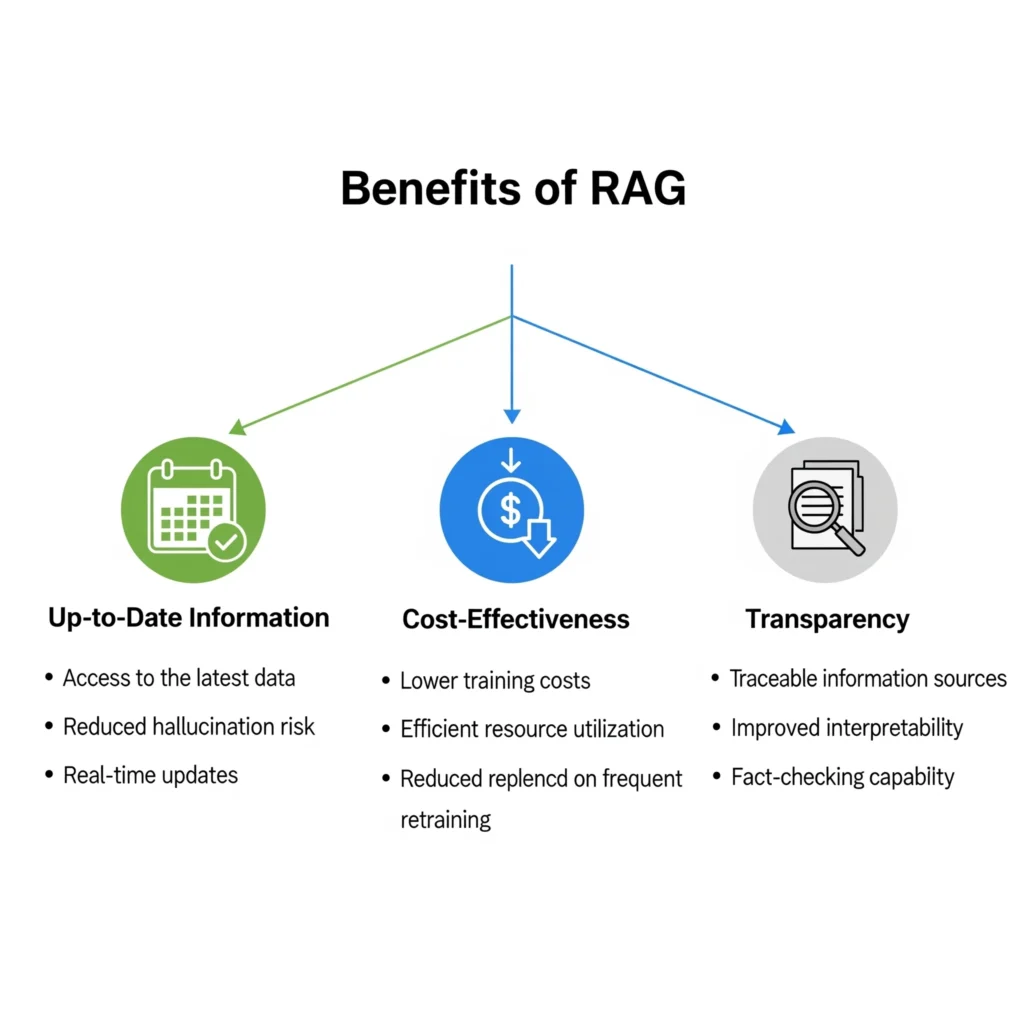
۳.۱. مزایای کلیدی
- افزایش دقت و واقعگرایی: RAG با فراهم کردن “حقایق” به عنوان بخشی از ورودی مدل، به طور قابل توجهی توهمات هوش مصنوعی را کاهش میدهد.۱ این رویکرد تضمین میکند که خروجی مدل بر اساس اطلاعات موثق و قابل استناد تولید شود، که به ویژه در کاربردهای حوزهمحور حیاتی است.
- دسترسی به اطلاعات بهروز و اختصاصی: LLMهای پایه به دادههایی که در زمان آموزش آنها وجود داشته، محدود هستند. RAG با اتصال به منابع خارجی مانند پایگاههای دانش سازمانی، فیدهای خبری زنده یا اسناد خصوصی، این محدودیت را برطرف میکند و به مدل امکان دسترسی به جدیدترین اطلاعات را میدهد.۳ این قابلیت به سازمانها اجازه میدهد تا از LLMها برای دادههای محرمانه و اختصاصی خود استفاده کنند، بدون اینکه نیاز به آموزش مجدد مدل باشد.۲
- مقرونبهصرفه بودن: آموزش مجدد یک مدل پایه برای تطبیق با یک حوزه خاص، فرآیندی بسیار پرهزینه و نیازمند منابع محاسباتی عظیم است.۴ RAG یک رویکرد جایگزین و مقرونبهصرفه برای معرفی دادههای جدید به LLM است و فناوری هوش مصنوعی مولد را در دسترستر و قابل استفادهتر میکند.۴
- شفافیت و قابلیت ارجاع به منبع: یکی از مزایای مهم RAG، قابلیت ارائه ارجاع به منابع (Citations) است. خروجی مدل میتواند شامل ارجاعاتی به اسناد منبع باشد، که به کاربر امکان میدهد صحت اطلاعات را بررسی کند و به پاسخهای تولیدی اعتماد بیشتری داشته باشد.۴ این ویژگی همچنین فرآیند عیبیابی را برای توسعهدهندگان آسانتر میکند.۱۵
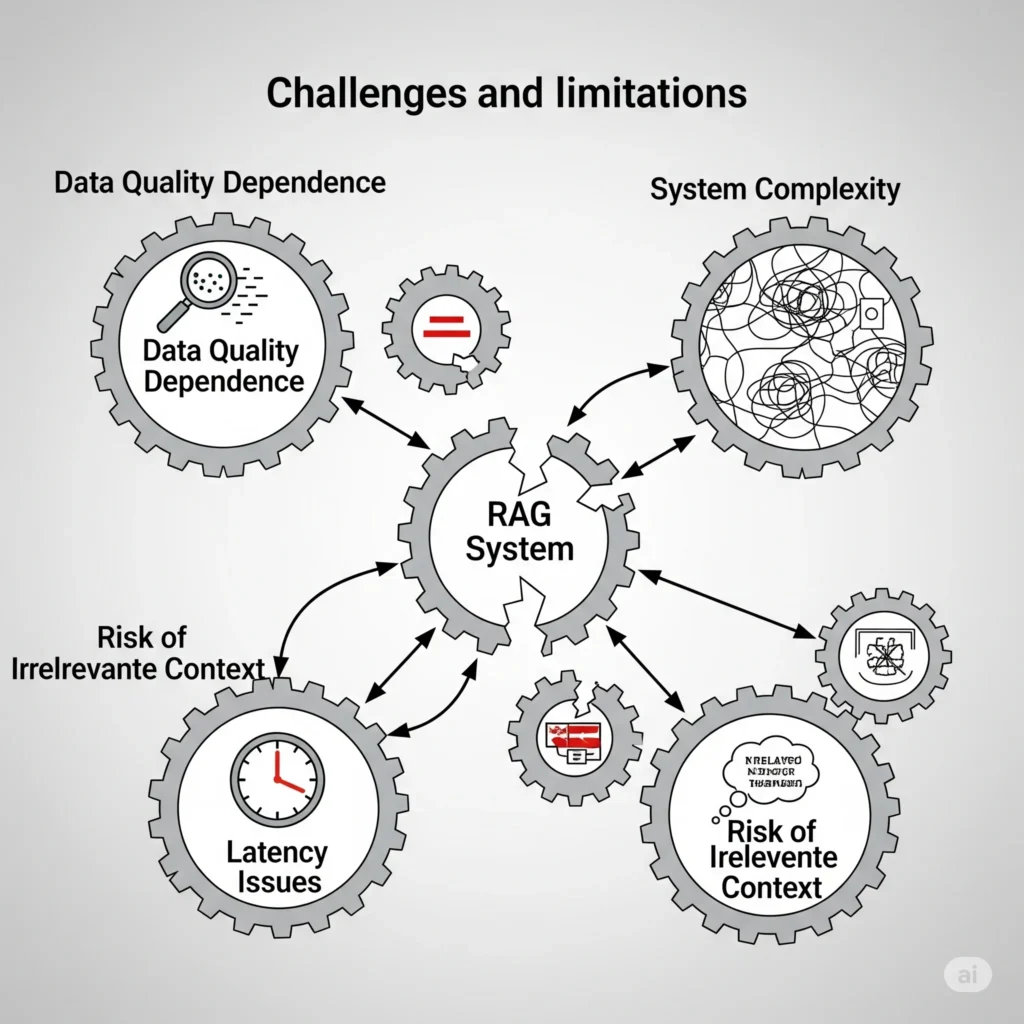
۳.۲. چالشها و محدودیتها
- وابستگی به کیفیت دادههای خارجی: خروجی RAG تنها به اندازه دادههایی که به آن دسترسی دارد، دقیق است. اگر پایگاه دانش شامل اطلاعات نادرست، قدیمی یا مغرضانه باشد، خروجی مدل نیز چنین خواهد بود.۱۴ اصل “Garbage in, garbage out” (آشغال وارد کنی، آشغال تحویل میگیری) در اینجا به شدت صدق میکند.
- پیچیدگی و سربار نگهداری سیستم: RAG شامل اجزای متعددی از جمله ایندکسسازی، پایگاه داده برداری، بازیابی و نسلسازی است. این معماری پیچیده، سربار نگهداری بیشتری را نسبت به LLMهای سنتی به همراه دارد.۱۱ این موضوع میتواند برای سازمانهای کوچکتر با منابع محدود، یک مانع جدی باشد. در حالی که RAG هزینههای آموزش و توسعه را به شدت کاهش میدهد، هزینههای عملیاتی و نگهداری را به دلیل نیاز به مدیریت مداوم خطوط لوله داده و نظارت بر عملکرد سیستم افزایش میدهد.
- تأخیر زمانی (Latency): خط لوله RAG به دلیل مراحل اضافی مانند بازیابی بردارها، رتبهبندی مجدد و مهندسی پرامپت، تأخیر بیشتری در پاسخدهی نسبت به LLMهای ساده ایجاد میکند. این مسئله در سیستمهایی که نیاز به پاسخ بلادرنگ دارند، چالشبرانگیز است.۱۱
- خطر سوگیری یا زمینه نامربوط: سیستم بازیابی ممکن است به دلیل کیفیت پایین دادهها یا پرسشهای مبهم، اسناد نامربوطی را بازیابی کند.۱۴ این امر میتواند منجر به پاسخهای نادرست یا گمراهکننده شود، حتی اگر مدل به درستی عمل کند.
۴. مدیریت و کاهش توهم در سیستمهای RAG
با وجود مزایای RAG در کاهش توهمات، این پدیده به طور کامل از بین نمیرود. در واقع، RAG ماهیت توهمات را تغییر میدهد؛ به طوری که توهمات در RAG کمتر ناشی از “ساختن اطلاعات” توسط مدل هستند و بیشتر به دلیل “استفاده نادرست از اطلاعات غلط یا نامربوط” توسط خط لوله اتفاق میافتند.۲۲
۴.۱. علل توهمزایی در RAG
- مشکلات بازیابی: بازیاب ممکن است اسنادی را بازیابی کند که از نظر موضوعی مرتبط، اما از نظر واقعی نادرست یا گمراهکننده هستند.۱۹ این امر باعث میشود مدل، اطلاعات نادرست را به عنوان واقعیت بپذیرد.
- مشکلات ترکیب (Fusion): حتی اگر اسناد بازیابیشده دقیق باشند، تولیدکننده ممکن است اطلاعات را به روشی گمراهکننده ترکیب کند یا نتیجهگیریهای نادرستی از آنها استخراج نماید.۲۲
- عدم تطابق اعتماد (Confidence Misalignment): مدلها ممکن است با وجود عدم وجود اطلاعات کافی در دادههای بازیابیشده، با اطمینان بالایی پاسخ تولید کنند، که این امر حس کاذب قابلیت اعتماد را به کاربر منتقل میکند.۲۲
۴.۲. استراتژیهای عملی برای توسعهدهندگان
- بهبود کیفیت دادهها: اولین و مهمترین گام، اطمینان از پاک بودن، بهروز بودن و مرتبط بودن دادهها در پایگاه دانش است.۲۲
- مهندسی پرامپت برای الزام به منبع: طراحی پرامپتهایی که به صراحت به مدل دستور میدهند که پاسخ خود را فقط بر اساس متن بازیابیشده بنا کند و از حدس و گمان خودداری نماید.۲۲
- سنجش واقعگرایی با معیارهای ارزیابی: استفاده از ابزارهایی مانند
BERTScoreیاFactCCبرای ارزیابی صحت و واقعگرایی پاسخهای تولیدشده.۲۲ - استفاده از مدلسازی عدم قطعیت: آموزش مدل برای تشخیص زمانی که پاسخ مناسبی در دادههای بازیابیشده وجود ندارد و در این موارد، گفتن “من نمیدانم”.۲۲
راهکار مقابله با توهم در RAG، نه در بهبود LLM، بلکه در بهبود کل خط لوله است. تمرکز باید بر روی بازیاب، کیفیت دادههای منبع، و تکنیکهای مهندسی پرامپت باشد که مدل را به پیروی دقیق از منابع الزام میکنند.
۵. تکنیکهای پیشرفته RAG: فراتر از RAG ساده
تکامل RAG از یک معماری ساده به رویکردهای پیشرفتهتر، نشاندهنده یک گرایش کلی در حوزه هوش مصنوعی است: حرکت به سمت سیستمهایی که نه تنها “پاسخ” میدهند، بلکه “استدلال” و “برنامهریزی” نیز میکنند.۲۳ در حالی که RAG ساده برای پرسشهای مستقیم و تکمرحلهای عالی است، در مواجهه با پرسشهای پیچیده که نیاز به استدلال یا ترکیب اطلاعات از چندین منبع دارند، با محدودیت روبرو میشود.۱۷ این محدودیتها به توسعه تکنیکهای پیشرفته زیر منجر شدهاند:
۵.۱. RAG-Fusion
این رویکرد، فراتر از بازیابی با یک پرسش واحد عمل میکند. ابتدا پرسش اصلی کاربر را به چندین پرسش فرعی یا بازنویسیشده تبدیل میکند.۲۵ سپس، برای هر یک از این پرسشها، بازیابی برداری انجام داده و مجموعهای از اسناد را جمعآوری میکند. در نهایت، با استفاده از الگوریتم
Reciprocal Rank Fusion (RRF)، نتایج را از منابع متعدد ترکیب و رتبهبندی مجدد میکند تا یک لیست نهایی یکپارچه و دقیقتر ارائه دهد.۲۵ این روش با بررسی یک پرسش از زوایای مختلف، دقت و جامعیت بازیابی را به شدت افزایش میدهد و قصد اصلی کاربر را بهتر درک میکند.۲۵ با این حال، به دلیل نیاز به چندین بار فراخوانی LLM و مراحل اضافی، به طور قابل توجهی کندتر از RAG ساده است و تأخیر بیشتری دارد.۲۵
۵.۲. Multi-hop RAG
این روش برای پاسخ به پرسشهای پیچیدهای طراحی شده است که نیاز به استدلال و جمعآوری اطلاعات از چندین منبع یا سند مختلف دارند.۲۴ سیستم Multi-hop RAG یک فرآیند زنجیرهای را آغاز میکند که در آن اطلاعات از یک سند بازیابی شده و به عنوان ورودی برای بازیابی اطلاعات از سند بعدی استفاده میشود تا در نهایت یک پاسخ منسجم و کامل تولید شود. این رویکرد، چالشهای موجود در پاسخ به پرسشهای چندمرحلهای را که RAG سنتی در آنها عملکرد نامطلوبی دارد، حل میکند.۲۴
۵.۳. Agentic RAG
Agentic RAG یک تکامل بزرگ از RAG سنتی است که از عاملهای هوش مصنوعی (AI Agents) برای تسهیل فرآیند استفاده میکند.۳۰ این عاملها دارای قابلیتهایی مانند حافظه، برنامهریزی گامبهگام، تصمیمگیری، و استفاده از ابزارهای خارجی (مانند APIها یا پایگاههای داده متعدد) هستند.۳۰
Agentic RAG میتواند پرسشهای پیچیده را به زیرپرسشها تقسیم کند، برای هر زیرپرسش ابزار مناسب را انتخاب کند و نتایج را برای تولید پاسخ نهایی ترکیب کند.۳۲ این رویکرد، RAG را از یک دستیار “منفعل” که فقط دادهها را بازیابی میکند، به یک “شریک فعال” تبدیل میکند که میتواند به طور مستقل تصمیمگیری و برنامهریزی کند.۲۳ در این معماریهای پیشرفته، LLM به یک “ابزار قدرتمند” در میان ابزارهای دیگر تبدیل میشود و هوش اصلی در نحوه هماهنگی و مدیریت فرآیند توسط عاملها نهفته است.
۵.۴. RAG چندوجهی (Multimodal RAG)
این رویکرد پیشرفته، سیستم RAG را قادر میسازد تا دادهها را فراتر از متن، از منابع چندوجهی مانند تصاویر، ویدیو، و صوت بازیابی و پردازش کند.۱ این قابلیت به سیستم اجازه میدهد تا ظرافتهایی را که در تحلیل صرفاً متنی از دست میروند، درک کرده و پاسخهای غنیتری ارائه دهد.
۶. کاربردهای صنعتی و مطالعات موردی
کاربردهای RAG در صنایع مختلف نشان میدهد که این فناوری یک ابزار استراتژیک برای حل مشکلات تجاری دنیای واقعی، به ویژه در حوزههایی است که دقت و بهروز بودن اطلاعات حیاتی است. RAG در تمامی کاربردهای زیر، یک مشکل کلیدی مشترک را حل میکند: مشکل “اطلاعات پراکنده و غیرقابل دسترسی”.
۶.۱. خدمات مشتریان و چتباتها
RAG به چتباتها امکان میدهد تا با دسترسی به مستندات و دادههای بهروز شرکت، پاسخهای دقیق و شخصیسازیشده ارائه دهند.۱۸ این امر زمان پاسخدهی را کاهش میدهد و رضایت مشتری را افزایش میدهد.
- مطالعه موردی: DoorDash: این شرکت از یک چتبات مبتنی بر RAG برای پشتیبانی از پیکهای خود استفاده میکند. این سیستم پرسشها را خلاصه میکند، از پایگاه دانش مربوطه جستجو کرده و پاسخی منسجم تولید میکند که به کاهش زمان حل مشکلات کمک میکند.۳۶
- مطالعه موردی: LinkedIn: از RAG با ترکیب یک گراف دانش برای پاسخ به سوالات خدمات مشتری استفاده میکند، که دقت بازیابی را افزایش داده و زمان حل مسئله را تا ۲۸.۶٪ کاهش داده است.۳۶
۶.۲. مراقبتهای بهداشتی و پزشکی
RAG به پزشکان امکان دسترسی به آخرین تحقیقات، دستورالعملهای بالینی و پروندههای پزشکی را میدهد، که این امر به تصمیمگیری بالینی دقیقتر کمک میکند.۱۵
- مثال: یک سیستم RAG میتواند به سوالات مربوط به بیماریهای پیچیده پاسخ دهد، اطلاعات مرتبط را از پایگاههای داده پزشکی بازیابی کرده و به پزشک کمک کند تا تشخیص و درمان دقیقتری ارائه دهد.۱۵
۶.۳. امور مالی و بانکی
RAG با تجزیه و تحلیل دادههای بلادرنگ بازار و گزارشها، به شرکتهای مالی در مدیریت ریسک و تحلیل احساسات بازار کمک میکند.۳۹
- مطالعه موردی: JPMorgan Chase: از RAG برای سیستمهای تشخیص تقلب استفاده میکند، جایی که مدل با مقایسه تراکنشها با الگوهای تقلب شناختهشده، رفتارهای مشکوک را شناسایی میکند.۳۵
۶.۴. مدیریت دانش سازمانی
RAG به کارمندان کمک میکند تا به سرعت و به زبان طبیعی به اطلاعات داخلی شرکت دسترسی پیدا کنند.۳ این سیستم میتواند اطلاعات پراکنده در فایلها، CRM و اسناد را به یک پایگاه دانش متمرکز و قابل جستجو تبدیل کند، که این امر بهرهوری را افزایش میدهد.
۷. مقایسه RAG با Fine-tuning و Prompt Engineering
انتخاب بین RAG، Fine-tuning و Prompt Engineering یک تصمیم استراتژیک است که به عوامل متعددی از جمله نوع داده (پویا در مقابل ایستا)، الزامات دقت (دقت حقایق در مقابل سبک و لحن) و منابع موجود (بودجه و تخصص) بستگی دارد. درک تفاوتهای این سه روش برای انتخاب رویکرد مناسب در هر پروژه ضروری است.
| معیار مقایسه | مهندسی پرامپت (Prompt Engineering) | آموزش مجدد (Fine-tuning) | نسلسازی با بازیابی افزوده (RAG) |
| رویکرد | بهینهسازی پرامپتهای ورودی برای هدایت مدل به سمت خروجی بهتر.۴۱ | آموزش یک مدل از پیش آموزشدیده بر روی یک مجموعه داده کوچک و متمرکز.۵ | اتصال LLM به یک پایگاه داده خارجی برای غنیسازی پرامپت با اطلاعات مرتبط.۴۱ |
| هدف اصلی | هدایت مدل به سمت نتایج مطلوب کاربر.۴۱ | بهبود عملکرد مدل در یک حوزه خاص یا با یک لحن مشخص.۹ | افزایش دقت و واقعگرایی با استفاده از اطلاعات خارجی و بهروز.۴۱ |
| الزامات منابع و هزینه | کمترین زمان و منابع را نیاز دارد، اغلب به صورت دستی.۴۱ | پرهزینهترین و زمانبرترین روش، نیازمند منابع محاسباتی قوی (GPU).۹ | هزینهای بینابین، نیازمند تخصص در علم داده برای ساخت خطوط لوله.۹ |
| نوع داده مناسب | دادههای متنوع و باز، برای تولید محتوای خلاقانه.۴۱ | دادههای برچسبگذاری شده و ثابت، برای آموزش اصطلاحات و لحن خاص.۹ | دادههای پویا، اختصاصی و بلادرنگ که به سرعت تغییر میکنند.۹ |
| کاربرد ایدهآل | تولید محتوای خلاقانه یا پاسخ به پرسشهای باز.۴۱ | آموزش مدل برای پیروی از یک سبک نگارشی، لحن یا اصطلاحات صنعتی خاص.۹ | چتباتهای خدمات مشتری، سیستمهای پرسش و پاسخ مبتنی بر مستندات داخلی.۴۱ |
| نقاط ضعف اصلی | دانش مدل را تغییر نمیدهد و نمیتواند به اطلاعات جدید دسترسی پیدا کند.۴۱ | پرهزینه، زمانبر، و برای دادههای در حال تغییر نامناسب.۹ | پیچیدگی معماری و سربار نگهداری سیستم، احتمال تأخیر زمانی.۱۶ |
این سه روش انحصاری نیستند و اغلب برای دستیابی به نتایج بهینه با هم ترکیب میشوند.۹ برای مثال، یک سازمان ممکن است از
Fine-tuning برای آموزش مدل بر روی لحن و ارزشهای سازمانی خود استفاده کند و سپس از RAG برای ارائه اطلاعات بهروز محصول به آن مدل بهره ببرد.
۸. آینده RAG: روندهای نوظهور
آینده RAG به سمت تبدیل شدن از یک “تکنیک” به یک “استاندارد معماری” در توسعه هوش مصنوعی مولد است. با تکامل فناوری و افزایش تقاضا، روندهای زیر شکل خواهند گرفت:
- استانداردسازی و دسترسپذیری بیشتر: با افزایش استانداردسازی الگوهای نرمافزاری زیربنایی، انتظار میرود راهحلها و کتابخانههای آماده بیشتری برای پیادهسازی RAG در دسترس قرار گیرد.۲۰ این امر، ساخت و استقرار سیستمهای RAG را برای توسعهدهندگان آسانتر خواهد کرد.
- مدلهای زبانی بهینهسازی شده برای RAG: مدلهای زبانی جدیدی در حال آموزش هستند که به طور خاص برای استفاده در سیستمهای RAG بهینهسازی شدهاند. این مدلها به جای اتکا به دانش پارامتریک داخلی، بر بازیابی سریع دادهها از مجموعههای بزرگ تمرکز دارند.۲۰
- ادغام عمیقتر با سیستمهای سازمانی: RAG به طور فزایندهای با پایگاههای داده، APIها و دیگر منابع داده سازمانی ترکیب میشود تا به عنوان یک موتور جستجوی هوشمند برای کل شرکت عمل کند.۳ این روند، RAG را از یک راهحل ساده پرسش و پاسخ به یک ابزار استراتژیک برای مدیریت دانش سازمانی تبدیل خواهد کرد.
- رشد Agentic RAG: با کاهش پیچیدگی پیادهسازی RAG پایه، زمینه برای توسعه معماریهای پیشرفتهتر مانند
Agentic RAGفراهم میشود. این معماریها، به جای تمرکز بر چالشهای فنی پایه، میتوانند بر روی قابلیتهای سطح بالاتر مانند استدلال، برنامهریزی و تعامل با چندین منبع تمرکز کنند. این گرایش نشاندهنده یک چرخه بازخورد مثبت در تکامل فناوری است که RAG را به سمت تبدیل شدن به یک سیستم هوشمندتر و خودکارتر سوق میدهد.
۹. نتیجهگیری
RAG یک راهحل کلیدی برای حل محدودیتهای اساسی LLMها، از جمله توهم، اطلاعات قدیمی و عدم دسترسی به دادههای اختصاصی است. این رویکرد به سازمانها اجازه میدهد تا از قدرت هوش مصنوعی مولد به روشی مقرونبهصرفه و قابل کنترل بهرهمند شوند. موفقیت یک سیستم RAG به کیفیت تمام مراحل خط لوله، از ایندکسسازی دادهها گرفته تا انتخاب بازیاب مناسب و اجرای دقیق مهندسی پرامپت، وابسته است.
با وجود مزایای متعدد، چالشهایی مانند پیچیدگی سیستم، تأخیر زمانی و وابستگی به کیفیت دادههای خارجی باید به دقت مدیریت شوند. تکامل RAG به سمت معماریهای پیشرفته مانند RAG-Fusion، Multi-hop RAG و Agentic RAG نشاندهنده پتانسیل بالای این فناوری برای حل مشکلات پیچیدهتر است. در نهایت، برای پیادهسازی موفق RAG، تمرکز باید بر روی کیفیت دادهها، مدیریت خط لوله و انتخاب رویکرد مناسب بر اساس نیازهای پروژه باشد. این فناوری نه تنها یک ابزار برای تولید متن است، بلکه یک توانمندساز (Enabler) برای تحول دیجیتال مبتنی بر دادههای داخلی به شمار میرود.
۱. آزمون کوتاه پاسخ (۱۰ سوال)
به هر سوال در ۲-۳ جمله پاسخ دهید.
۱. RAG (Retrieval-Augmented Generation) چیست و هدف اصلی آن حل کدام یک از چالشهای LLMها است؟ RAG یک چارچوب هوش مصنوعی است که قابلیتهای تولیدی LLMها را با بازیابی اطلاعات از پایگاههای دانش خارجی ترکیب میکند. هدف اصلی آن حل چالشهایی مانند تولید پاسخهای نادرست و غیرواقعی (توهم)، محدودیت دانش به دلیل تاریخ آموزش، و عدم توانایی در دسترسی به اطلاعات خصوصی یا اختصاصی سازمانها است.
۲. چرا RAG نسبت به Fine-tuning برای معرفی اطلاعات جدید به LLM مقرونبهصرفهتر است؟ Fine-tuning یا آموزش مجدد یک مدل پایه برای تطبیق با یک حوزه خاص، فرآیندی بسیار پرهزینه، زمانبر و نیازمند منابع محاسباتی عظیم است. در مقابل، RAG یک رویکرد جایگزین و مقرونبهصرفه برای معرفی دادههای جدید به LLM است و نیاز به سرمایهگذاریهای سنگین اولیه را از بین میبرد.
۳. فاز ایندکسسازی دادهها در RAG شامل چه مراحلی است و هدف آن چیست؟ فاز ایندکسسازی شامل بارگذاری دادهها، استخراج و تبدیل، تقسیمبندی (chunking) به قطعات کوچکتر، و تبدیل هر قطعه به یک بردار عددی (embedding) با استفاده از مدل جاسازی است. هدف آن آمادهسازی پایگاه دانش خارجی در یک فرمت قابل جستجو (پایگاه داده برداری) برای LLM است.
۴. تفاوت اصلی بین بازیابهای پراکنده (Sparse Retrievers) و بازیابهای متراکم (Dense Retrievers) در چیست؟ بازیابهای پراکنده بر تطابق لغوی و کلمات کلیدی متکی هستند و در درک مترادفها محدودیت دارند (مانند TF-IDF و BM25). در مقابل، بازیابهای متراکم از جاسازیها و شبکههای عصبی برای تطابق معنایی استفاده میکنند و قادرند شباهت معنایی را درک کنند (مانند DPR).
۵. نقش تولیدکننده (Generator) در فاز بازیابی و تولید RAG چیست و چرا مهندسی پرامپت در این مرحله حیاتی است؟ تولیدکننده (معمولاً یک LLM) پرسش کاربر و دادههای بازیابیشده را دریافت کرده و با استفاده از مهارتهای تولیدی خود، پاسخی منسجم و دقیق ایجاد میکند. مهندسی پرامپت حیاتی است زیرا دادههای بازیابیشده به صورت دقیق به پرامپت کاربر اضافه میشوند تا یک پرامپت «افزوده» ایجاد شود و به LLM کمک کند پاسخ دقیقتری ارائه دهد.
۶. سه مزیت کلیدی RAG را نام ببرید و توضیح دهید که چگونه هر یک به بهبود عملکرد LLM کمک میکند؟ اولاً، افزایش دقت و واقعگرایی با ارائه “حقایق” به مدل که توهمات را کاهش میدهد. ثانیاً، دسترسی به اطلاعات بهروز و اختصاصی با اتصال به منابع خارجی که محدودیت دانش مدل را برطرف میکند. و ثالثاً، شفافیت و قابلیت ارجاع به منبع با ارائه ارجاعات به اسناد منبع، که اعتماد کاربر را افزایش میدهد.
۷. دو چالش اصلی در پیادهسازی و نگهداری سیستمهای RAG چیست؟ اولاً، وابستگی به کیفیت دادههای خارجی؛ اگر پایگاه دانش شامل اطلاعات نادرست یا قدیمی باشد، خروجی مدل نیز نادرست خواهد بود. ثانیاً، پیچیدگی و سربار نگهداری سیستم به دلیل اجزای متعدد (ایندکسسازی، پایگاه داده برداری، بازیابی و نسلسازی) که میتواند هزینههای عملیاتی را افزایش دهد.
۸. RAG-Fusion چگونه دقت و جامعیت بازیابی را در مقایسه با RAG ساده افزایش میدهد؟ RAG-Fusion با تبدیل پرسش اصلی کاربر به چندین پرسش فرعی یا بازنویسیشده، بازیابی برداری را برای هر یک انجام میدهد. سپس با استفاده از الگوریتم Reciprocal Rank Fusion (RRF)، نتایج را از منابع متعدد ترکیب و رتبهبندی مجدد میکند. این روش با بررسی یک پرسش از زوایای مختلف، دقت و جامعیت بازیابی را به شدت افزایش میدهد.
۹. Agentic RAG چه تفاوتی با RAG سنتی دارد و چه قابلیتهای جدیدی را معرفی میکند؟ Agentic RAG از عاملهای هوش مصنوعی (AI Agents) با قابلیتهایی مانند حافظه، برنامهریزی گامبهگام، تصمیمگیری، و استفاده از ابزارهای خارجی بهره میبرد. این رویکرد RAG را از یک دستیار “منفعل” به یک “شریک فعال” تبدیل میکند که میتواند به طور مستقل تصمیمگیری و برنامهریزی کند و پرسشهای پیچیده را به زیرپرسشها تقسیم کند.
۱۰. چگونه RAG به مدیریت دانش سازمانی کمک میکند؟ یک مثال بزنید. RAG به کارمندان کمک میکند تا به سرعت و به زبان طبیعی به اطلاعات داخلی شرکت دسترسی پیدا کنند. به عنوان مثال، یک سیستم RAG میتواند اطلاعات پراکنده در فایلها، CRM و اسناد را به یک پایگاه دانش متمرکز و قابل جستجو تبدیل کند، که این امر بهرهوری را افزایش میدهد.
۲. کلید پاسخ آزمون کوتاه
۱. RAG (Retrieval-Augmented Generation) چیست و هدف اصلی آن حل کدام یک از چالشهای LLMها است؟ RAG یک چارچوب هوش مصنوعی است که قابلیتهای تولیدی LLMها را با بازیابی اطلاعات از پایگاههای دانش خارجی ترکیب میکند. هدف اصلی آن حل چالشهایی مانند توهم ( hallucination)، محدودیت دانش به دلیل تاریخ آموزش، و عدم توانایی در دسترسی به اطلاعات خصوصی یا اختصاصی سازمانها است.
۲. چرا RAG نسبت به Fine-tuning برای معرفی اطلاعات جدید به LLM مقرونبهصرفهتر است؟ آموزش مجدد یک مدل پایه (Fine-tuning) فرآیندی بسیار پرهزینه، زمانبر و نیازمند منابع محاسباتی عظیم است. RAG یک رویکرد جایگزین و مقرونبهصرفه است زیرا به سازمانها اجازه میدهد تا از قدرت LLMها برای دادههای داخلی و بهروز خود استفاده کنند، بدون نیاز به سرمایهگذاریهای سنگین اولیه برای آموزش مجدد.
۳. فاز ایندکسسازی دادهها در RAG شامل چه مراحلی است و هدف آن چیست؟ فاز ایندکسسازی شامل بارگذاری دادههای خام، استخراج و تبدیل متن طبیعی، تقسیمبندی (chunking) اسناد به قطعات کوچکتر، و تبدیل هر قطعه به یک نمایش عددی یا بردار (embedding) با استفاده از مدل جاسازی است. هدف آن آمادهسازی دادهها و ذخیره آنها در یک پایگاه داده برداری برای جستجوی سریع بر اساس شباهت معنایی است.
۴. تفاوت اصلی بین بازیابهای پراکنده (Sparse Retrievers) و بازیابهای متراکم (Dense Retrievers) در چیست؟ بازیابهای پراکنده (مانند TF-IDF و BM25) بر تطابق لغوی و کلمات کلیدی متکی هستند و در درک مترادفها و شباهتهای معنایی محدودیت دارند. بازیابهای متراکم (مانند DPR) از جاسازیها و شبکههای عصبی برای انجام تطابق معنایی استفاده میکنند و قادرند شباهت معنایی را درک کرده و در مجموعههای داده بزرگ و متنوع بهتر عمل کنند.
۵. نقش تولیدکننده (Generator) در فاز بازیابی و تولید RAG چیست و چرا مهندسی پرامپت در این مرحله حیاتی است؟ تولیدکننده که معمولاً یک LLM است، پرسش اصلی کاربر و دادههای بازیابیشده را به عنوان ورودی دریافت میکند و پاسخی منسجم، دقیق و قابل فهم ایجاد میکند. مهندسی پرامپت حیاتی است زیرا دادههای بازیابیشده به صورت دقیق به پرامپت کاربر اضافه میشود تا یک پرامپت «افزوده» ایجاد شود که به LLM کمک میکند پاسخ دقیقتری ارائه دهد و پاسخدهی مبتنی بر واقعیت (Grounded Generation) را تضمین کند.
۶. سه مزیت کلیدی RAG را نام ببرید و توضیح دهید که چگونه هر یک به بهبود عملکرد LLM کمک میکند؟ اولاً، افزایش دقت و واقعگرایی: با فراهم کردن “حقایق” به عنوان ورودی، توهمات هوش مصنوعی را به طور قابل توجهی کاهش میدهد. ثانیاً، دسترسی به اطلاعات بهروز و اختصاصی: با اتصال به منابع خارجی، محدودیت دانش LLMهای پایه را برطرف کرده و امکان دسترسی به جدیدترین و محرمانه ترین اطلاعات را میدهد. ثالثاً، شفافیت و قابلیت ارجاع به منبع: خروجی میتواند شامل ارجاعاتی به اسناد منبع باشد، که به کاربر امکان میدهد صحت اطلاعات را بررسی کرده و اعتماد بیشتری به پاسخها داشته باشد.
۷. دو چالش اصلی در پیادهسازی و نگهداری سیستمهای RAG چیست؟ اولاً، وابستگی به کیفیت دادههای خارجی: اگر پایگاه دانش شامل اطلاعات نادرست، قدیمی یا مغرضانه باشد، خروجی مدل نیز چنین خواهد بود (“Garbage in, garbage out”). ثانیاً، پیچیدگی و سربار نگهداری سیستم: RAG شامل اجزای متعددی (ایندکسسازی، پایگاه داده برداری، بازیابی و نسلسازی) است که این معماری پیچیده، سربار نگهداری بیشتری را نسبت به LLMهای سنتی به همراه دارد.
۸. RAG-Fusion چگونه دقت و جامعیت بازیابی را در مقایسه با RAG ساده افزایش میدهد؟ RAG-Fusion ابتدا پرسش اصلی کاربر را به چندین پرسش فرعی یا بازنویسیشده تبدیل میکند. سپس برای هر یک از این پرسشها، بازیابی برداری انجام داده و مجموعهای از اسناد را جمعآوری میکند. در نهایت، با استفاده از الگوریتم Reciprocal Rank Fusion (RRF)، نتایج را از منابع متعدد ترکیب و رتبهبندی مجدد میکند تا یک لیست نهایی یکپارچه و دقیقتر ارائه دهد، که این امر با بررسی پرسش از زوایای مختلف، دقت و جامعیت بازیابی را به شدت افزایش میدهد.
۹. Agentic RAG چه تفاوتی با RAG سنتی دارد و چه قابلیتهای جدیدی را معرفی میکند؟ Agentic RAG یک تکامل بزرگ از RAG سنتی است که از عاملهای هوش مصنوعی (AI Agents) برای تسهیل فرآیند استفاده میکند. این عاملها دارای قابلیتهایی مانند حافظه، برنامهریزی گامبهگام، تصمیمگیری، و استفاده از ابزارهای خارجی (مانند APIها یا پایگاههای داده متعدد) هستند. این رویکرد RAG را از یک دستیار “منفعل” که فقط دادهها را بازیابی میکند، به یک “شریک فعال” تبدیل میکند که میتواند به طور مستقل تصمیمگیری و برنامهریزی کند و پرسشهای پیچیده را به زیرپرسشها تقسیم کند.
۱۰. چگونه RAG به مدیریت دانش سازمانی کمک میکند؟ یک مثال بزنید. RAG به کارمندان کمک میکند تا به سرعت و به زبان طبیعی به اطلاعات داخلی شرکت دسترسی پیدا کنند. به عنوان مثال، یک سیستم RAG میتواند اطلاعات پراکنده در فایلها، CRM و اسناد را به یک پایگاه دانش متمرکز و قابل جستجو تبدیل کند، و به کارمندان این امکان را میدهد که به سرعت به سیاستهای شرکت، دستورالعملها، یا اطلاعات مشتری دسترسی پیدا کنند. این امر بهرهوری را افزایش داده و نیاز به جستجوهای دستی را کاهش میدهد.
۳. سوالات تشریحی (۵ سوال)
۱. معماری دو فازی RAG (ایندکسسازی و بازیابی/تولید) را به تفصیل شرح دهید و توضیح دهید که چگونه هر فاز به حل چالشهای اصلی LLMها کمک میکند. به اجزای کلیدی هر فاز و نقش آنها اشاره کنید. ۲. مزایای RAG را در مقایسه با روشهای Fine-tuning و Prompt Engineering تحلیل کنید. چه زمانی استفاده از RAG مناسبتر است و چه زمانی هر یک از دو روش دیگر ترجیح داده میشوند؟ به الزامات منابع و نوع داده مناسب برای هر روش اشاره کنید. ۳. با وجود مزایای RAG در کاهش توهمات، این پدیده به طور کامل از بین نمیرود. علل توهمزایی در سیستمهای RAG را توضیح دهید و چهار استراتژی عملی برای مدیریت و کاهش آنها برای توسعهدهندگان را بیان کنید. ۴. تکنیکهای پیشرفته RAG (RAG-Fusion، Multi-hop RAG، Agentic RAG، Multimodal RAG) را تشریح کنید. برای هر یک، هدف، نحوه عملکرد و نوع چالشهایی که حل میکنند را توضیح دهید. چگونه این تکنیکها نشاندهنده تکامل RAG فراتر از یک دستیار “منفعل” هستند؟ ۵. سه کاربرد صنعتی RAG را که در متن ذکر شده است، انتخاب کرده و برای هر یک، توضیح دهید که RAG چگونه مشکل “اطلاعات پراکنده و غیرقابل دسترسی” را حل میکند و چه تأثیری بر عملکرد آن صنعت دارد. به مثالهای موردی (در صورت وجود) اشاره کنید.
۴. واژهنامه اصطلاحات کلیدی
Reciprocal Rank Fusion (RRF): الگوریتمی برای ترکیب و رتبهبندی مجدد نتایج جستجو از چندین منبع مختلف، که در RAG-Fusion استفاده میشود.
RAG (Retrieval-Augmented Generation): تولید با بازیابی افزوده؛ یک چارچوب هوش مصنوعی که مدلهای زبانی بزرگ (LLM) را با یک سیستم بازیابی اطلاعات ترکیب میکند تا دقت، بهروز بودن و واقعگرایی پاسخها را افزایش دهد.
LLM (Large Language Model): مدل زبانی بزرگ؛ یک مدل هوش مصنوعی که قادر به درک، تفسیر و تولید متن شبیه انسان است.
توهم (Hallucination): پدیدهای که در آن LLMها اطلاعات نادرست، غیرواقعی یا بیربط را تولید میکنند.
Fine-tuning (آموزش مجدد): فرآیند ادامه آموزش یک مدل از پیش آموزشدیده بر روی یک مجموعه داده کوچکتر و خاصتر برای تطبیق آن با یک حوزه یا وظیفه خاص.
Prompt Engineering (مهندسی پرامپت): فرآیند طراحی و بهینهسازی پرامپتها (ورودیهای متنی) برای هدایت LLMها به سمت تولید خروجیهای مطلوب و دقیقتر.
Data Indexing (ایندکسسازی دادهها): فاز اولیه در RAG که در آن دادههای خام از منابع مختلف جمعآوری، پردازش و به فرمتی قابل جستجو تبدیل میشوند (معمولاً بردارهای عددی).
Chunking (تقسیمبندی): فرآیند تقسیم اسناد یا متون بزرگ به قطعات (chunks) کوچکتر و قابل مدیریت برای بازیابی دقیقتر اطلاعات.
Embedding Model (مدل جاسازی): یک مدل هوش مصنوعی که کلمات، عبارات یا اسناد را به بردارهای عددی (جاسازیها) تبدیل میکند که شباهت معنایی بین آنها را نشان میدهد.
Vector Database (پایگاه داده برداری): پایگاه دادهای که به طور خاص برای ذخیره و جستجوی سریع بردارهای جاسازی شده بر اساس شباهت معنایی طراحی شده است.
Retriever (بازیاب): جزئی از سیستم RAG که مسئول یافتن مرتبطترین قطعات اطلاعاتی از پایگاه دانش در پاسخ به یک پرسش است.
Generator (تولیدکننده): جزئی از سیستم RAG (معمولاً یک LLM) که پس از دریافت اطلاعات بازیابیشده و پرسش کاربر، پاسخ نهایی را تولید میکند.
Sparse Retrievers (بازیابهای پراکنده): بازیابهایی که بر تطابق لغوی و کلمات کلیدی متکی هستند (مانند TF-IDF و BM25).
Dense Retrievers (بازیابهای متراکم): بازیابهایی که از جاسازیها و شبکههای عصبی برای انجام تطابق معنایی استفاده میکنند (مانند DPR).
Hybrid Search (جستجوی ترکیبی): رویکردی که مزایای بازیابهای پراکنده و متراکم را برای بهبود دقت جستجو ترکیب میکند.
Grounded Generation (نسلسازی مبتنی بر واقعیت): فرآیند تولید پاسخی توسط LLM که کاملاً بر اساس حقایق و اطلاعات موجود در اسناد بازیابیشده بنا شده است.
Latency (تأخیر زمانی): مدت زمانی که طول میکشد تا یک سیستم RAG پس از دریافت پرسش، پاسخ نهایی را تولید و ارائه کند.
RAG-Fusion: یک تکنیک پیشرفته RAG که پرسش اصلی را به چندین پرسش فرعی تقسیم میکند، نتایج بازیابی را از منابع متعدد جمعآوری کرده و با الگوریتم Reciprocal Rank Fusion (RRF) ترکیب میکند.
Multi-hop RAG: روشی برای پاسخ به پرسشهای پیچیده که نیاز به استدلال و جمعآوری اطلاعات از چندین منبع یا سند مختلف در یک فرآیند زنجیرهای دارد.
Agentic RAG: یک تکامل بزرگ از RAG که از عاملهای هوش مصنوعی (AI Agents) با قابلیتهای برنامهریزی، تصمیمگیری، و استفاده از ابزارهای خارجی برای تسهیل فرآیند استفاده میکند.
AI Agents (عاملهای هوش مصنوعی): نرمافزارهایی با قابلیت حافظه، برنامهریزی، تصمیمگیری و استفاده از ابزارهای خارجی برای انجام وظایف پیچیده.
Multimodal RAG (RAG چندوجهی): رویکردی پیشرفته که سیستم RAG را قادر میسازد تا دادهها را فراتر از متن، از منابع چندوجهی مانند تصاویر، ویدیو، و صوت بازیابی و پردازش کند.