


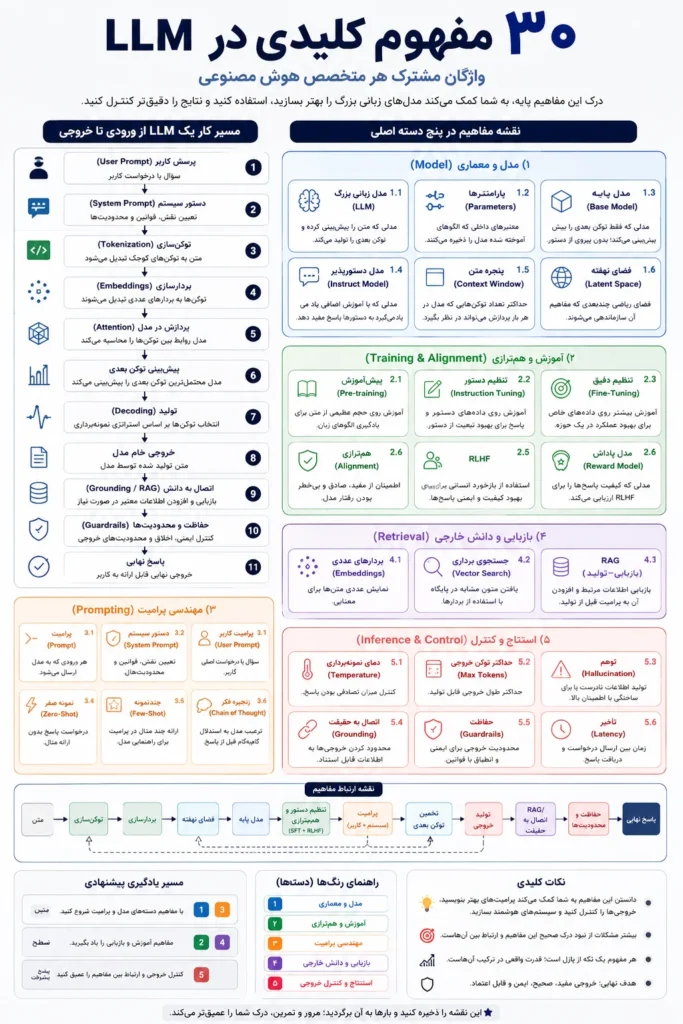
راهنمای جامع مفاهیم پایه و پیشرفته مدلهای زبانی بزرگ
اگر تنها پنج مفهوم از این فهرست را بدانید، احتمالاً میتوانید نیازهای روزمره خود را با ابزارهایی مانند ChatGPT برطرف کنید؛ اما اگر قصد دارید یک عامل هوشمند (AI Agent)، سامانه RAG، دستیار سازمانی یا هر محصول پیشرفته مبتنی بر هوش مصنوعی بسازید، این ۳۰ مفهوم الفبای کار شما و زبان مشترک تیم توسعه خواهند بود.
مدلهای زبانی بزرگ (Large Language Models) در چند سال اخیر قواعد بازی را در تمام صنایع تغییر دادهاند. با این حال، بسیاری از فعالان این حوزه تنها با لایه ظاهری این فناوری آشنا هستند. ندانستن مفاهیم عمیقتری مانند فضای نهفته (Latent Space)، RLHF یا پنجره متن (Context Window) صرفاً یک ضعف تئوریک نیست؛ بلکه مستقیماً روی کیفیت معماری سیستم، مهندسی پرامپت، تحلیل خطاها و انتخاب مدل مناسب اثر منفی میگذارد.
مشکل اینجاست که ندانستن این مفاهیم، فقط یک ضعف تئوری نیست؛ بلکه مستقیماً روی کیفیت طراحی سامانههای هوش مصنوعی، مهندسی پرامپت، تحلیل خطاها و حتی انتخاب مدل مناسب اثر میگذارد.
در این مقاله از رسانه تخصصی هوش مصنوعی سیمرغ، این مفاهیم کلیدی را به زبانی ساده اما دقیق و مهندسی بررسی میکنیم تا تصویر کاملی از مکانیزم درونی مدلهای زبانی به دست آورید.
نقشه راه و دستهبندی مفاهیم
برای جلوگیری از حفظ کردن طوطیوار اصطلاحات و درک بهتر ارتباط میان آنها، این ۳۰ مفهوم را در پنج ایستگاه اصلی دستهبندی کردهایم:
- استنتاج و کنترل خروجی (Inference & Control)
- مدل و معماری (Model Architecture)
- آموزش و همترازی (Training & Alignment)
- مهندسی پرامپت (Prompt Engineering)
- پردازش داده و بازیابی اطلاعات (Data Processing & Retrieval)
بخش اول: مدل و معماری (Model Architecture)
۱. مدل زبانی بزرگ (LLM)
یک شبکه عصبی با ابعاد بسیار عظیم است که روی حجم فوقالعادهای از دادههای متنی آموزش دیده تا بتواند «توکن بعدی» را در یک توالی متنی پیشبینی کند. مدلهایی مانند GPT ،Claude ،Gemini و Llama در این دسته قرار میگیرند. مدلها پایگاهداده نیستند و اطلاعات را ذخیره نمیکنند؛ بلکه الگوهای زبانی را میآموزند.
نمونهها:
- GPT
- Claude
- Gemini
- Llama
- Qwen
این مدلها در واقع دانش را «ذخیره» نمیکنند، بلکه الگوهای زبان را یاد میگیرند.
۲. پارامترها (Parameters)
پارامترها معادل سیناپسها در مغز انسان و در واقع همان وزنهای داخلی شبکه عصبی هستند. افزایش تعداد پارامترها (که امروزه از چند میلیارد تا تریلیونها متغیر است) ظرفیت یادگیری و پیچیدگی مدل را بالا میبرد، اما همزمان هزینه پردازش و نیاز سختافزاری را نیز به شدت افزایش میدهد.
هرچه تعداد پارامترها بیشتر باشد:
- ظرفیت یادگیری افزایش مییابد.
- مدل پیچیدهتر میشود.
- هزینه آموزش و اجرا بیشتر خواهد بود.
مدلهای امروزی از چند میلیارد تا صدها میلیارد پارامتر دارند.
۳. مدل پایه (Base Model)
مدل پایه تنها برای پیشبینی توکن بعدی آموزش دیده است.
مثلاً اگر بنویسید:
امروز هوا…
مدل ادامه متن را حدس میزند.
اما هنوز یاد نگرفته مانند یک دستیار به سؤال پاسخ دهد.
۴. مدل دستورپذیر (Instruct Model)
مدل پایه پس از آموزشهای تکمیلی به مدل دستورپذیر تبدیل میشود.
این مدل:
- سؤال را بهتر درک میکند.
- ساختار پاسخ مناسب ارائه میدهد.
- از دستورهای کاربر پیروی میکند.
تقریباً تمام چتباتهای امروزی از این نوع هستند.
۵. پنجره متن (Context Window)
حداکثر ظرفیت حافظه کوتاهمدت مدل در یک نشست (Session) است. این عدد نشان میدهد مدل چه تعداد توکن را میتواند به صورت همزمان در یک درخواست پردازش کند. هرچه این پنجره بزرگتر باشد، مدل قادر است اسناد، کتابها و کدهای طولانیتری را بدون فراموش کردن متنهای ابتدایی تحلیل کند.
مثلاً اگر پنجره متن ۲۰۰ هزار توکن باشد، مدل میتواند کتابهای نسبتاً بزرگی را در یک درخواست تحلیل کند.
هرچه Context بزرگتر باشد:
- حافظه کوتاهمدت مدل بیشتر میشود.
- اسناد طولانیتر قابل تحلیل هستند.
۶. فضای نهفته (Latent Space)
یکی از انتزاعیترین و مهمترین مفاهیم هوش مصنوعی است. مدلها کلمات و مفاهیم را در یک فضای هندسی چندبعدی بازنمایی میکنند. در این فضا، مفاهیم مشابه به هم نزدیکترند؛ برای مثال فاصله ریاضی واژه «پزشک» به «پرستار» بسیار کمتر از فاصله آن تا واژه «برنامهنویس» است.
در این فضا:
- «گربه» به «ببر» نزدیکتر از «هواپیما» است.
- «پزشک» به «پرستار» نزدیکتر از «برنامهنویس» قرار میگیرد.
شباهت مفهومی در این فضا به صورت فاصله ریاضی نمایش داده میشود.
مقایسه مدل پایه و مدل دستورپذیر
| مفهوم | عملکرد | کاربرد و مثال |
| ۵. مدل پایه (Base Model) | تنها برای تکمیل متن و پیشبینی کلمه بعدی آموزش دیده است. | اگر بنویسید «آسمان آبی»، ادامه میدهد «است و ابرها…». برای ساخت چتبات خام است. |
| ۶. مدل دستورپذیر (Instruct Model) | با آموزشهای ثانویه یاد گرفته از دستورات پیروی کند و ساختار پاسخدهی داشته باشد. | درک میکند که باید به سؤال «آسمان چرا آبی است؟» یک پاسخ علمی و ساختاریافته بدهد. |
بخش دوم: آموزش و همترازی (Training & Alignment)
۷. پیشآموزش (Pre-training)
فاز اول و پرهزینهترین بخش ساخت یک LLM است. مدل میلیاردها صفحه وب، کتاب و مقاله را میخواند تا صرفاً ساختار زبان، گرامر، حقایق جهان و الگوهای آماری کلمات را بیاموزد، نه اینکه به سؤالات پاسخ دهد.
هدف:
یادگیری زبان.
نه پاسخ دادن.
در این مرحله مدل فقط الگوهای آماری زبان را میآموزد.
۸. تنظیم دستوری (Instruction Tuning)
مرحلهای است که مدل پایه را به یک دستیار تبدیل میکند. در این مرحله، مجموعهای از جفتهای «دستور/پاسخ» به مدل داده میشود تا یاد بگیرد چگونه باید درخواستهای انسان را فرمتبندی و اجرا کند.
مدل یاد میگیرد:
- دستورها را بفهمد.
- ساختار مناسب خروجی تولید کند.
۹. تنظیم دقیق (Fine-tuning)
فرآیند آموزش مجدد یا تکمیلی مدل روی یک مجموعه داده تخصصی (مانند متون حقوقی، پروندههای پزشکی یا کدهای برنامهنویسی اختصاصی یک شرکت) است تا مدل در یک دامنه (Domain) خاص، عملکرد بهتری نشان دهد.
مثلاً:
- پزشکی
- حقوق
- بانکداری
- برنامهنویسی
در این حالت مدل روی دادههای تخصصی آموزش میبیند.
۱۰. یادگیری تقویتی از بازخورد انسانی (RLHF)
مخفف Reinforcement Learning from Human Feedback است. در این تکنیک، انسانها به پاسخهای مختلف مدل امتیاز میدهند. مدل از این امتیازات الگو میگیرد تا خروجیهای خود را با ترجیحات انسانی تطبیق دهد.
مخفف:
Reinforcement Learning from Human Feedback
در این روش انسان پاسخهای مختلف مدل را رتبهبندی میکند.
مدل یاد میگیرد:
کدام پاسخ بهتر است.
۱۱. همترازی (Alignment)
تلاش برای همسو کردن رفتار مدل با ارزشها، اخلاقیات و نیازهای انسانی. هدف Alignment این است که خروجیهای مدل علاوه بر دقیق بودن، مفید (Helpful)، صادق (Honest) و ایمن (Harmless) باشند.
هدف Alignment این است که مدل:
- مفید باشد.
- صادق باشد.
- تا حد امکان ایمن عمل کند.
در واقع پاسخ مدل باید علاوه بر «درست بودن»، «رفتار مناسب» نیز داشته باشد.
۱۲. مدل پاداش (Reward Model)
یک سیستم هوش مصنوعی جانبی است که معمولاً در فرآیند RLHF استفاده میشود. وظیفه آن جایگزین شدن با انسان در ارزیابی و امتیازدهی به خروجیهای مدل اصلی است تا فرآیند آموزش سرعت بگیرد.
بخش سوم: مهندسی پرامپت (Prompt Engineering)
۱۳. پرامپت (Prompt)
هرگونه ورودی (شامل متن، سؤال، تصویر، فایل یا دستور) که از سوی کاربر برای مدل ارسال میشود تا خروجی تولید کند.
شامل:
- سؤال
- دستور
- متن
- مثال
- فایل
- تصویر
۱۴. System Prompt
دستور سطح بالا که نقش مدل را مشخص میکند.
مثلاً:
«در نقش پزشک پاسخ بده.»
یا
«همیشه پاسخها کوتاه باشند.»
۱۵. User Prompt
درخواست واقعی کاربر.
مثلاً:
«بهترین روش آموزش پایتون چیست؟»
۱۶. Zero-shot
بدون هیچ نمونهای از خروجی.
فقط سؤال مطرح میشود.
۱۷. Few-shot
قبل از سؤال، چند نمونه مطلوب نمایش داده میشود.
این کار کیفیت خروجی را به شکل محسوسی افزایش میدهد.
۱۸. Chain of Thought
در این روش از مدل خواسته میشود فرآیند استدلال خود را مرحلهبهمرحله طی کند. این رویکرد میتواند برای برخی مسائل پیچیده به بهبود کیفیت پاسخ کمک کند، هرچند مدلهای جدید اغلب بدون نیاز به درخواست صریح نیز استدلال داخلی خود را انجام میدهند.
مقایسه انواع پرامپت و تکنیکها
| تکنیک / مفهوم | تعریف تخصصی | مثال کاربردی |
| ۱۴. System Prompt | دستورات سطح بالا و پنهان که شخصیت، لحن و قوانین کلی مدل را تعیین میکند. | «شما یک برنامهنویس ارشد پایتون هستید. کدهای بهینه بنویسید.» |
| ۱۵. User Prompt | سؤال یا درخواست مستقیم و فعلی کاربر که در لحظه تایپ میشود. | «چگونه یک حلقه For در پایتون بنویسم؟» |
| ۱۶. Zero-shot | درخواست از مدل بدون ارائه هیچگونه مثال یا الگوی قبلی. | «متن زیر را به فرانسوی ترجمه کن.» |
| ۱۷. Few-shot | ارائه چند نمونه مطلوب از ورودی و خروجی پیش از طرح سؤال اصلی برای راهنمایی مدل. | «انگلیسی: Apple -> فرانسوی: Pomme. حالا ترجمه کن: Book» |
| ۱۸. Chain of Thought (CoT) | ترغیب مدل به تفکر مرحلهبهمرحله با عباراتی نظیر “قدمبهقدم فکر کن” جهت حل مسائل پیچیده. | «ابتدا متغیرها را استخراج کن، سپس فرمول را بنویس و بعد حل کن.» |
بخش چهارم: پردازش داده و بازیابی اطلاعات (Data Processing & Retrieval)
۱۹. توکن (Token)
کوچکترین واحد پردازش متن در هوش مصنوعی. یک توکن لزوماً یک کلمه نیست؛ میتواند یک حرف، بخشی از یک کلمه، یک عدد یا علامت نگارشی باشد. محاسبات مالی (API) و محدودیتهای پردازشی تماماً بر اساس تعداد توکنها سنجیده میشوند.
ممکن است:
- یک کلمه
- بخشی از یک کلمه
- عدد
- علامت نگارشی
باشد.
تمام هزینه، سرعت و حافظه مدل بر اساس تعداد Token محاسبه میشود.
۲۰. توکنسازی (Tokenization)
الگوریتم و فرآیند خرد کردن متن خام ورودی کاربر به توکنهای قابل فهم برای ماشین پیش از ارسال آنها به شبکههای عصبی.
قبل از ورود متن به مدل، ابتدا Tokenization انجام میشود.
۲۱. بردارهای معنایی (Embeddings)
ترجمه توکنها و متون به آرایههایی از اعداد واقعی (Vectors). این بردارها ویژگیهای معنایی کلمات را در خود جای دادهاند و به ماشین اجازه میدهند روی مفاهیم انتزاعی زبان، محاسبات ریاضی انجام دهد.
جملههایی با مفهوم مشابه، بردارهای نزدیکتری خواهند داشت.
۲۲. جستجوی برداری (Vector Search)
تکنیک جستجویی که به جای تطابق کلمه به کلمه (Keyword Match)، به دنبال نزدیکترین بردارهای عددی در فضای نهفته میگردد. این روش باعث میشود جستجو بر اساس «معنی و مفهوم» انجام شود.
این روش پایه بسیاری از موتورهای جستجوی مدرن است.
۲۳. RAG
مخفف Retrieval-Augmented Generation است. این معماری ضعف حافظه دانشی مدل را پوشش میدهد. در RAG، پیش از پاسخگویی مدل، ابتدا اطلاعات مرتبط از یک پایگاهداده خارجی جستجو (Retrieval) شده و به عنوان بستر اطلاعاتی به پرامپت اضافه (Augmented) میشود تا مدل بر اساس آن محتوای دقیق تولید (Generation) کند.
مراحل کار:
- جستجو در منابع
- بازیابی اطلاعات
- افزودن اطلاعات به Prompt
- تولید پاسخ
این روش یکی از مؤثرترین راهکارها برای کاهش خطاهای دانشی مدل است.
بخش پنجم: استنتاج و کنترل خروجی
۲۴. استنتاج (Inference)
فاز اجرای مدل در محیط عملیاتی. زمانی که مدل آموزشدیده، پرامپت شما را میگیرد و بر اساس وزنهای شبکهاش کلمه به کلمه پاسخ را تولید میکند، در حال انجام عملیات Inference است. (زمانی که مدل از دانش آموزشدیده خود برای تولید پاسخ استفاده میکند، فرآیند Inference در حال انجام است.)
تمام مکالمات روزمره با ChatGPT در این مرحله اتفاق میافتد.
۲۵. دمای نمونهبرداری (Temperature)
پارامتری ریاضی (معمولاً بین ۰ تا ۱ یا ۲) که میزان خلاقیت و تصادفی بودن خروجی را کنترل میکند. دمای نزدیک به صفر پاسخهایی قطعی، خطی و رباتیک تولید میکند، در حالی که دمای بالاتر تنوع واژگان و خلاقیت را افزایش میدهد (اما ریسک خطا را نیز بالا میبرد). (Temperature میزان تصادفی بودن انتخاب توکنها را کنترل میکند.)
دمای پایین:
- پاسخهای پایدارتر
- قابل پیشبینیتر
دمای بالا:
- خلاقیت بیشتر
- تنوع بیشتر
- احتمال افزایش خطا نیز بیشتر میشود.
۲۶. توهم (Hallucination)
پاشنه آشیل مدلهای زبانی؛ زمانی که مدل با لحنی کاملاً مطمئن و قانعکننده، اطلاعاتی کاملاً غلط، ساختگی یا بیربط را تولید میکند. (زمانی که مدل اطلاعات نادرست را با اطمینان بیان میکند.)
توهم یکی از مهمترین چالشهای LLMها است.
۲۷. اتصال به حقیقت (Grounding)
در این روش خروجی مدل به اطلاعات معتبر و قابل استناد محدود میشود. (مکانیزم محدود کردن خروجی مدل به منابع اطلاعاتی موثق و قابل استناد (مانند RAG). Grounding باعث میشود مدل از تولید محتوای خارج از چارچوب مستندات داده شده خودداری کند و توهم کاهش یابد.)
Grounding احتمال Hallucination را کاهش میدهد.
۲۸. محدودکنندهها (Guardrails)
قوانین و کنترلهایی که از تولید پاسخهای خطرناک، غیراخلاقی یا نامناسب جلوگیری میکنند. (لایههای امنیتی و قوانینی که روی ورودی و خروجی مدل اعمال میشوند تا از تولید محتوای توهینآمیز، خطرناک، افشای اطلاعات حساس یا نقض قوانین جلوگیری کنند.)
۲۹. تأخیر (Latency)
مدت زمانی که از ارسال درخواست تا دریافت پاسخ طول میکشد. (مدت زمان مکث از لحظه فشردن دکمه ارسال پرامپت تا ظاهر شدن اولین توکنهای پاسخ (یا کل پاسخ). این شاخص به ترافیک شبکه، اندازه مدل و قدرت پردازنده (GPU) بستگی دارد.)
Latency به عوامل مختلفی وابسته است، از جمله:
- اندازه مدل
- تعداد توکنها
- سختافزار
- شبکه
۳۰. عامل هوشمند (Agent)
تکاملیافتهترین سطح استفاده از LLMها. عامل هوشمند فقط متن تولید نمیکند؛ بلکه میتواند برنامهریزی کند، از ابزارهای خارجی (مانند ماشینحساب، جستجوگر وب یا APIها) استفاده کند، اطلاعات به دست آورد و یک فرآیند چندمرحلهای را به طور خودکار تا رسیدن به هدف پیش ببرد.
عامل هوشمند فقط پاسخ تولید نمیکند.
بلکه میتواند:
- برنامهریزی کند.
- ابزارها را فراخوانی کند.
- اطلاعات جمعآوری کند.
- تصمیم بگیرد.
- چند مرحله را به صورت خودکار اجرا کند.
به همین دلیل، Agentها نسل بعدی کاربردهای هوش مصنوعی محسوب میشوند.
ارتباط این مفاهیم با یکدیگر
نگاهی به جریان کار یک سیستم هوش مصنوعی
درک این ۳۰ مفهوم زمانی ارزش پیدا میکند که متوجه شویم اینها جزایر جداگانه نیستند. فرآیند زیر، چرخه حیات یک درخواست در سامانههای مدرن مبتنی بر LLM (مانند یک دستیار سازمانی) را نشان میدهد:
- User Prompt: کاربر سؤالی را ارسال میکند.
- System Prompt: دستورات امنیتی و شخصیتی سیستم به درخواست الحاق میشود.
- Tokenization & Embeddings: متن به اعداد و بردارهای معنایی تبدیل میشود.
- Vector Search & RAG (اختیاری): اطلاعات کمکی از پایگاه داده بازیابی و به پرامپت افزوده میشود.
- Inference: مدل با استفاده از دانش و پارامترهای خود، پردازش را آغاز میکند.
- Grounding & Guardrails: خروجیِ در حال تولید از فیلترهای صحتسنجی و ایمنی عبور میکند.
- Final Response: پاسخ نهایی در اختیار کاربر قرار میگیرد.
اگر بخواهیم کل فرآیند را به زبان ساده خلاصه کنیم، مسیر زیر را خواهیم داشت:
کاربر
↓
User Prompt
↓
System Prompt
↓
Tokenization
↓
Embeddings
↓
Inference
↓
در صورت نیاز:
Vector Search
↓
RAG
↓
Grounding
↓
Guardrails
↓
پاسخ نهاییاین زنجیره نشان میدهد که مفاهیم معرفیشده، اجزای جداگانه نیستند؛ بلکه هر کدام حلقهای از فرآیند تولید پاسخ توسط یک مدل زبانی بزرگ را تشکیل میدهند.
مفاهیم مهمی که فراتر از این ۳۰ اصطلاح هستند
اگر قصد دارید به یک مهندس یا معمار ارشد هوش مصنوعی تبدیل شوید، نقشه راه یادگیری شما به اینجا ختم نمیشود. پس از تسلط روی واژگان بالا، توصیه میکنیم در سایت هوش مصنوعی سیمرغ مفاهیم زیر را دنبال کنید:
- مهندسی زمینه (Context Engineering)
- فراخوانی ابزارها (Tool Calling)
- پروتکل زمینه مدل (MCP – Model Context Protocol)
- مدیریت حافظه بلندمدت عاملها (Long-term Memory)
- مدلهای استدلالی (Reasoning Models)
- معماری ترکیب خبرگان (MoE – Mixture of Experts)
- مفهوم KV Cache برای بهینهسازی سرعت
- تکنیکهای ارزیابی مدلها (LLM Evaluation)
- سیستمهای چندعاملی (Multi-Agent Systems)
این مفاهیم نسل جدید کاربردهای هوش مصنوعی را شکل میدهند و در بسیاری از محصولات پیشرفته، نقشی اساسی دارند.

جمعبندی
مدلهای زبانی بزرگ صرفاً ابزار تولید متن نیستند، بلکه سامانههایی پیچیده با لایههای متعدد از آموزش، استنتاج، بازیابی دانش و کنترل خروجی هستند. درک مفاهیمی مانند Tokenization، Embeddings، RLHF، RAG، Context Window و Guardrails به شما کمک میکند از یک کاربر عادی به فردی تبدیل شوید که میتواند رفتار مدل را تحلیل، بهینهسازی و در پروژههای واقعی از آن استفاده کند.
اگر در مسیر یادگیری یا توسعه راهکارهای مبتنی بر هوش مصنوعی هستید، این ۳۰ مفهوم را نه بهعنوان فهرستی از اصطلاحات، بلکه بهعنوان واژگان پایه یک زبان جدید در نظر بگیرید؛ زبانی که امروز بخش مهمی از آینده مهندسی نرمافزار، اتوماسیون و تعامل انسان با ماشین را شکل میدهد.