


💡 معیارها و ارزیابی عملکرد مدلهای یادگیری ماشین: سفری عمیق در قلمرو پیشبینی و تصمیمگیری
راهنمای جامع معیارهای ارزیابی مدلهای رگرسیونی در یادگیری ماشین
۱. مقدمه
- چرا ارزیابی مدلهای رگرسیونی در یادگیری ماشین حیاتی است
- نقش معیارهای ارزیابی در تصمیمگیری فنی و تجاری
- جایگاه رگرسیون بهعنوان پایه علم داده و هوش مصنوعی
۲. رگرسیون چیست و چه زمانی از آن استفاده میکنیم؟
- تعریف رگرسیون در یادگیری ماشین
- تفاوت خروجیهای عددی پیوسته با مسائل طبقهبندی
- نمونههایی از کاربردهای واقعی (قیمت خانه، فروش، پیشبینی تقاضا)
۳. مفاهیم پایه در ارزیابی مدلهای رگرسیونی
۳.۱ مقدار واقعی (True Value) و مقدار پیشبینیشده (Predicted Value)
۳.۲ باقیمانده (Residual) و نقش آن در محاسبه خطا
- فرمول محاسبه Residual
- تفسیر بصری خطا در مدلهای رگرسیونی
۴. معرفی معیارهای رایج ارزیابی رگرسیون
- دستهبندی معیارها (مقیاسوابسته و مقیاسمستقل)
- مزایا و محدودیت استفاده از هر گروه
۵. خطای بایاس (Bias) و میانگین خطای بایاس (MBE)
- تعریف بایاس در پیشبینی
- چرا بایاس پایین الزاماً به معنی مدل خوب نیست
۶. ضریب تعیین (R-squared یا R²)
۶.۱ تعریف و تفسیر R²
۶.۲ فرمول و اجزای تشکیلدهنده (RSS و TSS)
۶.۳ ویژگیها و محدودیتهای R²
- مقایسه مدلها
- مشکل افزایش مصنوعی با افزودن ویژگیها
۶.۴ R² تعدیلشده (Adjusted R²)
۶.۵ منفی شدن R² در مدلهای غیرخطی
۷. میانگین مربعات خطا (Mean Squared Error – MSE)
- تعریف و فرمول
- حساسیت به خطاهای بزرگ و دادههای پرت
- نقش MSE در فرآیند بهینهسازی مدلها
۸. ریشه میانگین مربعات خطا (Root Mean Squared Error – RMSE)
- ارتباط RMSE با MSE
- تفسیر خطا در مقیاس متغیر هدف
- تفاوت مفهومی RMSE با «خطای میانگین واقعی»
۹. میانگین قدرمطلق خطا (Mean Absolute Error – MAE)
- تعریف و فرمول
- مقاومت در برابر دادههای پرت
- ارتباط MAE با میانه (Median)
- محدودیتهای استفاده در الگوریتمهای گرادیانی
۱۰. میانگین قدرمطلق خطای درصدی (MAPE)
- تعریف و فرمول
- محبوبیت در کاربردهای تجاری
- مشکلات MAPE:
- تقسیم بر صفر
- عدم تقارن در جریمه خطا
- وابستگی به صفر معنادار
- مفهوم wMAPE و کاربرد آن
۱۱. خطای درصدی متقارن (sMAPE)
- انگیزه ایجاد sMAPE
- فرمول و دامنه مقادیر
- ایرادات مفهومی و محاسباتی
- چرایی بحثبرانگیز بودن sMAPE در پیشبینی سری زمانی
۱۲. سایر معیارهای مهم ارزیابی رگرسیون
۱۲.۱ Mean Squared Log Error (MSLE)
۱۲.۲ Root Mean Squared Log Error (RMSLE)
۱۲.۳ معیارهای اطلاعاتی: AIC و BIC
- توازن بین دقت مدل و پیچیدگی
۱۳. مقایسه عملی معیارهای ارزیابی با مثال عددی
- بررسی چند سناریوی پیشبینی با خطای یکسان
- تفاوت واکنش MSE، MAE، MAPE و sMAPE
- تحلیل رفتار معیارها در مواجهه با خطاهای شدید
۱۴. استفاده از معیارهای رگرسیون در کتابخانه Scikit-Learn
۱۴.۱ معرفی متریکهای رگرسیون در scikit-learn
۱۴.۲ محاسبه MAE، MSE، R² و RMSE با کد پایتون
۱۵. مثال عملی: ارزیابی مدل رگرسیون روی دیتاست قیمت مسکن کالیفرنیا
۱۵.۱ بارگذاری دیتاست
۱۵.۲ تقسیم دادهها به آموزش و تست
۱۵.۳ آموزش مدل رگرسیون خطی
۱۵.۴ محاسبه و تفسیر نتایج معیارها
۱۶. چگونه معیار مناسب را انتخاب کنیم؟
- تأثیر دادههای پرت
- ترجیح تجاری به بیشبرآورد یا کمبرآورد
- انتخاب معیار وابسته به مقیاس یا مستقل از مقیاس
- تفاوت معیار بهینهسازی و معیار گزارشدهی
۱۷. جمعبندی نهایی
- هیچ معیار «بهترین مطلق» وجود ندارد
- اهمیت درک عمیق پیامدهای هر معیار
- نقش معیارهای ارزیابی در ارتباط با ذینفعان غیر فنی
۱. مقدمه
چرا ارزیابی مدلهای رگرسیونی در یادگیری ماشین حیاتی است؟
در سالهای اخیر، یادگیری ماشین به یکی از ارکان اصلی تصمیمگیری در سازمانها، کسبوکارها و حتی سیاستگذاریهای کلان تبدیل شده است. در میان انواع مختلف مسائل یادگیری ماشین، مسائل رگرسیونی جایگاه ویژهای دارند؛ چرا که بخش بزرگی از تصمیمات دنیای واقعی بر پایه پیشبینی مقادیر عددی پیوسته گرفته میشود. پیشبینی قیمت مسکن، میزان فروش آینده، تقاضای بازار، مصرف انرژی، درآمد، دما، یا حتی شاخصهای اقتصادی، همگی نمونههایی از مسائل رگرسیونی هستند.
اما ساختن یک مدل رگرسیونی بهتنهایی کافی نیست. سؤال کلیدی این است: مدل ما چقدر خوب عمل میکند؟ پاسخ به این سؤال بدون استفاده از معیارهای ارزیابی دقیق و مناسب عملاً غیرممکن است. ارزیابی مدلهای رگرسیونی به ما کمک میکند بفهمیم فاصله پیشبینیهای مدل با واقعیت چقدر است، خطاها چه الگویی دارند و آیا میتوان به خروجی مدل در تصمیمگیریهای مهم اعتماد کرد یا خیر.
نقش معیارهای ارزیابی در تصمیمگیری فنی و تجاری
معیارهای ارزیابی مدلهای رگرسیونی تنها ابزارهای فنی برای دانشمندان داده نیستند؛ بلکه پلی میان دنیای فنی و دنیای کسبوکار محسوب میشوند. از منظر فنی، این معیارها به متخصصان کمک میکنند مدلهای مختلف را با یکدیگر مقایسه کنند، نقاط ضعف مدل را شناسایی کنند و فرآیند بهبود مدل را هدفمند پیش ببرند. از منظر تجاری، معیارهای ارزیابی زبان مشترکی برای توضیح عملکرد مدل به مدیران، تصمیمگیران و ذینفعان غیر فنی فراهم میکنند.
برای مثال، یک مدیر ممکن است علاقهای به دانستن جزئیات ریاضی مدل نداشته باشد، اما وقتی میشنود «بهطور متوسط پیشبینیها ۱۰ درصد خطا دارند» یا «مدل توانسته ۶۰ درصد از تغییرات فروش را توضیح دهد»، میتواند تصویر واضحتری از میزان ریسک و قابلیت اتکای سیستم داشته باشد. بنابراین انتخاب معیار ارزیابی مناسب، مستقیماً بر کیفیت تصمیمهای فنی و اقتصادی اثر میگذارد.
جایگاه رگرسیون بهعنوان پایه علم داده و هوش مصنوعی
رگرسیون را میتوان یکی از سنگبنایهای علم داده دانست. بسیاری از مفاهیم کلیدی در یادگیری ماشین، از جمله خطا، برازش مدل، بیشبرازش (Overfitting)، کمبرازش (Underfitting) و حتی روشهای بهینهسازی، ریشه در تحلیلهای رگرسیونی دارند. به همین دلیل، درک درست از ارزیابی مدلهای رگرسیونی نهتنها برای پروژههای عملی، بلکه برای فهم عمیقتر سایر حوزههای هوش مصنوعی نیز ضروری است.
۲. رگرسیون چیست و چه زمانی از آن استفاده میکنیم؟
تعریف رگرسیون در یادگیری ماشین
در سادهترین تعریف، رگرسیون مجموعهای از الگوریتمها و روشها در یادگیری ماشین است که هدف آنها پیشبینی یک مقدار عددی پیوسته بر اساس مجموعهای از ویژگیهای ورودی است. در رگرسیون، خروجی مدل یک عدد واقعی است، نه یک برچسب یا کلاس مشخص.
برای مثال، اگر بخواهیم قیمت یک خانه را بر اساس متراژ، تعداد اتاقها، موقعیت جغرافیایی و سال ساخت پیشبینی کنیم، با یک مسئله رگرسیونی روبهرو هستیم. مدل تلاش میکند رابطهای (خطی یا غیرخطی) میان ویژگیها و مقدار هدف پیدا کند تا بتواند برای دادههای جدید نیز پیشبینی انجام دهد.
تفاوت خروجیهای عددی پیوسته با مسائل طبقهبندی
یکی از اشتباهات رایج در ابتدای یادگیری ماشین، عدم تفکیک دقیق بین رگرسیون و طبقهبندی است. در مسائل طبقهبندی، خروجی مدل یک کلاس یا دسته مشخص است؛ مانند تشخیص اسپم یا غیر اسپم بودن ایمیل، یا سالم و ناسالم بودن یک قطعه صنعتی. اما در رگرسیون، خروجی میتواند هر عددی در یک بازه پیوسته باشد.
این تفاوت ماهوی باعث میشود معیارهای ارزیابی این دو نوع مسئله کاملاً متفاوت باشند. در حالی که در طبقهبندی از معیارهایی مانند دقت (Accuracy)، فراخوانی (Recall) یا F1-score استفاده میشود، در رگرسیون تمرکز اصلی بر میزان فاصله عددی پیشبینیها از مقادیر واقعی است.
نمونههایی از کاربردهای واقعی رگرسیون
کاربردهای رگرسیون در دنیای واقعی بسیار گستردهاند. پیشبینی قیمت مسکن یکی از شناختهشدهترین مثالهاست، اما محدود به آن نیست. پیشبینی فروش ماه آینده، تخمین تقاضای مشتریان، پیشبینی مصرف انرژی، پیشبینی دما یا بارندگی، و حتی برآورد زمان تحویل پروژهها، همگی نمونههایی از کاربردهای رگرسیونی هستند. در تمام این موارد، کیفیت تصمیم نهایی به شدت وابسته به دقت ارزیابی مدل رگرسیونی است.
۳. مفاهیم پایه در ارزیابی مدلهای رگرسیونی
۳.۱ مقدار واقعی (True Value) و مقدار پیشبینیشده (Predicted Value)
در هر مسئله رگرسیونی، دو مجموعه مقدار نقش کلیدی دارند. نخست، مقادیر واقعی که همان دادههای مشاهدهشده یا برچسبهای واقعی هستند. دوم، مقادیر پیشبینیشده که خروجی مدل یادگیری ماشین محسوب میشوند.
ارزیابی مدل در واقع فرآیند مقایسه این دو مجموعه است. هرچه اختلاف بین مقدار واقعی و مقدار پیشبینیشده کمتر باشد، مدل عملکرد بهتری داشته است. تمام معیارهای ارزیابی رگرسیون، بهنوعی تلاش میکنند این اختلاف را به شکل عددی و قابل مقایسه بیان کنند.
۳.۲ باقیمانده (Residual) و نقش آن در محاسبه خطا
مفهوم باقیمانده یا Residual یکی از اساسیترین مفاهیم در ارزیابی مدلهای رگرسیونی است. باقیمانده، اختلاف بین مقدار واقعی و مقدار پیشبینیشده برای هر مشاهده است.
فرمول محاسبه Residual:
باقیمانده = مقدار واقعی − مقدار پیشبینیشده
اگر مقدار پیشبینیشده کمتر از مقدار واقعی باشد، باقیمانده مثبت خواهد بود و اگر بیشتر باشد، باقیمانده منفی میشود. بررسی الگوی باقیماندهها اطلاعات بسیار ارزشمندی درباره رفتار مدل در اختیار ما قرار میدهد.
تفسیر بصری خطا در مدلهای رگرسیونی
در نمایشهای بصری، باقیماندهها معمولاً بهصورت فاصله عمودی بین نقاط واقعی داده و خط یا منحنی پیشبینیشده مدل نمایش داده میشوند. اگر این فاصلهها بهصورت تصادفی و بدون الگوی خاصی توزیع شده باشند، نشاندهنده عملکرد مناسب مدل است. اما اگر الگوهای مشخصی در باقیماندهها دیده شود، میتواند نشانهای از ضعف مدل یا انتخاب نادرست ویژگیها باشد.
۴. معرفی معیارهای رایج ارزیابی رگرسیون
دستهبندی معیارها (مقیاسوابسته و مقیاسمستقل)
معیارهای ارزیابی رگرسیون را میتوان بهطور کلی به دو دسته تقسیم کرد: معیارهای مقیاسوابسته و معیارهای مقیاسمستقل. معیارهای مقیاسوابسته، خطا را در همان واحد متغیر هدف بیان میکنند یا به آن وابستهاند؛ مانند MAE، MSE و RMSE. این معیارها برای درک مستقیم میزان خطا بسیار مفید هستند، اما مقایسه آنها بین دادههایی با مقیاس متفاوت دشوار است.
در مقابل، معیارهای مقیاسمستقل مانند MAPE یا R² تلاش میکنند عملکرد مدل را بهصورت نسبی یا درصدی بیان کنند. این معیارها برای گزارشدهی و مقایسه بین سناریوهای مختلف کاربرد بیشتری دارند، اما هرکدام محدودیتهای خاص خود را نیز دارند.

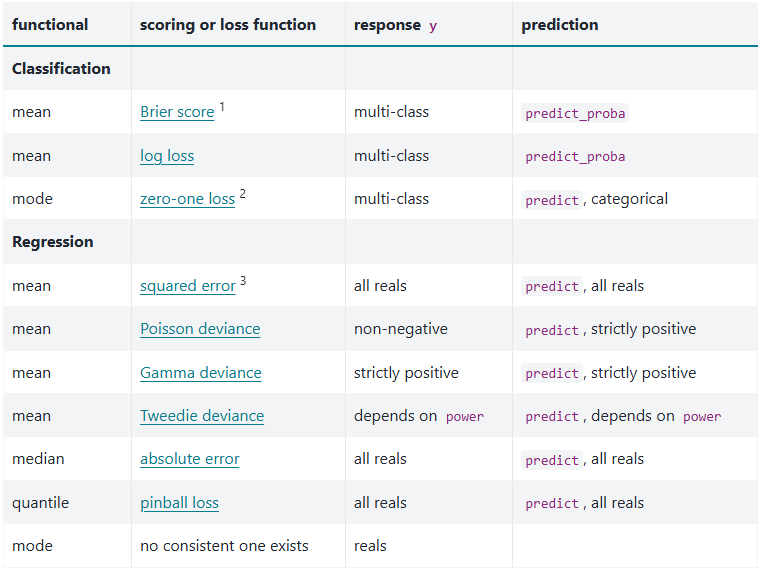
مزایا و محدودیت استفاده از هر گروه
هیچ معیار واحدی وجود ندارد که در تمام شرایط بهترین انتخاب باشد. معیارهای مقیاسوابسته تفسیر سادهتری دارند اما نسبت به دادههای پرت حساساند. معیارهای مقیاسمستقل قابل مقایسهتر هستند اما گاهی رفتار غیرمنتظرهای در شرایط خاص نشان میدهند. به همین دلیل، در عمل معمولاً از ترکیبی از چند معیار برای ارزیابی جامع مدلهای رگرسیونی استفاده میشود.
۵. خطای بایاس (Bias) و میانگین خطای بایاس (MBE)
تعریف بایاس در پیشبینی
بایاس به تمایل سیستماتیک مدل برای بیشبرآورد یا کمبرآورد مقادیر واقعی اشاره دارد. اگر یک مدل بهطور مداوم مقادیر بزرگتر از واقعیت پیشبینی کند، دچار بایاس مثبت است و اگر معمولاً کمتر از مقدار واقعی پیشبینی کند، بایاس منفی دارد.
یکی از سادهترین روشهای سنجش بایاس، محاسبه مجموع یا میانگین باقیماندههاست که به آن میانگین خطای بایاس (Mean Bias Error یا MBE) گفته میشود.
چرا بایاس پایین الزاماً به معنی مدل خوب نیست؟
نکته بسیار مهم این است که بایاس نزدیک به صفر لزوماً به معنی عملکرد خوب مدل نیست. ممکن است یک مدل خطاهای بسیار بزرگی داشته باشد، اما چون خطاهای مثبت و منفی یکدیگر را خنثی میکنند، بایاس کلی آن نزدیک به صفر شود. در چنین حالتی، مدل از نظر آماری بدون بایاس به نظر میرسد، اما از نظر دقت عملی کاملاً نامناسب است.
به همین دلیل، بایاس باید همواره در کنار سایر معیارهای ارزیابی مانند MAE یا MSE بررسی شود. بایاس بیشتر نشان میدهد مدل به کدام سمت خطا تمایل دارد، نه اینکه چقدر دقیق است.
۶. ضریب تعیین (R-squared یا R²)
۶.۱ تعریف و تفسیر R²
ضریب تعیین یا R-squared (R²) یکی از شناختهشدهترین و پرکاربردترین معیارهای ارزیابی مدلهای رگرسیونی است. این معیار نشان میدهد که چه نسبتی از تغییرات متغیر هدف توسط مدل توضیح داده میشود. به بیان ساده، R² بیان میکند که مدل ما تا چه حد توانسته رفتار دادههای واقعی را توضیح دهد.
برای مثال، اگر مقدار R² برابر با ۰.۶ باشد، به این معناست که مدل توانسته حدود ۶۰ درصد از واریانس متغیر هدف را توضیح دهد و ۴۰ درصد باقیمانده به عواملی مربوط میشود که مدل قادر به توضیح آنها نبوده است. به همین دلیل، R² اغلب بهعنوان شاخصی از «قدرت توضیحدهندگی» مدل شناخته میشود.
با این حال، باید توجه داشت که R² لزوماً به معنای دقت بالا در پیشبینی نیست، بلکه بیشتر بیانگر میزان تطابق کلی مدل با دادههاست.
۶.۲ فرمول و اجزای تشکیلدهنده (RSS و TSS)
فرمول استاندارد محاسبه R² به شکل زیر است:
R² = 1 − (RSS / TSS)
در این فرمول، دو مؤلفه اصلی نقش کلیدی دارند:
- RSS (Residual Sum of Squares) یا مجموع مربعات باقیماندهها:
این مقدار نشاندهنده مجموع خطاهای مدل است و از جمع مربعات اختلاف بین مقادیر واقعی و مقادیر پیشبینیشده بهدست میآید. هرچه RSS کوچکتر باشد، مدل خطای کمتری دارد. - TSS (Total Sum of Squares) یا مجموع مربعات کل:
این مقدار نشاندهنده کل واریانس موجود در دادههای هدف است و بر اساس اختلاف هر مقدار واقعی از میانگین کل دادهها محاسبه میشود. TSS بیان میکند که اگر هیچ مدلی نداشتیم و فقط از میانگین استفاده میکردیم، چقدر خطا داشتیم.
در واقع، R² مقایسهای است میان عملکرد مدل و یک مدل پایه بسیار ساده که همیشه میانگین را پیشبینی میکند. اگر مدل ما بهتر از این حالت پایه عمل کند، R² مثبت خواهد بود.
۶.۳ ویژگیها و محدودیتهای R²
یکی از مهمترین ویژگیهای R² این است که یک معیار نسبی محسوب میشود. یعنی تنها زمانی معنا دارد که برای مقایسه مدلهایی که روی یک دیتاست یکسان آموزش داده شدهاند استفاده شود. مقایسه R² بین دو مسئله متفاوت یا دو دیتاست با ماهیت متفاوت، معمولاً گمراهکننده است.
مقایسه مدلها
R² ابزار مناسبی برای مقایسه مدلهای مختلف روی یک مسئله واحد است. برای مثال، اگر دو مدل رگرسیونی روی یک مجموعه داده آموزش داده شوند، مدلی که R² بالاتری دارد، از نظر توضیح واریانس دادهها عملکرد بهتری داشته است. به همین دلیل، R² یکی از اولین معیارهایی است که در تحلیلهای اولیه مورد بررسی قرار میگیرد.
مشکل افزایش مصنوعی با افزودن ویژگیها
یکی از محدودیتهای مهم R² این است که در مدلهای خطی مبتنی بر روش حداقل مربعات معمولی (OLS)، با افزودن ویژگیهای جدید، مقدار R² هرگز کاهش نمییابد. حتی اگر ویژگی جدید هیچ اطلاعات مفیدی نداشته باشد، R² یا ثابت میماند یا اندکی افزایش پیدا میکند.
این ویژگی میتواند باعث ایجاد توهم بهبود مدل شود. مدلی که تعداد زیادی ویژگی بیارتباط دارد، ممکن است R² بالاتری نشان دهد، اما در عمل دچار بیشبرازش (Overfitting) شده باشد و روی دادههای جدید عملکرد ضعیفی داشته باشد.
۶.۴ R² تعدیلشده (Adjusted R²)
برای حل مشکل افزایش مصنوعی R²، معیار R² تعدیلشده (Adjusted R²) معرفی شده است. این معیار علاوه بر میزان خطا، تعداد ویژگیها و حجم دادهها را نیز در نظر میگیرد و برای افزودن ویژگیهای غیرمفید جریمه اعمال میکند.
اگر افزودن یک ویژگی جدید باعث بهبود واقعی مدل شود، مقدار Adjusted R² افزایش مییابد. اما اگر این ویژگی اطلاعات معناداری نداشته باشد، Adjusted R² کاهش پیدا میکند. به همین دلیل، R² تعدیلشده معیار مناسبتری برای مقایسه مدلهایی است که تعداد ویژگیهای متفاوتی دارند.
۶.۵ منفی شدن R² در مدلهای غیرخطی
در مدلهای خطی مبتنی بر OLS، مقدار R² معمولاً بین ۰ و ۱ قرار دارد. اما در مدلهای غیرخطی یا مدلهایی که فرآیند آموزش آنها مبتنی بر کمینهسازی RSS نیست، ممکن است R² منفی شود.
R² منفی به این معناست که مدل حتی از پیشبینی میانگین نیز بدتر عمل کرده است. در چنین شرایطی، مدل نهتنها مفید نیست، بلکه میتواند تصمیمگیری را گمراه کند. مشاهده R² منفی معمولاً نشانهای قوی از انتخاب نادرست مدل یا ویژگیهاست.
۷. میانگین مربعات خطا (Mean Squared Error – MSE)
تعریف و فرمول
میانگین مربعات خطا (MSE) یکی از رایجترین معیارهای ارزیابی در رگرسیون است. این معیار از میانگین مربعات اختلاف بین مقدار واقعی و مقدار پیشبینیشده بهدست میآید:
MSE = (1 / N) × Σ (y − ŷ)²
در این معیار، خطاها قبل از میانگینگیری به توان دو میرسند که تأثیر مهمی بر رفتار MSE دارد.
حساسیت به خطاهای بزرگ و دادههای پرت
به دلیل وجود توان دوم، MSE نسبت به خطاهای بزرگ بسیار حساس است. یک خطای بزرگ میتواند مقدار MSE را بهشدت افزایش دهد. این ویژگی در برخی کاربردها مفید است، زیرا خطاهای بزرگ را بهطور جدی جریمه میکند، اما در حضور دادههای پرت (Outliers) میتواند مشکلساز باشد.
نقش MSE در فرآیند بهینهسازی مدلها
یکی از دلایل محبوبیت MSE این است که یک معیار قابل مشتقگیری است. این ویژگی باعث میشود MSE بهطور گسترده بهعنوان تابع هزینه در الگوریتمهای یادگیری مبتنی بر گرادیان استفاده شود. بسیاری از مدلهای رگرسیونی در عمل مستقیماً MSE را کمینه میکنند، حتی اگر در مرحله گزارشدهی از معیارهای دیگری استفاده شود.
۸. ریشه میانگین مربعات خطا (Root Mean Squared Error – RMSE)
ارتباط RMSE با MSE
RMSE در واقع ریشه دوم MSE است:
RMSE = √MSE
این تبدیل باعث میشود که واحد RMSE با واحد متغیر هدف یکسان شود، در حالی که MSE دارای واحد مربعشده است.
تفسیر خطا در مقیاس متغیر هدف
یکی از مزایای اصلی RMSE این است که تفسیر آن برای انسان سادهتر است. وقتی میگوییم RMSE برابر با ۱۰ است، میتوان آن را بهطور تقریبی بهعنوان «اندازه خطای معمول مدل» در همان مقیاس دادهها در نظر گرفت. البته باید توجه داشت که RMSE میانگین خطای واقعی نیست، بلکه ریشه میانگین مربعات خطاست.
تفاوت مفهومی RMSE با «خطای میانگین واقعی»
اشتباه رایجی که وجود دارد این است که RMSE بهعنوان «میانگین خطا» تفسیر شود. در حالی که به دلیل توان دوم، RMSE بیشتر تحت تأثیر خطاهای بزرگ قرار دارد. بنابراین RMSE بیشتر نمایانگر شدت خطاها است تا مقدار متوسط آنها.
۹. میانگین قدرمطلق خطا (Mean Absolute Error – MAE)
تعریف و فرمول
MAE میانگین قدرمطلق اختلاف بین مقدار واقعی و مقدار پیشبینیشده است:
MAE = (1 / N) × Σ |y − ŷ|
در این معیار، جهت خطا (مثبت یا منفی بودن) نادیده گرفته میشود.
مقاومت در برابر دادههای پرت
برخلاف MSE و RMSE، MAE به دادههای پرت حساسیت کمتری دارد، زیرا خطاها به توان دو نمیرسند. هر خطا، صرفنظر از بزرگی آن، بهصورت خطی در محاسبه MAE اثر میگذارد. به همین دلیل، MAE در بسیاری از کاربردهای عملی که دادههای پرت اجتنابناپذیر هستند، معیار قابل اعتمادتری است.
ارتباط MAE با میانه (Median)
یکی از ویژگیهای جالب MAE این است که بهینهسازی MAE منجر به پیشبینی میانه دادهها میشود. این ویژگی باعث میشود MAE در سناریوهایی که توزیع داده نامتقارن است، رفتار منطقیتری نسبت به MSE داشته باشد.
محدودیتهای استفاده در الگوریتمهای گرادیانی
به دلیل وجود قدرمطلق، MAE در همه نقاط قابل مشتقگیری نیست. این مسئله استفاده مستقیم از MAE را بهعنوان تابع هزینه در برخی الگوریتمهای گرادیانی دشوار میکند. به همین دلیل، بسیاری از مدلها در مرحله آموزش از MSE استفاده میکنند، اما در ارزیابی نهایی MAE را گزارش میدهند.
۱۰. میانگین قدرمطلق خطای درصدی (MAPE)
تعریف و فرمول
MAPE میانگین قدرمطلق خطا را نسبت به مقدار واقعی و بهصورت درصد بیان میکند:
MAPE = (1 / N) × Σ |(y − ŷ) / y| × ۱۰۰
این معیار به دلیل بیان درصدی، برای مخاطبان غیر فنی بسیار قابل فهم است.
محبوبیت در کاربردهای تجاری
MAPE یکی از محبوبترین معیارها در فضای کسبوکار است، زیرا بهراحتی میتوان گفت «مدل ما بهطور متوسط X درصد خطا دارد». این ویژگی باعث شده MAPE در پیشبینی فروش، تقاضا و شاخصهای اقتصادی کاربرد گستردهای داشته باشد.
مشکلات MAPE
تقسیم بر صفر
اگر مقدار واقعی برابر با صفر باشد، MAPE تعریفنشده خواهد بود و در نزدیکی صفر نیز مقادیر بسیار بزرگی تولید میکند.
عدم تقارن در جریمه خطا
MAPE تمایل دارد بیشبرآورد را شدیدتر از کمبرآورد جریمه کند. این عدم تقارن میتواند مدل را به سمت پیشبینی کمتر از واقعیت سوق دهد.
وابستگی به صفر معنادار
MAPE تنها زمانی معنا دارد که متغیر هدف دارای صفر واقعی و معنادار باشد. در غیر این صورت، تفسیر درصدی خطا منطقی نخواهد بود.
مفهوم wMAPE و کاربرد آن
برای رفع برخی مشکلات MAPE، بهویژه در مسائل تجمیعی مانند پیشبینی فروش چند محصول، از wMAPE (Weighted MAPE) استفاده میشود. در این روش، خطاها بر اساس اهمیت یا حجم واقعی وزندهی میشوند تا خطاهای بزرگ در مقادیر مهمتر تأثیر بیشتری در ارزیابی نهایی داشته باشند.
۱۱. خطای درصدی متقارن (sMAPE)
انگیزه ایجاد sMAPE
یکی از انتقادهای جدی به معیار MAPE، عدم تقارن آن در جریمه خطاها و مشکل تقسیم بر صفر بود. بهطور مشخص، در MAPE خطای بیشبرآورد (Overestimation) معمولاً شدیدتر از کمبرآورد (Underestimation) جریمه میشود و همچنین در نزدیکی مقادیر صفر، مقدار خطا بهصورت انفجاری افزایش مییابد.
برای کاهش این مشکلات، معیار sMAPE (Symmetric Mean Absolute Percentage Error) معرفی شد. هدف اصلی sMAPE این بود که:
- خطاها را بهصورت متقارنتر جریمه کند
- وابستگی مستقیم به مقدار واقعی (y) را کاهش دهد
- در پیشبینیهای سری زمانی، بهویژه در اقتصاد و تقاضا، رفتاری پایدارتر نشان دهد
فرمول و دامنه مقادیر sMAPE
فرمول متداول sMAPE بهصورت زیر تعریف میشود:
sMAPE = (1 / N) × Σ [ |y − ŷ| / (|y| + |ŷ|) ] × ۲ × ۱۰۰
در این فرمول:
- قدرمطلق مقدار واقعی و مقدار پیشبینیشده در مخرج ظاهر میشوند
- ضریب ۲ برای نرمالسازی استفاده میشود
- نتیجه معمولاً بهصورت درصد بیان میشود
دامنه مقادیر sMAPE معمولاً بین ۰ تا ۲۰۰ درصد در نظر گرفته میشود (یا در برخی تعاریف بین ۰ تا ۱). این دامنه متفاوت یکی از دلایلی است که گاهی باعث سردرگمی در تفسیر این معیار میشود.
ایرادات مفهومی و محاسباتی sMAPE
با وجود نیت اولیه مثبت، sMAPE نیز بدون ایراد نیست. برخی از مهمترین مشکلات آن عبارتاند از:
- عدم تقارن واقعی
برخلاف نامش، sMAPE در بسیاری از سناریوها همچنان رفتاری کاملاً متقارن ندارد و بسته به مقدار y و ŷ، جریمهها متفاوت اعمال میشوند. - رفتار ناپایدار در مقادیر کوچک
اگر هر دو مقدار y و ŷ کوچک باشند، مخرج کسر بسیار کوچک میشود و نوسانات شدیدی در مقدار خطا ایجاد میکند. - تفسیر دشوار
برخلاف MAPE که مستقیماً به «درصد خطا نسبت به مقدار واقعی» اشاره دارد، تفسیر sMAPE برای کاربران غیر فنی دشوارتر است.
چرایی بحثبرانگیز بودن sMAPE در پیشبینی سری زمانی
در حوزه پیشبینی سریهای زمانی، بهویژه در رقابتها و مطالعات اقتصادی، sMAPE بارها مورد استفاده قرار گرفته است. با این حال، پژوهشهای متعدد نشان دادهاند که:
- sMAPE میتواند مدلها را به سمت کمبرآورد سیستماتیک سوق دهد
- در مقایسه با MAE یا RMSE، گاهی رتبهبندی متفاوت و گمراهکنندهای از مدلها ارائه میدهد
به همین دلیل، بسیاری از متخصصان توصیه میکنند sMAPE تنها در کنار سایر معیارها و نه بهعنوان معیار اصلی تصمیمگیری استفاده شود.
۱۲. سایر معیارهای مهم ارزیابی رگرسیون
۱۲.۱ Mean Squared Log Error (MSLE)
MSLE نسخه لگاریتمی MSE است و بهصورت زیر تعریف میشود:
MSLE = (1 / N) × Σ [ log(1 + y) − log(1 + ŷ) ]²
ویژگیهای کلیدی MSLE:
- خطاهای نسبی را بهتر از خطاهای مطلق منعکس میکند
- به خطاهای بزرگ در مقیاسهای بزرگ حساسیت کمتری دارد
- بیشبرآورد و کمبرآورد را بهصورت نامتقارن جریمه میکند (بیشبرآورد شدیدتر جریمه میشود)
MSLE برای مسائلی مناسب است که متغیر هدف:
- همیشه غیرمنفی باشد
- رشد نمایی یا مقیاسهای بزرگ داشته باشد (مانند جمعیت، فروش، تعداد کاربران)
۱۲.۲ Root Mean Squared Log Error (RMSLE)
RMSLE ریشه دوم MSLE است و همانند رابطه RMSE با MSE، باعث بازگشت مقیاس خطا به واحد لگاریتمی میشود.
مزیت اصلی RMSLE این است که:
- تفاوت نسبی بین پیشبینیها را بهتر نشان میدهد
- خطاهای بزرگ در مقادیر بالا را تعدیل میکند
- برای مقایسه نرخ رشد پیشبینیشده با نرخ رشد واقعی مناسبتر است
در بسیاری از مسائل تجاری، RMSLE نسبت به RMSE معیار منطقیتری محسوب میشود، بهویژه زمانی که چند برابر شدن مقدار هدف اهمیت بیشتری از اختلاف مطلق دارد.
۱۲.۳ معیارهای اطلاعاتی: AIC و BIC
برخلاف معیارهای قبلی که مستقیماً بر خطای پیشبینی تمرکز داشتند، AIC (Akaike Information Criterion) و BIC (Bayesian Information Criterion) رویکرد متفاوتی دارند.
این معیارها بر اساس ایده «توازن بین برازش مدل و پیچیدگی آن» تعریف شدهاند. بهعبارت دیگر، مدل خوب مدلی است که:
- خطای کمی داشته باشد
- اما بیش از حد پیچیده نباشد
AIC و BIC هر دو شامل دو بخش هستند:
- بخشی مرتبط با میزان خطا یا لاگلایکلیهود
- بخشی بهعنوان جریمه برای تعداد پارامترها
تفاوت اصلی این دو معیار در شدت جریمه پیچیدگی است؛ BIC مدلهای پیچیده را شدیدتر جریمه میکند و معمولاً مدلهای سادهتر را ترجیح میدهد.
۱۳. مقایسه عملی معیارهای ارزیابی با مثال عددی
بررسی چند سناریوی پیشبینی با خطای یکسان
فرض کنید دو مدل داریم که مجموع خطای مطلق آنها برابر است. از نگاه MAE، این دو مدل عملکردی یکسان دارند. اما وقتی MSE یا RMSE را محاسبه میکنیم، مدلی که یک خطای بزرگ و چند خطای کوچک دارد، بهشدت جریمه میشود.
این مثال نشان میدهد که:
- MAE به توزیع خطاها اهمیت کمتری میدهد
- MSE و RMSE به خطاهای شدید بسیار حساس هستند
تفاوت واکنش MSE، MAE، MAPE و sMAPE
- MSE/RMSE: تمرکز بر شدت خطا، مناسب برای سناریوهای حساس
- MAE: تمرکز بر خطای معمول، مقاوم در برابر دادههای پرت
- MAPE: تفسیرپذیر برای کسبوکار، اما وابسته به صفر معنادار
- sMAPE: تلاش برای نرمالسازی درصدی، اما بحثبرانگیز
انتخاب معیار بهشدت وابسته به هدف مسئله است، نه صرفاً یک «عدد بهتر».
تحلیل رفتار معیارها در مواجهه با خطاهای شدید
در حضور یک خطای بسیار بزرگ:
- MSE و RMSE بهشدت افزایش مییابند
- MAE افزایش خطی دارد
- MAPE ممکن است بهصورت انفجاری بزرگ شود
- sMAPE رفتاری غیرقابل پیشبینی از خود نشان دهد
این تفاوتها دلیل اصلی توصیه متخصصان به استفاده همزمان از چند معیار است.
۱۴. استفاده از معیارهای رگرسیون در کتابخانه Scikit-Learn
۱۴.۱ معرفی متریکهای رگرسیون در scikit-learn
کتابخانه scikit-learn مجموعهای کامل از متریکهای رگرسیون را در ماژول metrics ارائه میدهد. این متریکها شامل:
mean_absolute_errormean_squared_errorr2_scoremean_squared_log_error
هستند که بهصورت استاندارد و قابل اعتماد پیادهسازی شدهاند.
۱۴.۲ محاسبه MAE، MSE، R² و RMSE با کد پایتون
در scikit-learn، محاسبه این معیارها بسیار ساده است. کافی است مقادیر واقعی و پیشبینیشده را به توابع مربوطه بدهیم. برای RMSE معمولاً از ریشه دوم MSE استفاده میشود، زیرا تابع جداگانهای برای آن وجود ندارد.
این سادگی باعث شده scikit-learn به ابزار اصلی ارزیابی مدلها در پروژههای عملی یادگیری ماشین تبدیل شود.
۱۵. مثال عملی: ارزیابی مدل رگرسیون روی دیتاست قیمت مسکن کالیفرنیا
۱۵.۱ بارگذاری دیتاست
دیتاست California Housing یکی از دیتاستهای کلاسیک برای آموزش و ارزیابی مدلهای رگرسیونی است. این دیتاست شامل ویژگیهایی مانند:
- درآمد متوسط منطقه
- تعداد اتاقها
- تراکم جمعیت
و متغیر هدف آن، قیمت متوسط مسکن است.
۱۵.۲ تقسیم دادهها به آموزش و تست
برای ارزیابی منصفانه مدل، دادهها به دو بخش آموزش و تست تقسیم میشوند. این کار کمک میکند عملکرد مدل روی دادههای دیدهنشده بررسی شود و خطر بیشبرازش کاهش یابد.
۱۵.۳ آموزش مدل رگرسیون خطی
در این مثال، از یک مدل رگرسیون خطی ساده استفاده میشود. هدف، نمایش نحوه محاسبه و تفسیر معیارهاست، نه دستیابی به بهترین عملکرد ممکن.
۱۵.۴ محاسبه و تفسیر نتایج معیارها
پس از آموزش مدل و پیشبینی روی دادههای تست:
- R² نشان میدهد مدل چه مقدار از واریانس قیمت مسکن را توضیح داده است
- MAE اندازه خطای معمول پیشبینی را بیان میکند
- RMSE شدت خطاهای بزرگ را آشکار میسازد
تحلیل همزمان این معیارها تصویری جامع از کیفیت مدل ارائه میدهد و نشان میدهد چرا تکیه بر یک معیار واحد میتواند گمراهکننده باشد.
۱۶. چگونه معیار مناسب را انتخاب کنیم؟
انتخاب معیار ارزیابی در مدلهای رگرسیونی، برخلاف تصور رایج، یک تصمیم صرفاً فنی نیست. این انتخاب، مستقیماً بر رفتار مدل، نوع بهینهسازی، تفسیر نتایج و حتی تصمیمهای تجاری و مدیریتی اثر میگذارد. بسیاری از پروژههای هوش مصنوعی نه به دلیل ضعف مدل، بلکه به دلیل انتخاب نادرست معیار ارزیابی با شکست مواجه میشوند.
در این بخش، به مهمترین ابعاد تصمیمگیری برای انتخاب معیار مناسب میپردازیم.
تأثیر دادههای پرت (Outliers) بر انتخاب معیار
یکی از اولین سؤالاتی که باید پیش از انتخاب معیار از خود بپرسیم این است:
آیا دادههای ما دارای مقادیر پرت هستند یا خیر؟
دادههای پرت میتوانند ناشی از:
- خطای اندازهگیری
- رویدادهای نادر اما واقعی
- تغییرات ساختاری در سیستم
باشند. نوع معیار انتخابشده تعیین میکند که مدل چگونه به این دادهها واکنش نشان دهد.
- معیارهایی مانند MSE و RMSE بهشدت به دادههای پرت حساساند. یک خطای بزرگ میتواند مقدار این معیارها را بهطور چشمگیری افزایش دهد.
- در مقابل، MAE رفتاری خطی دارد و اثر دادههای پرت بر آن محدودتر است.
اگر دادههای پرت برای شما مهم و معنادار هستند (مثلاً زیانهای مالی شدید اما نادر)، استفاده از RMSE میتواند منطقی باشد. اما اگر این دادهها بیشتر ناشی از نویز یا خطا هستند، MAE یا حتی معیارهای مقاومتر انتخاب بهتری خواهند بود.
ترجیح تجاری به بیشبرآورد یا کمبرآورد
در بسیاری از مسائل واقعی، خطاها متقارن نیستند. یعنی:
- بیشبرآورد (Overestimation) و کمبرآورد (Underestimation)
- پیامدهای یکسانی ندارند
برای مثال:
- در پیشبینی تقاضا، بیشبرآورد میتواند منجر به انبار مازاد شود
- کمبرآورد میتواند به از دست رفتن فروش و نارضایتی مشتری منجر شود
برخی معیارها بهطور ذاتی این عدم تقارن را نادیده میگیرند. اما در عمل، شما باید معیار یا تابع هزینهای را انتخاب کنید که با اولویت تجاری شما همراستا باشد.
در چنین شرایطی:
- معیارهایی مانند MBE (میانگین خطای بایاس) میتوانند جهت خطا را آشکار کنند
- استفاده همزمان از چند معیار کمک میکند بفهمیم مدل تمایل به بیشبرآورد دارد یا کمبرآورد
نکته کلیدی این است که «دقیقترین مدل» لزوماً «بهترین مدل برای کسبوکار» نیست.
انتخاب معیار وابسته به مقیاس یا مستقل از مقیاس
یکی دیگر از تصمیمهای مهم، انتخاب بین معیارهای مقیاسوابسته و مقیاسمستقل است.
- معیارهای مقیاسوابسته مانند MAE، MSE و RMSE مستقیماً به واحد متغیر هدف وابستهاند.
- معیارهای مقیاسمستقل مانند R²، MAPE و sMAPE امکان مقایسه بین مسائل مختلف را فراهم میکنند.
اگر هدف شما:
- تحلیل دقیق یک مسئله خاص با واحد مشخص (مثلاً دلار، متر، کیلوگرم) است → معیارهای مقیاسوابسته مناسبترند
- مقایسه چند مدل یا چند مسئله با مقیاسهای متفاوت است → معیارهای مقیاسمستقل کاربرد بیشتری دارند
با این حال، معیارهای مقیاسمستقل نیز محدودیتهای خاص خود را دارند و همیشه قابل اتکا نیستند.
تفاوت معیار بهینهسازی و معیار گزارشدهی
یکی از اشتباهات رایج در پروژههای یادگیری ماشین، یکی دانستن معیار بهینهسازی (Loss Function) با معیار گزارشدهی (Evaluation Metric) است.
در عمل:
- بسیاری از الگوریتمها با MSE یا مشتقات آن آموزش داده میشوند
- اما نتایج نهایی با MAE، RMSE یا حتی MAPE گزارش میشوند
دلیل این تفاوت آن است که:
- معیارهای بهینهسازی باید از نظر ریاضی برای الگوریتم مناسب باشند (مثلاً مشتقپذیر بودن)
- معیارهای گزارشدهی باید از نظر انسانی و تجاری قابل تفسیر باشند
برای مثال:
- MAE برای گزارش به مدیران بسیار قابل فهمتر از MSE است
- اما MSE برای الگوریتمهای گرادیانی گزینه مناسبتری برای آموزش است
درک این تفاوت، یکی از نشانههای بلوغ فکری در طراحی سیستمهای یادگیری ماشین است.
رویکرد پیشنهادی: استفاده همزمان از چند معیار
بهجای جستجوی «یک معیار طلایی»، رویکرد حرفهای این است که:
- یک معیار اصلی برای بهینهسازی
- چند معیار مکمل برای تحلیل و گزارش
انتخاب شود. این کار:
- نقاط ضعف هر معیار را پوشش میدهد
- تصویر کاملتری از عملکرد مدل ارائه میکند
- احتمال تصمیمگیری اشتباه را کاهش میدهد
۱۷. جمعبندی نهایی
هیچ معیار «بهترین مطلق» وجود ندارد
یکی از مهمترین پیامهای این مقاله این است که:
هیچ معیار ارزیابیای وجود ندارد که در همه شرایط بهترین باشد.
هر معیار:
- فرضهای خاص خود را دارد
- نوع خاصی از خطا را برجسته میکند
- رفتار خاصی را به مدل تحمیل میکند
بنابراین، انتخاب معیار بدون درک این فرضها، میتواند به نتایج گمراهکننده منجر شود؛ حتی اگر مدل از نظر عددی «عملکرد خوبی» داشته باشد.
اهمیت درک عمیق پیامدهای هر معیار
اعداد بدون تفسیر، خطرناکاند. یک عدد خوب در R² یا RMSE لزوماً به معنای:
- تصمیم بهتر
- سود بیشتر
- رضایت کاربران
نیست. تنها زمانی میتوان به یک معیار اعتماد کرد که:
- بدانیم دقیقاً چه چیزی را اندازهگیری میکند
- بدانیم چه چیزی را پنهان میکند
- و بدانیم چگونه بر رفتار مدل اثر میگذارد
این درک عمیق، مرز بین «اجرای الگوریتم» و «مهندسی هوش مصنوعی» است.
نقش معیارهای ارزیابی در ارتباط با ذینفعان غیر فنی
در نهایت، مدلهای یادگیری ماشین در خلأ تصمیمگیری نمیشوند. مدیران، سرمایهگذاران، مشتریان و سیاستگذاران، همگی ذینفع این مدلها هستند.
انتخاب معیار مناسب و ترجمه درست آن به زبان غیر فنی:
- اعتماد ایجاد میکند
- تصمیمگیری را تسهیل میکند
- از سوءبرداشت و انتظارات نادرست جلوگیری میکند
گاهی موفقیت یک پروژه هوش مصنوعی، نه به دقت مدل، بلکه به توانایی تیم در توضیح درست معیارها وابسته است.
سخن پایانی
ارزیابی مدلهای رگرسیونی، قلب تپنده یادگیری ماشین کاربردی است. معیارها تنها ابزار سنجش نیستند؛ آنها زبان گفتوگوی ما با داده، مدل و کسبوکار هستند.
اگر این زبان را درست انتخاب و درست تفسیر کنیم، هوش مصنوعی به ابزاری قدرتمند برای تصمیمسازی تبدیل میشود. در غیر این صورت، حتی پیشرفتهترین مدلها نیز میتوانند ما را به مسیرهای اشتباه هدایت کنند.